本文主要是介绍GCF:在线市场异质治疗效果估计的广义因果森林,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
英文题目:GCF: Generalized Causal Forest for Heterogeneous Treatment Effects Estimation in Online Marketplace
中文题目:GCF:在线市场异质治疗效果估计的广义因果森林
单位:滴滴&美团
时间:2022
论文链接:https://arxiv.org/pdf/2203.10975.pdf
代码:GitHub - ehkennedy/npcausal
(该软件包提供了多种工具,可用于在各种设置中对因果关系进行非参数估计。这些方法基于影响函数理论,可以结合灵活的机器学习和高维回归工具,同时仍以置信区间和假设检验的形式产生推理。许多方法都倍加健壮。)
摘要:
提升建模是一种快速增长的方法,它利用因果推理和机器学习方法直接估计异质治疗效果,近年来被广泛应用于各种在线市场来辅助大规模决策。现有的流行模型,如因果森林(CF),仅限于离散处理,或者对可能存在模型错误指定的结果处理关系提出参数假设。然而,连续处理(例如价格、持续时间)经常出现在市场中。为了缓解这些限制,我们使用基于核的双鲁棒估计器来恢复能够灵活建模连续治疗效果的非参数剂量响应函数。此外,我们提出了一种通用的基于距离的分裂准则来捕捉连续处理的异质性。我们将所提出的算法称为广义因果森林 (GCF),因为它将 CF 的用例推广到更广泛的设置。我们通过推导估计器的渐近性质并将其与合成数据集和真实数据集上流行的提升建模方法进行比较,证明了GCF的有效性。我们在Spark上实现了GCF,并在领先的拼车公司成功地将GCF部署到大规模在线定价系统中。在线 A/B 测试结果进一步验证了 GCF 的优越性。

关键词:效应估计、连续处理、提升建模、在线市场
1引言
DiDi、Uber 和 Lyft 等拼车平台的兴起有助于为乘客提供方便的移动服务,并为司机提供灵活的工作机会。然而,鉴于这种双边市场的高度动态性质,拼车平台有效地平衡需求和供应是非常具有挑战性的。例如,在短时间内,给定区域中空闲驱动程序的数量可以看作是一个常数,因为车辆重新定位需要时间。另一方面,由于价格的变化、ETA的干扰和道路拥堵的严重程度等各种原因,乘客的请求很容易转移。因此,调整需求是拼车平台策略的核心,经常引起更多的关注[19,26]。等待时间较长,此后损害了乘客的经验,恶化了市场的效率。在翻转方面,如果激励不够强,那么刺激足够的请求来平衡同一ODT上的空闲驱动程序可能是不够的。只有当准确估计需求价格曲线时,才能获得最佳折扣。然而,曲线在不同的 ODT 中可能存在显着差异。
例如,在图 2 中,我们展示了需求如何随着不同 ODT 的价格而变化。因此,不同 ODT 的相同折扣几乎没有意义。换句话说,平台应该通过利用 ODT 的特定信息和实时供需关系相应地为 ODT 分配适当的折扣,以识别折扣对需求曲线的影响。

更一般地说,问题是如何估计不同场景下对需求的折扣效应,正式描述为因果推理领域异质治疗效果(HTE)估计的问题,这对决策者在广泛的背景下的兴趣越来越大。它揭示了干预对亚组水平的影响,从而提供了高度量身定制的建议,而不是一刀切的策略。此外,对于在线拼车市场,(多个)连续处理很普遍,因为多个出行选项可用,如图1所示。在连续处理下估计因果效应对市场提出了挑战,同时保持了最大化其效率和性能的关键。
已经开发了一系列算法来解决 HTE 估计的问题。最早的解决方案可以追溯到隆升建模最吸引人的时候,如[23],最近被应用于在线市场,如[16,28]。然而,这些实现未能讨论如何减轻观测数据中普遍存在的混淆偏差。相比之下,统计和计量经济学方法,如因果森林(CF)[1,5]在混杂变量存在的情况下,直接考虑结果与治疗之间的关系。然而,估计量的理论性质建立在这样一个假设之上,即结果在治疗中部分是线性的。在实践中,折扣对请求的影响可以是任何处理的函数,如图2所示。为了解决这个问题,[2,6,18,27]提出使用非参数回归来解决非线性HTE估计。我们的工作建立在这些工作的理论结果之上。同时,该算法的可扩展性是将其部署到具有大量数据的在线市场的关键。近年来,还开发了基于神经网络的方法,例如 [22, 25],但它们缺乏可解释性,这在定价策略等高风险设置中很重要。
在本文中,我们通过提出广义休闲森林 (GCF) 来克服上述挑战,这是一种为连续治疗提供非参数 HTE 估计的方法。GCF 在合成数据集和真实数据集上都显示出与现有基线相比的优势,并展示了它在领先的拼车公司的在线部署方面的高性能。此外,我们在Spark上实现了GCF,并通过分布式计算获得了更高的计算效率,这为大规模在线市场的广泛应用铺平了道路。本文的其余部分安排如下。第 2 节介绍了初步符号和背景。然后在第 3 节中,我们正式提出了 GCF。我们通过将其应用于第 4 节中的合成数据集和真实数据集来验证 GCF 的性能。最后,在第 5 节中,GCF 的实际有效性通过其在在线实验中的卓越性能来证明。本节还简要介绍了GCF的Spark实现。我们在第 6 节中进行了一些讨论来结束本文。
2 初步
2.1 符号和假设

2.2剂量-响应函数
Dose-Response Function

2.3核回归和双/去偏估计器
3 广义 CAUSAL FOREST
在本节中,我们正式介绍了所提出的算法,即 GCF。它通过考虑具有非参数DRF的新分裂准则并使用基于核的双鲁棒估计器对其进行估计,放宽了CF中处理响应关系的部分线性假设。在下文中,我们展示了 GCF 在训练阶段和预测阶段的工作流程,然后详细说明拆分标准 CATE 估计器及其渐近属性。补充部分给出了GCF的实际调整和Spark实现的细节。

我们的算法是在Spark上实现的,用于大规模数据处理,树增长过程的机制与CF的机制不同。准确地说,数据存储在主机器上,树被克隆到每个分支机器上。数据随机分布到分支机器进行并行计算,重新收集到主机器进行集成。树将由每个分支机器上的集成标准更新。该分布式框架利用了多台机器的计算效率并加快了训练过程。
3.1分裂准则

4实验



n:样本
t: treatment
pehe:
pmse:

4.2模拟

4.3 Real-world Datasets

评估
文章开始介绍了增益直方图,但是现在基本很少人用了,我这里就只介绍下常用的指标。
auuc和qini

Qini曲线和Uplift曲线有些类似
5实施与部署

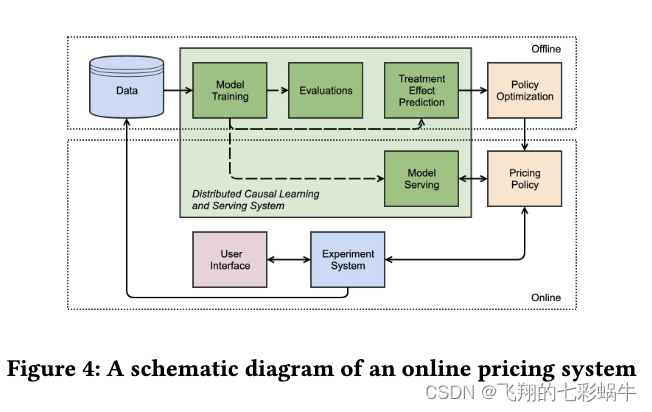
我们将我们的算法部署到领先的拼车公司的在线定价系统中。该系统旨在提供最佳定价策略,该策略支持超过 5 亿个乘客和数以万计的司机每天。鉴于如此大量的数据,我们在Spark上实现了GCF,通过分布式计算来加速模型训练。如图 4 所示,系统首先从实验系统中收集真实世界的数据。在下文中,数据被发送到模型训练模块,其中训练 GCF 和其他基线模型。随后,定制评估指标(例如,Qini 分数)选择的最佳模型为策略优化模块提供治疗效果预测,该模块为在线服务生成全局最优定价策略。为了检查我们模型的经验有效性,我们使用在线 A/B 测试比较了 GCF 和 CF 在两种业务设置下产生的折扣策略。我们通过将 ODT 随机分成两组来进行在线 A/B 测试。请注意,这里考虑的数据只占整个市场的一小部分,这意味着可以忽略网络效应。性能评估的关键指标是完成订单 (FO) 的增量,其结果如下。与 CF 相比,GCF 在单移动性选项策略和双移动性选项策略中分别提高了 15.1% 和 25.2%。结果表明,我们的模型可以更好地估计对复杂系统的治疗效果。
6结论
本文提出了一种新的基于森林的非参数算法,即广义因果森林,以解决连续处理的HTE估计问题。我们通过引入具有通用基于距离的分裂准则的DRF来扩展CF,该准则最大化连续治疗效果的异质性。为了估计DRF,我们使用基于核的双鲁棒估计器来保证双鲁棒性。为了处理大量的数据,我们在Spark上实现了GCF,并在领先的拼车公司成功地将GCF部署在在线定价系统中。实证结果表明,我们的方法明显优于竞争方法。在本文的范围内,我们只涵盖了一维连续处理的情况。但是我们建议的内容可以扩展到多维情况,而无需付出额外的努力。还值得一提的是,当处理空间较高且稀疏时,内核回归可能会受到维度诅咒的影响。更鲁棒的高维处理 HTE 估计算法有望成为未来的研究领域。
参考
做因果推断最难的是什么。 崔鹏教授说:最难的是评估,因为这是很上帝视角的东西。
- 因果推断uplift模型-GCF - 知乎
- DESCN:用于个体治疗效果估计的深度全空间交叉网络-CSDN博客
- 因果推断(三)各种效应和它们之间的关系
- 弹性模型的评测指标AUUC - 知乎
Causal Inference and Uplift Modeling A review of the literature重读笔记 - 知乎
Causal Inference and Uplift Modeling A review of the literature论文笔记 - 简书
大白话谈因果系列文章(五)uplift模型评估 - 知乎
闲聊因果效应(4):离线评估 - 知乎
因果推断 | Uplift Model 评估指标 - 知乎
这篇关于GCF:在线市场异质治疗效果估计的广义因果森林的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






