本文主要是介绍论文阅读以及复现:Shuffle and learn: Unsupervised learning using temporal order verification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Summary
Details
1、Frame Sampling Strategy
2、Training & Testing
2.1 Training Details
2.1 Testing Details (Details for Action Recognition)
复现过程中遇到的问题
论文名称:Shuffle and learn: Unsupervised learning using temporal order verification(2016 ECCV)
下载地址:https://arxiv.org/pdf/1603.08561.pdf
原作者 Caffe 代码:https://github.com/imisra/shuffle-tuple
我的 PyTorch 复现代码:https://github.com/BizhuWu/ShuffleAndLearn_PyTorch
Summary
这篇文章是一个视频动作识别领域中设计自监督学习上游任务(pretext task)的文章:
它通过从在视频中采样三帧图片(a-b-c),分别丢进三个共享权值的类 AlexNet 网络中,将从 fc7 层出来的特征 concat 起来,最后经过 fc8 做一个二分类:是正确顺序(a-b-c 或者 c-b-a【注意反序也算对】)/ 不是正确顺序(除了两种)。
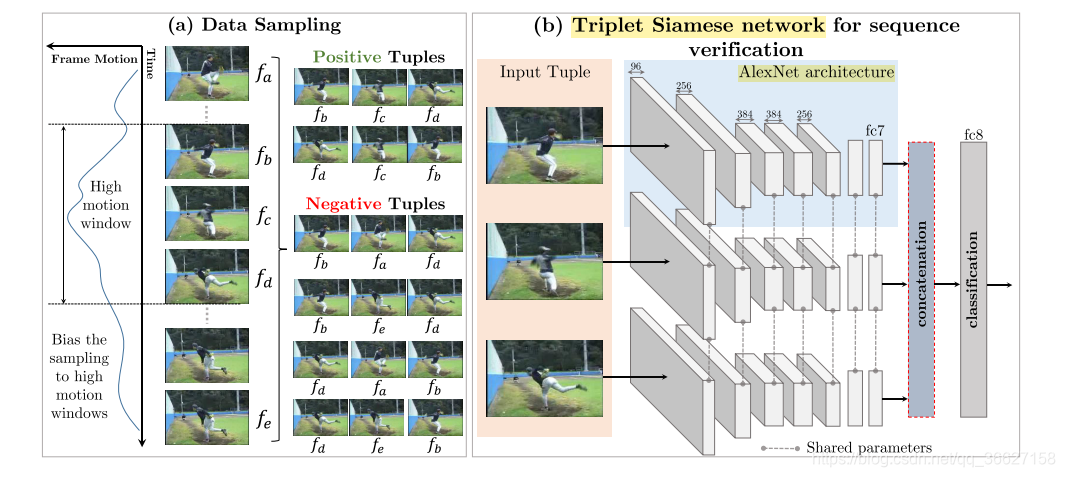
惊叹一下:原本我以为 temporal order verification 的单位是 video clips,所以 backbone 之类的应该是 C3D 之类的;万万没想到是 temporal order verification 的单位是 frames,所以 backbone 之类的应该是 AlexNet 的变体。
Details
1、Frame Sampling Strategy
- we only sample tuples from temporal windows with high motion.
- we use coarse frame level optical flow [56] as a proxy to measure the motion between frames. We treat the average flow magnitude per-frame as a weight for that frame, and use it to bias our sampling towards high motion windows.
- To create positive and negative tuples, we sample five frames (fa, fb, fc, fd, fe) from a temporal window such that a < b < c < d < e. Positive instances are created using (fb, fc, fd), while negative instances are created using (fb, fa, fd) and (fb, fe, fd). Additional training examples are also created by inverting the order of all training instances, eg., (fd, fc, fb) is positive.
- During training it is critical to use the same beginning frame fb and ending frame fd while only changing the middle frame for both positive and negative examples.
- To avoid sampling ambiguous negative frames fa and fe, we enforce that the appearance of the positive fc frame is not too similar (measured by SSD on RGB pixel values) to fa or fe.
这是作者给出的采样好的 tuple frames 和对应的 label(0 / 1)。可以在这里下载:here.
Each line of the file train01_image_keys.txt defines a tuple of three frames.
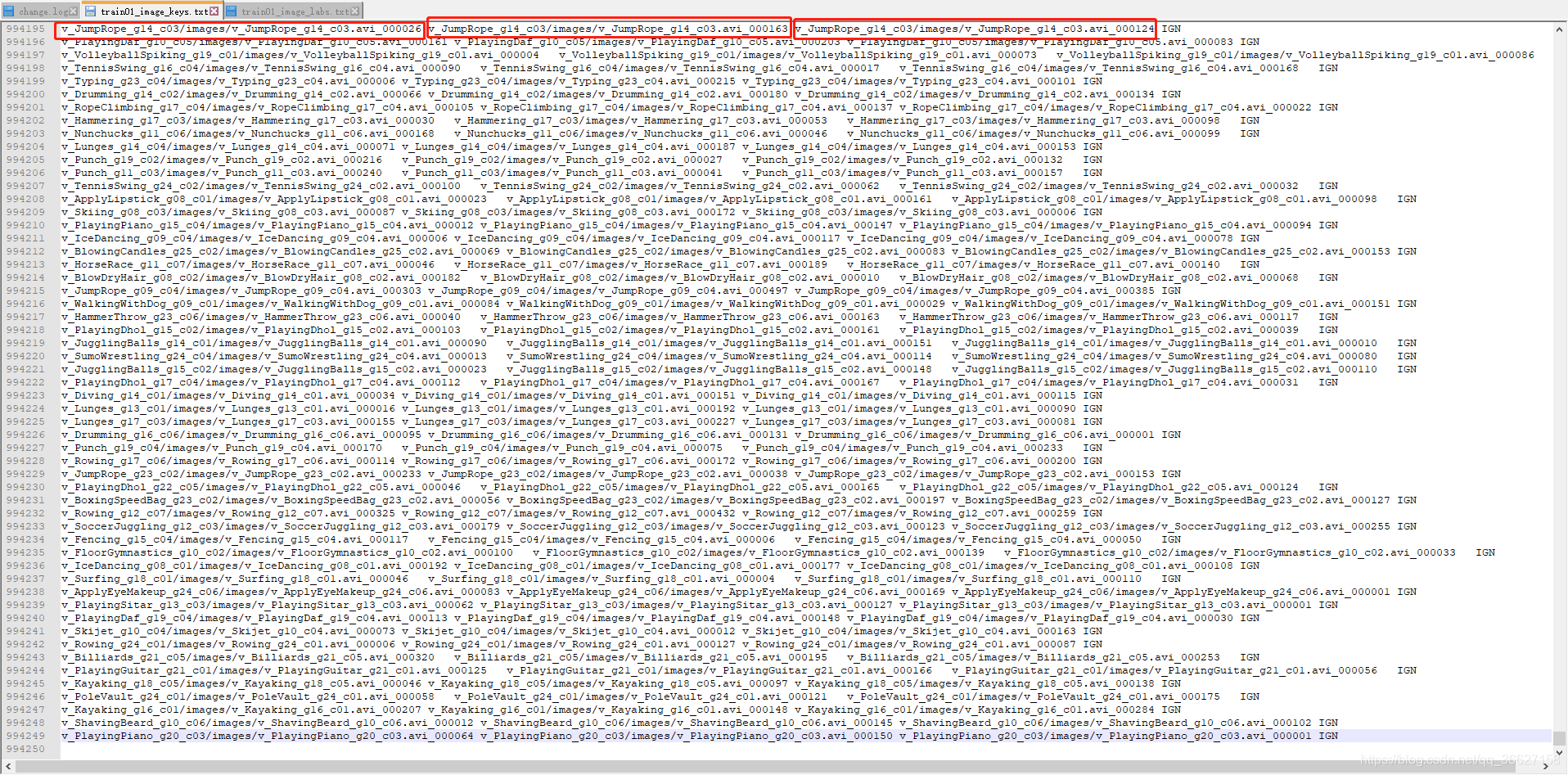
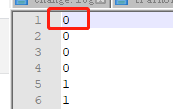
The corresponding file train01_image_labs.txt has a binary label indicating whether the tuple is in the correct or incorrect order.
2、Training & Testing
- To learn a feature representation from the tuple ordering task, we use a simple triplet Siamese network. This network has three parallel stacks of layers with shared parameters. Every network stack follows the standard CaffeNet [57] (a slight modification of AlexNet [58]) architecture from the conv1 to the fc7 layer.
- Each stack takes as input one of the frames from the tuple and produces a representation at the fc7 layer. The three fc7 outputs are concatenated as input to a linear classification layer.
- We update the parameters of the network by minimizing the regularized cross-entropy loss of the predictions on each tuple.
- During testing we can obtain the conv1 to fc7 representations of a single input frame by using just one stack, as the parameters across the three stacks are shared.
2.1 Training Details
- For unsupervised pre-training, we do not use the semantic action labels.
- We sample about 900k tuples from the UCF101 training videos.
- We randomly initialize our network, and train for 100k iterations with a fixed learning rate of 10^−3 and mini-batch size of 128 tuples.
- Each tuple consists of 3 frames
2.1 Testing Details (Details for Action Recognition)
- backbone 用的是 Two-stream 那一篇中的 RGB apperance 那一个 branch
- The parameters of the spatial network are initialized with our unsupervised pre-trained network.
- At test time, 25 frames are uniformly sampled from each video.
- Each frame is used to generate 10 inputs after fixed cropping and flipping (5 crops × 2 flips), and the prediction for the video is an average of the predictions across these 25×10 inputs.
- We initialize the network parameters up to the fc7 layer using the parameters from the unsupervised pre-trained network, and initialize a new fc8 layer for the action recognition task.
- We finetune the network following [60] for 20k iterations with a batch size of 256, and learning rate of 10^−2 decaying by 10 after 14k iterations, using SGD with momentum of 0.9, and dropout of 0.5.
复现过程中遇到的问题
注意!!!UCF101 数据集中 HandstandPushups 那一个类的文件名为 HandstandPushups,而里面视频的名字是 HandStandPushups,这里数据处理容易出错
这篇关于论文阅读以及复现:Shuffle and learn: Unsupervised learning using temporal order verification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
