本文主要是介绍【论文阅读】Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurat...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一篇弱监督分割领域的论文,发表在CVPR2022上:
论文标题:
Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurate Segmentation Model Against Thresholds
作者信息:

代码地址:
https://github.com/gaviotas/AMN
Abstract
现有的方法大多都在讨论,CAM生成中的一些稀疏性的coverage,导致了WSSS的性能瓶颈。作者则认为CAM激活中的一些全局性的阈值也会也会影响其性能。作者认为CAM进行激活的阈值需要满足以下两个条件:
- 1.减弱在前景区域内CAM激活的不平衡的现象
- 2.增大前景区域和背景区域的激活的gap
针对此,作者提出了activation manipulation network(AMN),包含per-pixel classification loss(PCL)和label conditioning module(LC)。其中
per-pixel classification 表示二值化的激活过程,label conditioning用于控制输出的真实的标签 。
Introduction
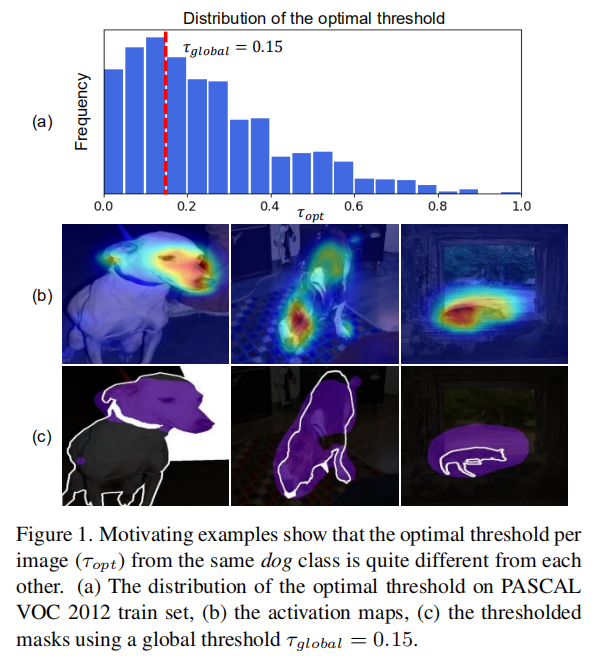
(现有方法中的问题)CAM是WSSS任务中一种非常重要的方法。很多方法指出从CAM中获得的伪标签只能捕捉最有discriminative的部分,导致了性能瓶颈。作者认为该性能瓶颈主要来自于CAM激活中的全局阈值,主要原因是:
- 1.CAM激活时提供的全局阈值并不能适合每张图像的阈值(图1a),很多时候这个差距很大。
- 2.CAM的全局阈值并不总是会导致稀疏覆盖。
(造成这种阈值的进一步的原因)GAP具有平均效应,它将特征映射平均为一个单一的分类分数。相同的值可以来自于完全不同的激活。
(作者的思路)通过改变CAM激活的过程:
- 1.增大前景区域和背景区域的激活的阈值gap,如果阈值在gap内,阈值掩模相同。来提高生成的鲁棒性。
- 2.减弱在前景区域内CAM激活的不平衡来改善激活质量。
作者认为通过为整个前景像素和背景像素(例如,1和0)分配两级激活,可以满足上述两个条件。对应于文中的per-pixel classification 模块。除此以外,作者设计了label conditioning模块,通过从给定的K类(K是每幅图像的地面真实图像标签给出的类数)找出最佳预测。(CLIP模型类似的优点,不拘泥于固定的类别)
Preliminaries
Class activation mapping (CAM):
常规的CAM的生成手段,对每个feature的通道按照类别的权重求和:
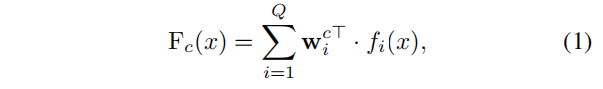
现有的WSSS方法都将 F c ( x ) F_c(x) Fc(x)归一化到[0 1]的范围内,然后应用一个全局阈值来分离前景像素和背景像素。作者这里改变了激活阈值的方法。
Threshold matters in WSSS:
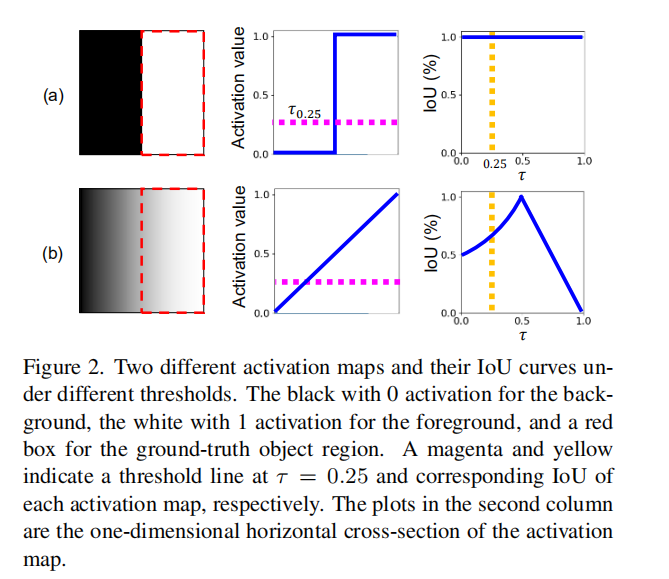
GAP允许将不同的激活映射到相同的分类分数。因此, F c ( x ) F_c(x) Fc(x)可以有不同的激活分布。因此没有一个阈值可以获得最优解。作者列出来两个condition,作为改善激活方法的条件:
- c1: reducing the activation imbalance within the foreground
- c2: enforcing the large activation gap between the foreground and the background activation
通过共同满足c1和c2,一个激活可以通过一个全局阈值来很好地区分前景和背景。图2中给了举例(a是满足条件的,b是不满足条件的)
Activation Manipulation Network
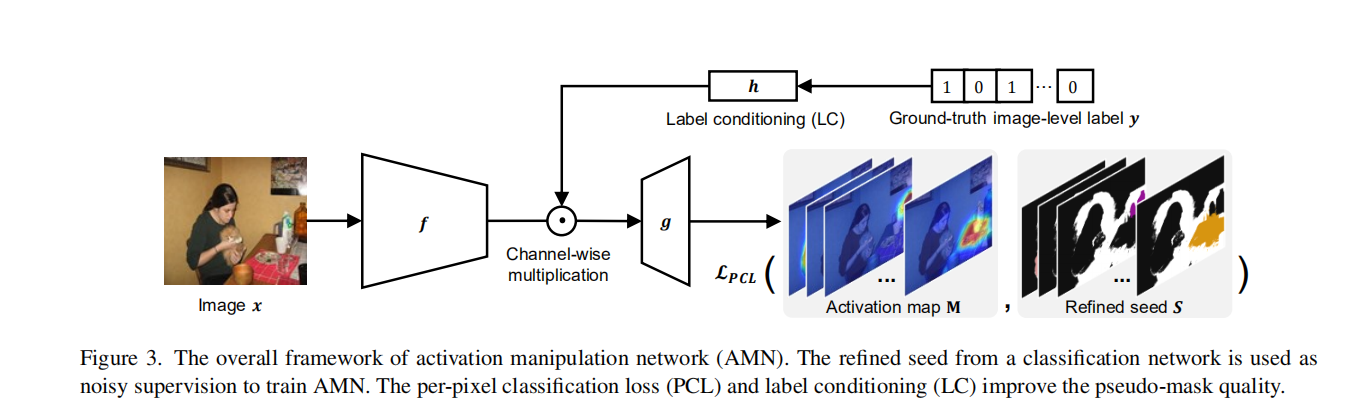
4.1. Overall training procedure
整体流程主要包括四步:
- seed generation 2) pseudo-mask generation with the proposed AMN 3) final segmentation
1)通过应用CAM获得像素级的伪粗标签,在伪粗标签上应用CRF算法,继续应用文献[1]的方法获得refined seed。
2)将图像和图像级标签作为输入,refined seed作为目标函数,训练AMN网络(通过PCL和LC模块)。AMN的网络架构与CAM的分类网络相同,只做了一点修改;用卷积层替换GAP层和最后一个分类层来预测像素级掩码。然后使用IRN方法进一步改进获得的伪mask。
3)训练常规的分割网路,获得结果。
4.2. Per-pixel classification
根据上面的两个条件c1和c2,作者提出了pixel classification losss,即在原来的像素级别的激活之前,加入一个强制的两级(0,1)的激活。这种两级的激活满足c1和c2的条件,同时,不需要GAP,可以有效地处理全局阈值问题。(论文里感觉有些含糊,在GAP激活这块儿,没看懂,这个模块的实现的具体细节方法,作者也没讲)。
4.3. Label conditioning
设数据集里面的类别有N+1个,但是一个图片上肯定同时出现这么类别。Label conditioning将每个像素应该映射到K + 1类中的一个,K是基础类,1是背景类。
(作者解释了一些原因):首先,小类别有助于区分外观相似的物体,除非所有的类别都同时出现在图像中。这样有助于防止图像类别一些误判。
其次,训练用的伪标签比较粗糙,比较咋,需要用大量的数据进行。这种Label conditioning类似于一种数据扩增,可以提供大量的监督信息。非目标类激活重新分配到目标类激活中,增加了前景的整体激活。这对于促进前景中不那么较差的区域特别有用(没看懂)。
(作者的具体做法):只在网络高层次维度上应用LC,因为低层次会影响到特征的选择。作者将图像级标签编码为特征向量,然后直接将这个向量乘以AMN网络中的特征图(如图2所示),最终的activation map的计算方法如下:
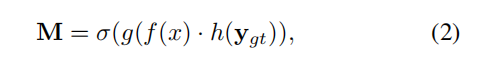
式子中, f f f、 g g g、 h h h分别表示backbone、cnn、编码层
Experiments
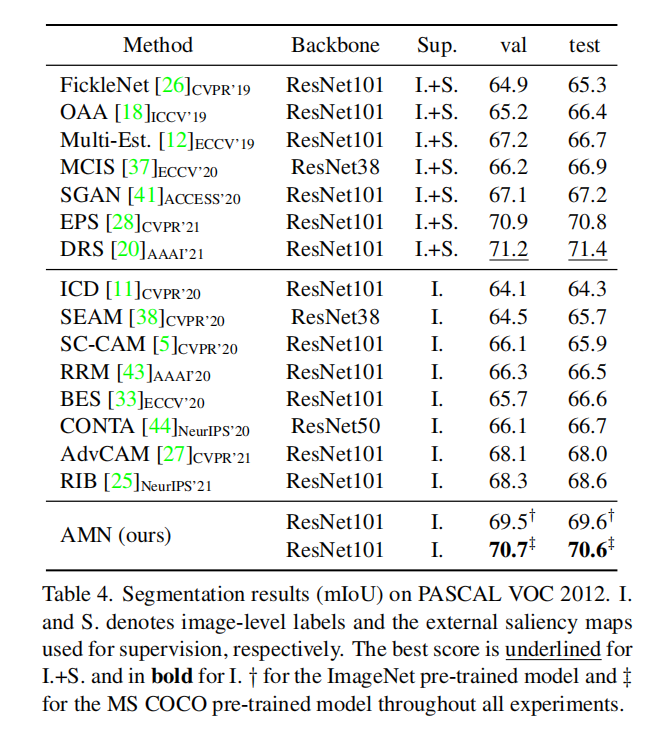
这篇关于【论文阅读】Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurat...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
