本文主要是介绍Python编程|用Python编写一个支持断点续传、显示实时网速的通用下载器。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注它,不迷路。
本文章中所有内容仅供学习交流,不可用于任何商业用途和非法用途,否则后果自负,如有侵权,请联系作者立即删除!
1. 需求
通过上篇文章 JS逆向|获取某电影解析网站的真实视频地址,获取到了视频的真实播放地址:
https://v3.douyinvod.com/6bb5df6aa38a2bc8fc696a19e39caacf/63215cb6/video/tos/cn/tos-cn-ve-0030/cd3ee0c450e64851bb871ad245f6a83c/?filename=1.mp4现在使用Python写一个脚本,将其下载下来。
2. 分析
一般来说,一个文件下载的网址是静态的,不存在反爬(需要鉴权的除外),因此不需要去格外研究反爬。
思路:
-
使用requests库来进行下载
-
通过设置headers['range'] 字段来告诉程序从哪里开始下载,即断点续传
-
下载块 除以 文件总大小 即为 下载百分百
-
下载块 除以 时间差值 即为 当前网速
3. 源代码
通过一番摸索和调试,写出了下面的代码:
# coding: utf-8
import re
import requests
from pathlib import Path
from time import time, perf_counter
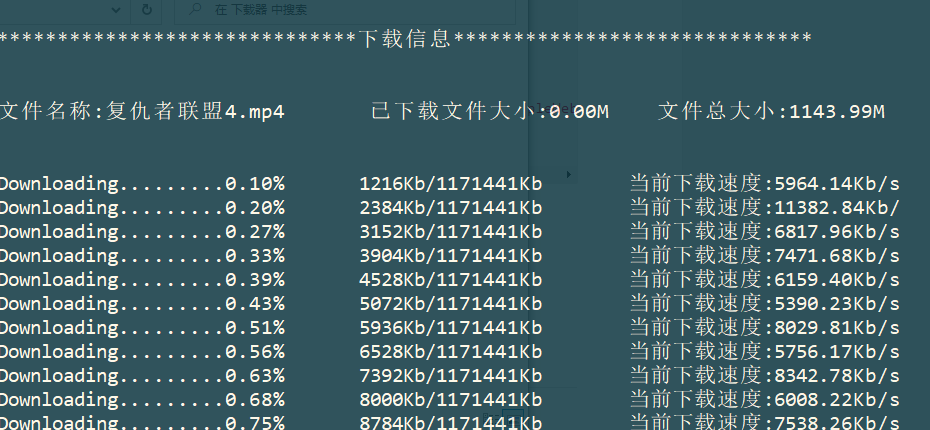
from fake_useragent import UserAgentdef download_file_from_url(dl_url, file_name, headers):file_path = Path(__file__).parent.joinpath(file_name)if file_path.exists():dl_size = file_path.stat().st_sizeelse:dl_size = 0headers['range'] = f'bytes={dl_size}-'response = requests.get(dl_url, stream=True, headers=headers)print('\n\n' + '*' * 30 + '下载信息' + '*' * 30)total_size = int(response.headers['content-length'])print(f'\n\n文件名称:{file_name}\t\t已下载文件大小:{dl_size / 1024 / 1024:.2f}M\t\t文件总大小:{total_size/1024/1024:.2f}M\n\n')start = perf_counter()data_count = 0count_tmp = 0start_time = time()with open(file_path, 'ab') as fp:for chunk in response.iter_content(chunk_size=512):data_count += len(chunk)now_pross = (data_count / total_size) * 100mid_time = time()if mid_time - start_time > 0.1:speed = (data_count - count_tmp) / 1024 / (mid_time - start_time)start_time = mid_timecount_tmp = data_countprint(f"\rDownloading.........{now_pross:.2f}%\t{data_count//1024}Kb/{total_size//1024}Kb\t当前下载速度:{speed:.2f}Kb/s", end='')fp.write(chunk)end = perf_counter()diff = end - startspeed = total_size/1024/diffprint(f'\n\n下载完成!耗时:{diff:.2f}秒, 平均下载速度:{speed:.2f}Kb/s!\n文件路径:{file_path}\n')if __name__ == '__main__':url = 'https://v3.douyinvod.com/6bb5df6aa38a2bc8fc696a19e39caacf/63215cb6/video/tos/cn/tos-cn-ve-0030/cd3ee0c450e64851bb871ad245f6a83c/?filename=1.mp4'#filename = url.rpartition('/')[-1]filename = "复仇者联盟4.mp4"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36', }download_file_from_url(url, filename, headers)初始下载:
暂停后再下载:
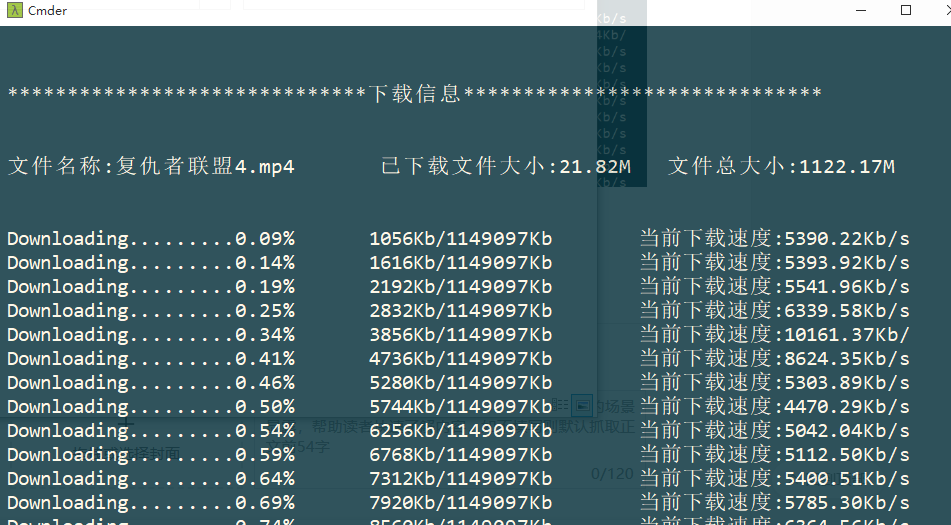
这里有个小问题,下载进度没有将已经下载好的没有计算在内。后面再研究了。
今天的文章就分享到这里,后续分享更多的技巧,敬请期待。
这篇关于Python编程|用Python编写一个支持断点续传、显示实时网速的通用下载器。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!