本文主要是介绍论文笔记:Deep Residual Learning for Image Recognition(ResNet),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、基本信息
标题:Deep Residual Learning for Image Recognition
时间:2015
第一作者:Kaiming He
论文领域:深度学习、计算机视觉、CNN
引用格式:He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
二、研究背景
最近的证据揭示了网络深度是至关重要的,领先结果中对挑战ImageNet数据集都利用“非常深”的模型,深度从16到30。
深度加深带来的问题:
- 梯度消失和爆炸(vanishing/exploding gradients)
对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。
- 开始收敛时,退化问题产生,精确度下降(退化并不是过度拟合引起的,在适当深度的模型上增加更多的层会导致更高的训练误差)
本文说道不是过拟合问题:因为可以从图中看出随着深度的增加,训练误差变大(事实上,测试误差也很大),而过拟合指训练误差小,测试误差大

有两种解决思路,一种是调整求解方法,比如更好的初始化、更好的梯度下降算法等;另一种是调整模型结构,让模型更易于优化——改变模型结构实际上是改变了error surface的形态。
ResNet的作者从后者入手,探求更好的模型结构。将堆叠的几层layer称之为一个block,对于某个block,其可以拟合的函数为 F ( x ) F(x) F(x),如果期望的潜在映射为 H ( x ) H(x) H(x),与其让 F ( x ) F(x) F(x) 直接学习潜在的映射,不如去学习残差 H ( x ) − x H(x)−x H(x)−x,即 F ( x ) : = H ( x ) − x F(x):=H(x)−x F(x):=H(x)−x,这样原本的前向路径上就变成了 F ( x ) + x F(x)+x F(x)+x,用 F ( x ) + x F(x)+x F(x)+x来拟合 H ( x ) H(x) H(x)。作者认为这样可能更易于优化,因为相比于让 F ( x ) F(x) F(x)学习成恒等映射,让 F ( x ) F(x) F(x)学习成0要更加容易——后者通过L2正则就可以轻松实现。这样,对于冗余的block,只需 F ( x ) → 0 F(x)→0 F(x)→0就可以得到恒等映射,性能不减。
退化
按理说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。
然而事实上,这却是问题所在。“什么都不做”恰好是当前神经网络最难做到的东西之一。
也许赋予神经网络无限可能性的“非线性”让神经网络模型走得太远,却也让它忘记了为什么出发(想想还挺哲学)。这也使得特征随着层层前向传播得到完整保留(什么也不做)的可能性都微乎其微。用学术点的话说,这种神经网络丢失的“不忘初心”/“什么都不做”的品质叫做恒等映射(identity mapping)。因此,可以认为Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
作者:薰风初入弦
链接:https://www.zhihu.com/question/64494691/answer/786270699
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
三、创新点
Residual Block结构
F ( x ) + x F(x)+x F(x)+x构成的block称之为Residual Block,即残差块,如下图所示,多个相似的Residual Block串联构成ResNet。

本文通过引入残差学习(residual learning)来解决退化问题,即⊕上方学习的为 H ( x ) − x H(x) - x H(x)−x,这也正是要学习的残差 F ( x ) : = H ( x ) − x F(x) := H(x) - x F(x):=H(x)−x,希望通过 H ( x ) = F ( x ) ⊕ x H(x) = F(x)⊕x H(x)=F(x)⊕x拟合 x x x,这里引入了x,把恒等映射作为网络H(x)的一部分。而原本是 H ( x ) H(x) H(x)拟合 x x x。
这里有个疑问: F ( x ) + x = H ( x ) − x + x = H ( x ) F(x) + x = H(x) - x + x = H(x) F(x)+x=H(x)−x+x=H(x)这从等式角度来说本来就相等,为什么叫做拟合呢? H ( x ) − x + x = H ( x ) H(x) - x + x = H(x) H(x)−x+x=H(x),如果考虑上图2层网络拟合右边 H ( x ) H(x) H(x)是原本需要拟合的函数,那么左边的残差学习的是 H ( x ) − x H(x)- x H(x)−x,两边学习的容易程度也不一样。个人理解。
参考解释1:
怎么解决退化问题?
深度残差网络。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
标识快捷连接既不增加额外的参数,也不增加计算复杂度。整个网络仍然可以通过带有反向传播的SGD进行端到端的训练。
参考解释2:
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如原来是从5.1到5.2,映射F’的输出增加了1/51=2%,而对于残差结构从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…
作者:theone
链接:https://www.zhihu.com/question/53224378/answer/159102095
来源:知乎
必须要大于1层,否则没有效果:
y = F ( x , { W i } ) + x = ( W 1 x ) + x = ( W 1 + 1 ) x \mathbf{y}=\mathcal{F}\left(x,\left\{W_{i}\right\}\right)+x=\left(W_{1} x\right)+x=\left(W_{1}+1\right) x y=F(x,{Wi})+x=(W1x)+x=(W1+1)x
纬度问题
The convolutional layers mostly have 3 * 3 filters and follow two simple design rules:
(i) for the same output feature map size, the layers have the same number of filters;
(ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
(i)空间纬度
之前提到输入x要与F(x)维度一样,如果不一样则投影到 W s W_s Ws解决空间纬度问题:
y = F ( x , { W i } ) + W s x \mathbf{y}=\mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right)+W_{s} \mathbf{x} y=F(x,{Wi})+Wsx
(ii)深度纬度
When the dimensions increase (dotted line shortcuts in Fig. 3), we consider two options:
(A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter;
(B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1* 1 convolutions).
(A)就是直接补0,不需要额外参数
(B)就是在跳接过程中加一个1*1的卷积层进行升维,下面右图

网络结构

作者对 VGG-19 进行仿制与改造,规则在纬度问题那里提到,得到了一个 34 层的 plain network,然后又在这个 34 层的 plain network 中插入快捷连接,最终形成了一个 34 层的 residual network。
以及下面继续加深网络:

四、实验结果


18层效果还不是很明显,34层以及有很大改进。
作者最后在Cifar-10上尝试了1202层的网络,结果在训练误差上与一个较浅的110层的相近,但是测试误差要比110层大1.5%。作者认为是采用了太深的网络,发生了过拟合。
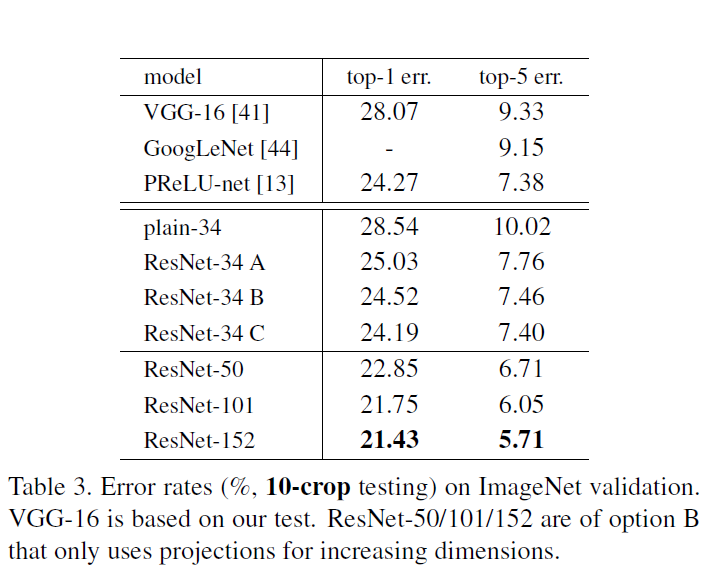
在表3中,比较了三个选项:
- (A)填充零的快捷方式用于增加维度,并且所有的快捷方式都是无参数的(与右表2和图4相同);
- (B)投影捷径用于增加维度,其他捷径为同一性;
- ©所有捷径都是投影。
作者考虑内存和时间,最后使用B
五、结论与思考
作者结论
总结
有了梯度相关性这个指标之后,作者分析了一系列的结构和激活函数,发现resnet在保持梯度相关性方面很优秀(相关性衰减从 1 2 L \frac{1}{2^{L}} 2L1到了 1 L \frac{1}{\sqrt{L}} L1 )。这一点其实也很好理解,从梯度流来看,有一路梯度是保持原样不动地往回传,这部分的相关性是非常强的。
思考
感觉跳接(shortcut connection)和FCN的跳跃连接很像。那边可以跳多层还能上采样叠加。
参考
ResNet详解与分析
残差网络ResNet笔记
这篇关于论文笔记:Deep Residual Learning for Image Recognition(ResNet)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







