ResNet
Deep Residual Learning for Image Recognition
要解决的问题:
(1), network是否叠加越多越好?其中最显著的问题是 gradient vanishing or gradient exploding.
(2), 随着网络深度的增加,accuracy很容易饱和,导致快速降解的问题。
Resnet的residual learning,
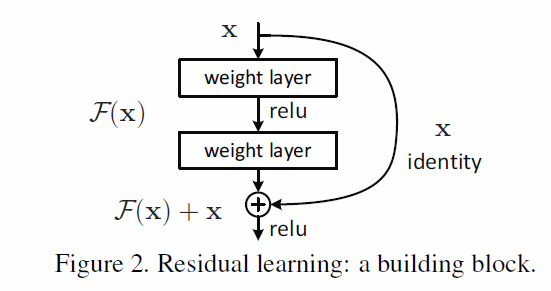

其中identity mapping X 的作用很大,有效地控制了梯度消减的问题,同时X也是一个非常经济的问题,只需要将前面的feature map 与后面的 feature map进行element-wise addition, channel by channel,计算量很小。

对paper中对比实验的观察有:
(1), degradation problem,对于plain network,34-layer的比18-layer的网络有着更高的training error,而18-layer的解空间是34-layer的解空间的一个子空间。
猜想:这个问题产生的原因不是梯度消弭引起的,因为在network中使用了 BN,(BN保证前向传播的signals显示出差异),同时对回传的梯度也证实了network在BN的作用下正常地norms。
BN除了将输出层的数据归一化到 mean=0, var=1的分布中,而且还有一个作用是 reducing Internal covariate shift 问题,(越深的网络特征的扭曲越厉害。但特征本身对类别的标记是不变的。源空间与目标空间中条件概率一致,但是边缘概率不同,BN可以让边缘概率尽可能的接近。)
同时,将min_batch 归一化之后,
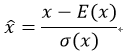
其导数是1,可以保持前面传过来的gradient,原封不动的backwards到下一层。
假如后面的激活函数是 sigmoid,

归一化之后的line 是图中的红线,所以也是接近于线性。







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
