本文主要是介绍Hierarchical Morphology-Guided Tooth Instance Segmentation from CBCT Images,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇论文是之前那篇Naure牙齿分割论文的前身吧,那篇论文中用到的方法有在这里提到。
目录
- 摘要
- 1 介绍
- 2 方法
- 2.1 牙齿质心和骨骼提取网络
- 2.2 牙齿分割的多任务学习
- 2.3实现细节
- 3 实验结果
- 3.1 数据集和评估指标
- 3.2 评价与比较
- 3.3 与最先进方法的比较
- 4 结论
摘要
从CBCT图像中自动准确地分割单个牙齿,即牙齿实例分割,是计算机辅助牙科的重要步骤。以往的研究通常忽略了牙齿丰富的形态学特征,如牙根尖,这对成功的治疗结果至关重要。本文提出了一个基于两阶段学习的框架,该框架明确地利用分层牙齿形态表示提供的全面几何指导进行牙齿实例分割。给定三维CBCT输入图像,我们的方法首先学习提取牙齿的质心和骨架,分别用于识别每个牙齿的大致位置和拓扑结构。基于第一步的输出,进一步设计了一种多任务学习机制,通过同时回归边界和根尖作为辅助任务来估计每个牙齿的体积掩模。
广泛的评估、消融研究以及与现有方法的比较表明,我们的方法实现了最先进的分割性能,特别是在具有挑战性的牙齿部位(即牙根和边界)周围。这些结果表明我们的框架在现实世界的临床场景中具有潜在的适用性。
1 介绍
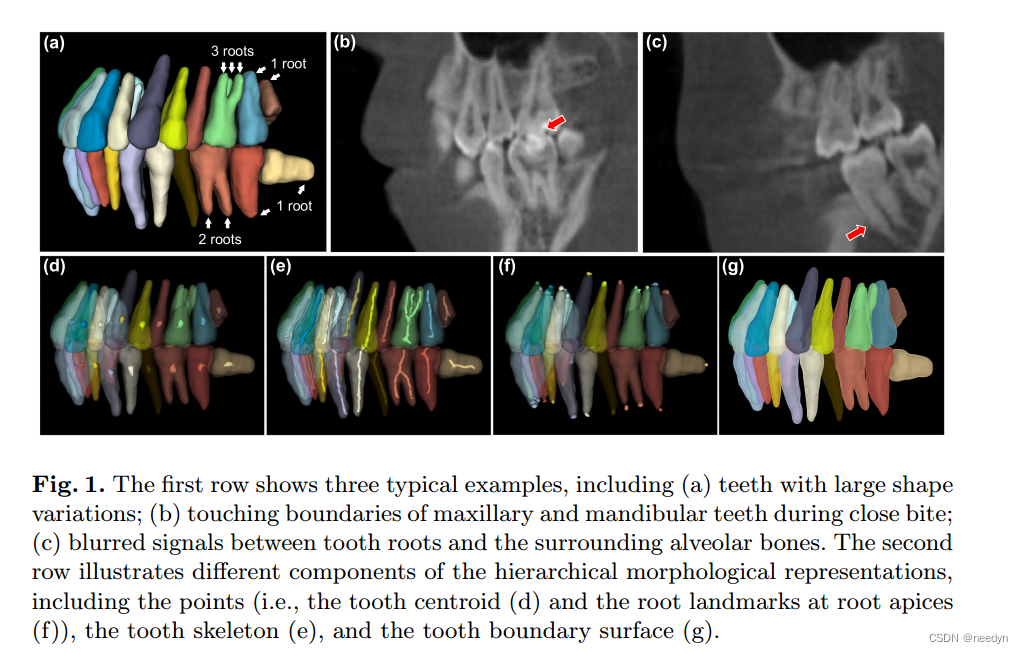
计算机辅助设计(CAD)已广泛应用于数字牙科的诊断、修复和正畸治疗计划。在这些过程中,通常从锥形束计算机断层扫描(CBCT)图像中分割的3D牙齿模型[4,5]对于帮助牙医拔牙、种植或重新排列牙齿至关重要。在临床实践中,牙医需要从CBCT图像中逐片手动标记每颗牙齿,这既费力又耗时,而且高度依赖于操作员的经验。因此,在实际应用中需要一种准确的、全自动的方法从牙齿CBCT图像中分割出单个牙齿。
然而,自动分割单个牙齿仍然是一个具有挑战性的任务,因为牙齿在其几何形状上表现出很大的变化。例如,上颌磨牙通常有三根,而下颌磨牙通常有两根8。除了一般规则之外,还可以发现臼齿单根的特殊情况(图1(a)),这种差异在现实世界的诊所中相当普遍。即使是最先进的基于学习的方法[4,5,14]也常常无法处理如此复杂的情况。这主要是因为这些方法对牙齿只采用简单的表示(例如,牙齿质心或边界框),因此无法捕获每个牙齿的详细形状变化。在图像对比度较低的区域,如近距离咬合时接触牙齿的共同边界(图1(b))和牙根与其周围牙槽骨之间的界面(图1©),这种情况更严重。传统的方法[1,2,6,7,9,11,15]或基于学习的网络[4,5,14]都无法在这些区域正确地将牙齿从背景组织中分割出来,尽管牙根信息在正畸治疗中至关重要,可以确保牙齿在运动过程中根尖不会穿透周围的牙槽骨。
在本文中,我们提出了一种层次形态表示来捕捉复杂的牙齿形状和重要的牙齿特征。具体来说,这种分层形态表示由齿心和根尖(即点)、骨架、边界表面和体积组成(图1(d) - (g), (a))。在此基础上,设计了一种基于粗到精学习的牙齿实例自动准确分割框架。给定三维输入CBCT图像,为了捕获所有单个牙齿的位置和变化的拓扑结构,特别是在多根区域,设计了第一阶段(粗层次)的神经网络来分别预测牙齿质心和骨骼。然后,在第二阶段进一步提出了一个多任务网络,以第一阶段估计的牙齿骨架为指导,同时预测每个牙齿的详细几何特征,即牙根标志(或尖)、边界面和体积掩膜。由于这三个任务从几何角度来看是内在关联的,因此回归每个牙齿的牙根标志和边界表面可以直观地提高在重要和具有挑战性的区域(例如牙齿边界和牙根尖)的分割性能。通过在现实世界诊所收集的CBCT数据集上进行大量实验,评估了我们方法的性能。相应的结果表明,我们的方法明显优于其他最先进的方法,表明本研究中设计的分层形态表示用于牙齿实例分割的有效性。
2 方法
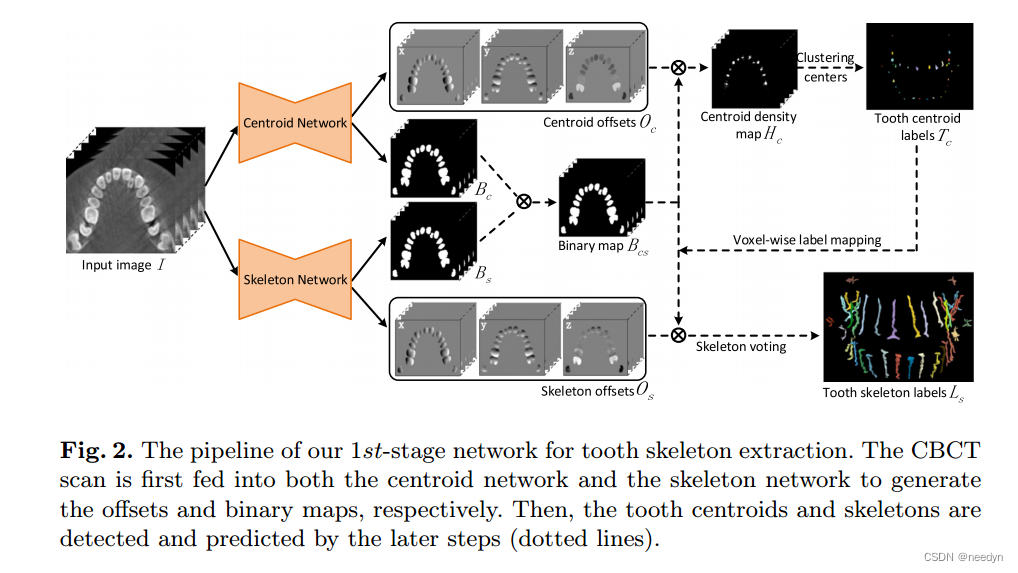
框架包括两个阶段。在第一阶段,设计一个预测网络,提取粗级形态学表征,即每颗牙齿的质心和骨架,来表示牙齿结构。
在第二阶段,使用多任务学习机制训练具有粗级形态学指导(牙齿骨架)的分割网络,生成详细的牙齿体积、边界和牙根标志。这两个步骤的示意图分别如图2和图3所示,具体如下图所示。
2.1 牙齿质心和骨骼提取网络
由于牙齿的质心和骨架分别定义了牙齿的空间位置和拓扑结构,因此本步骤中的网络旨在实现以下目标:1)通过识别牙齿的质心来定位单个牙齿,2)通过预测牙齿的骨架来捕获牙齿的拓扑结构
2.2 牙齿分割的多任务学习
在实例级牙齿骨架标签图Ls的指导下,进一步提取单个牙齿。为了提高切分的精度,特别是在牙齿边界和牙根区域附近,我们引入了一种多任务学习机制,该机制可以有效地利用牙齿体积、边界和牙根标记之间的内在相关性。
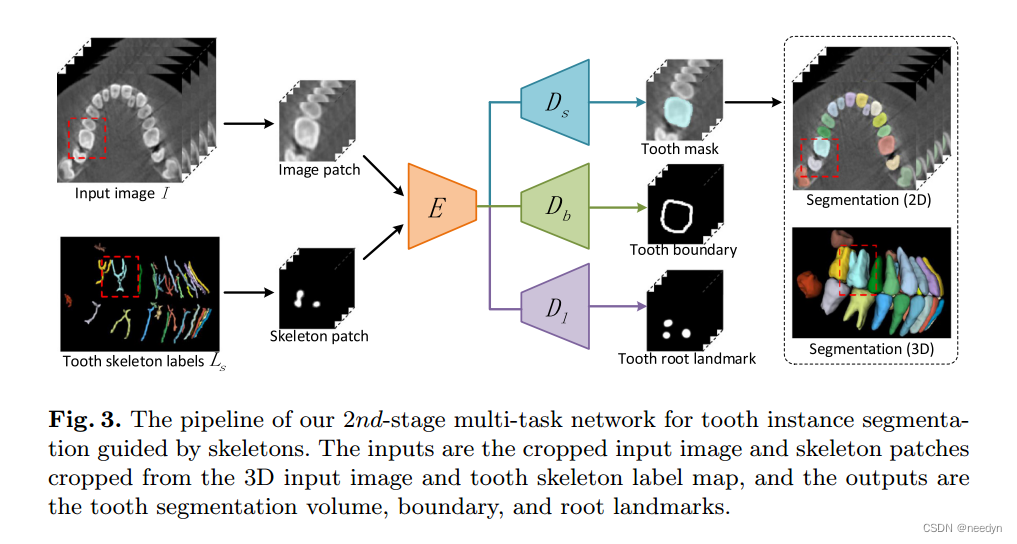
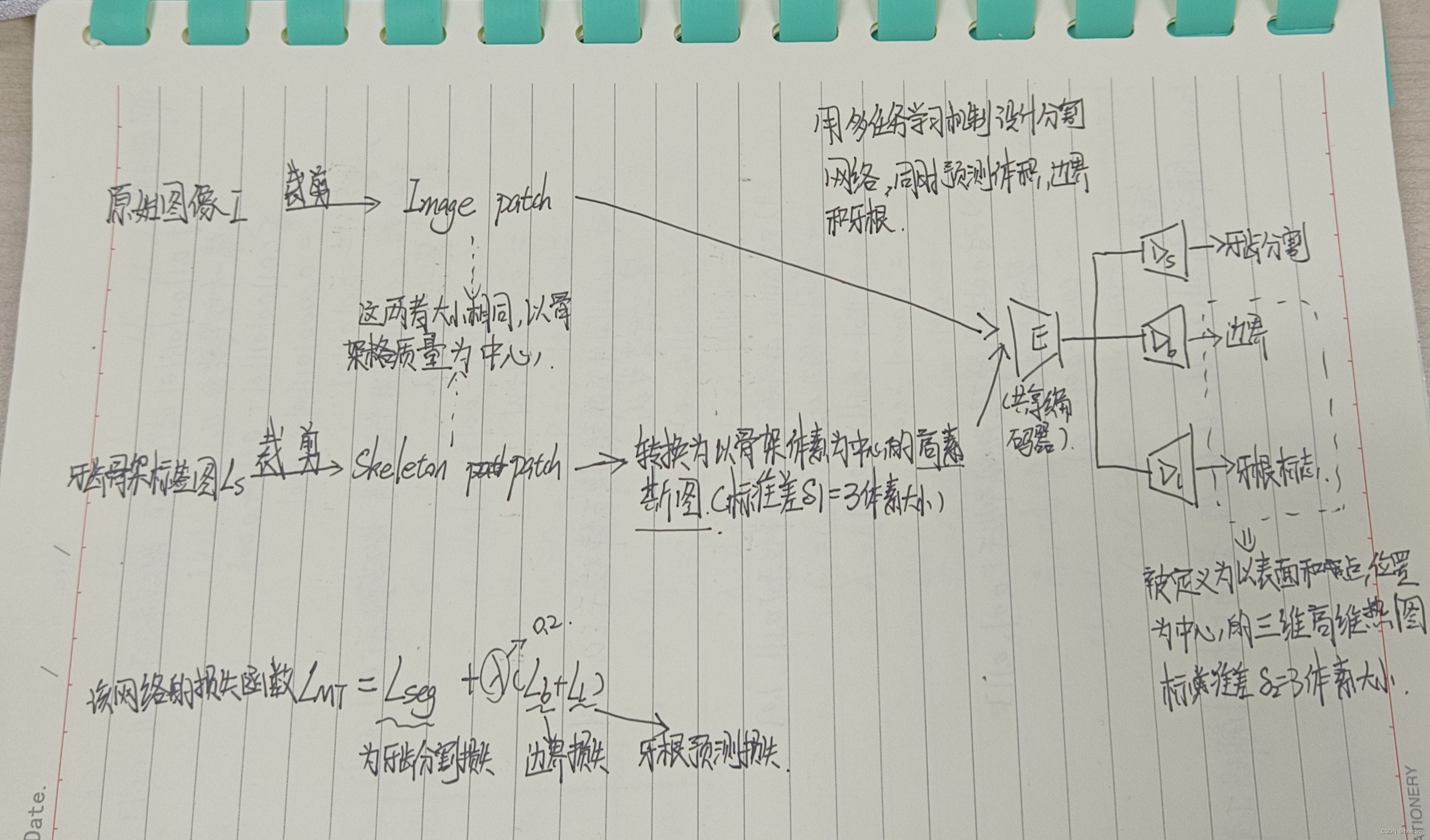
2.3实现细节
采用3D V-Net[12]作为两阶段框架的网络骨干。第一阶段将所有CBCT图像转换为相同的输入大小256 × 256 × 256。第二阶段的裁剪补丁大小设置为96 ×96×96,以确保整个前景牙齿对象被包括在内。该框架在PyTorch中实现,使用Adam优化器进行训练,固定学习率为1e−4。在这两个阶段中,网络都是在50K次迭代中训练的。一般情况下,在使用Nvidia GeForce 1080Ti GPU的Linux服务器上,训练时间约为5小时(第一阶段)和8小时(第二阶段)。
学习一个V-Net网络
3 实验结果
3.1 数据集和评估指标
我们对在牙科诊所进行正畸治疗前后收集的100例患者的CBCT扫描进行了广泛的评估。该数据集包含许多牙齿拥挤、缺失或错牙合问题的异常病例。数据集的分辨率为0.4 mm。我们手动裁剪3D CBCT图像上的牙齿区域,将其大小调整为256×256×256,然后将CBCT图像强度归一化到[0,1]的范围。为了获得ground truth,分割标签和牙根标记由牙医手工标注。基于标注的分割标签,使用形态学操作生成相应的牙骨架和边界根据标记的掩模直接计算牙齿的形心。为了训练网络,数据集被随机分成三个子集,即50次扫描用于训练,10次扫描用于验证,其余40次扫描用于测试。
为了定量评估我们的框架的性能,我们采用不同的指标来衡量牙齿检测和分割的准确性。具体来说,我们通过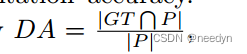 来测量牙齿检测精度(DA),其中GT和P是指基础真值和预测牙齿的两组。对于牙齿分割,采用Dice、Jaccard、平均表面距离(ASD)和Hausdorff距离(HD)四个指标来评价分割效果。由于Hausdorff距离是预测的牙齿表面与真实牙齿表面之间最小距离的最大值,因此它是仅用很小比例的前景体素就能测量牙齿根部周围区域分割误差的关键指标
来测量牙齿检测精度(DA),其中GT和P是指基础真值和预测牙齿的两组。对于牙齿分割,采用Dice、Jaccard、平均表面距离(ASD)和Hausdorff距离(HD)四个指标来评价分割效果。由于Hausdorff距离是预测的牙齿表面与真实牙齿表面之间最小距离的最大值,因此它是仅用很小比例的前景体素就能测量牙齿根部周围区域分割误差的关键指标
3.2 评价与比较
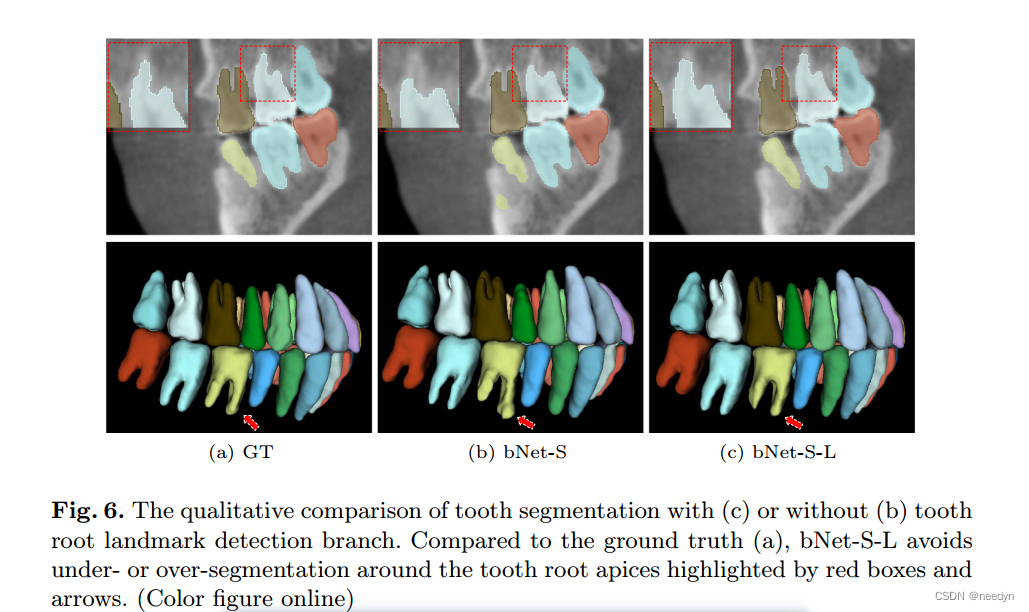

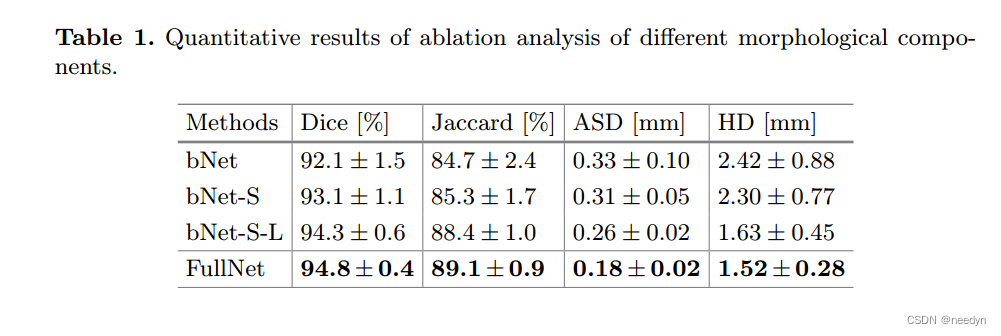
在表1中,我们给出了四种配置的分割结果:(1)在第一阶段网络中,我们直接利用牙齿质心来检测和表示每个牙齿,构建基线网络(bNet);在第二阶段网络中,我们构建了一个不进行牙齿边界和牙根地标预测的单任务分割网络;(2)为了更好地表示每个牙齿对象,我们只在基线网络中加入一个牙齿形态学信息,即牙齿骨架,记为bNet-S;(3)与bNet-S相比,我们在多任务学习的第二阶段网络中增加了牙根地标检测作为一个单独的分支,记为bNet-S- l;(4)我们进一步将第二阶段网络中的齿界预测分支bNet-S-L作为最终网络(FullNet)进行论证。需要注意的是,这四种配置都是利用牙齿质心点来检测三维CBCT图像中的牙齿物体,因此检测精度是相同的,没有列在表1中。
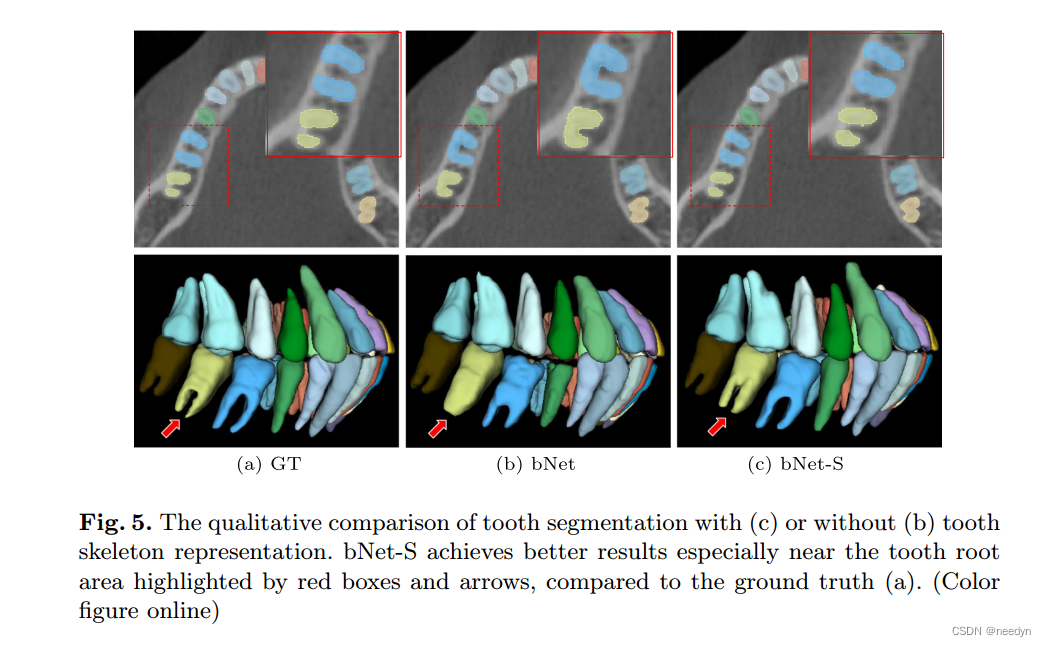
牙齿骨骼表征的好处。与牙心相比,牙骨架提供了更丰富、更真实的几何拓扑信息,可指导后续的牙段分割,尤其适用于处理多根磨牙。为了验证其有效性,我们在第一阶段将牙骨架检测组件(bNet- s)添加到基线网络(bNet)中,并将定量结果显示在表1中。可以看出,bNet-S在所有方面始终如一地提高了分割性能指标(例如,1.0% Dice改进和0.02 mm ASD改进)。另外,如图5所示为典型的视觉对比,可以看出,在牙骨架的引导下,第二阶段分割网络可以准确地分离出臼齿的不同牙根。这表明,具有清晰齿形信息的牙齿骨架对捕获复杂齿形具有重要的优势。
牙根标记检测的好处。在我们的第二阶段网络中,bNet-S-L增加了另一个分支,通过多任务学习机制来预测牙根标志,而不仅仅是生成分割掩码。如表1所示,与bNet-S相比,bNet-S- l的Hausdorff距离从2.30 mm显著下降到1.63 mm。需要注意的是,HD度量测量的是真实牙面与预测牙面之间最小表面距离的最大值,因此在牙根尖附近的分割不足或分割过度通常会导致较大的误差。这表明牙齿分割预测和标记检测的多任务学习有助于网络从几何角度捕捉内在的相关性,从而有利于分割任务。为了进一步分析有效性,我们还在图6中提供了一个可视化示例,其中bNet-S-L即使在有限的强度对比度下也有效地解决了牙根(红框突出显示)的分割不足或过度分割问题。
牙界预测的好处。在我们的FullNet中,在第二阶段的网络中增加了第三个分支——牙齿边界预测,使得网络在强度对比有限的情况下更加关注牙齿边界区域。统计上,FullNet获得了最好的分割性能,将Dice平均得分和ASD误差分别提高到94.8%和0.18 mm。图7的定性结果还表明,即使在CBCT图像中存在金属伪影,FullNet也可以更准确地分割牙齿边界。更有代表性的FullNet分割结果如图4和图8所示。
3.3 与最先进方法的比较
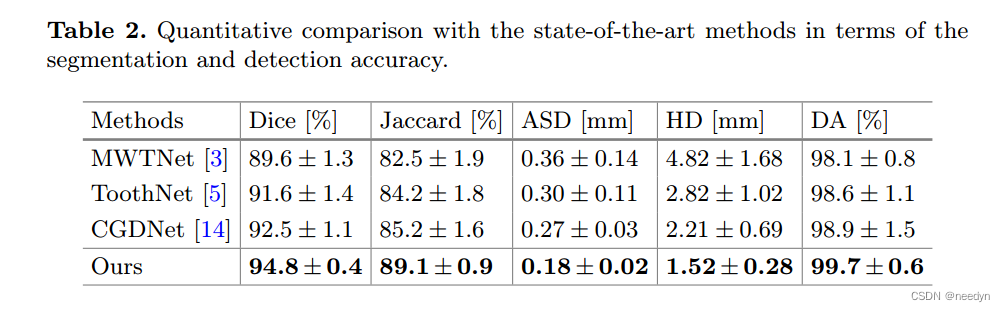
我们实现了我们的框架,并将其与几种最先进的基于深度学习的牙齿分割方法进行了比较,包括基于区域建议的网络(ToothNet)[5]、中心引导网络(cgnet)[14]和基于语义的方法(MWTNet)[3]。请注意,为了公平比较,我们在所有方法中使用了相同的网络骨干(V-Net)。如表2所示,与直接利用牙齿边界一步同时检测和分割单个牙齿的MWTNet[3]相比,我们的方法的Dice得分提高了5.2%,HD误差提高了3.30 mm,显示了两阶段检测-分割框架的优势。虽然toothnet[5]是一个两阶段网络,但它只利用边界框来表示单个牙齿,我们的方法在分割和检测性能上仍然有很大的优势。最后,我们还观察到,我们的方法始终比CGDNet[14]获得更高的精度,在该特定任务中达到了最先进的性能。其中,分割准确率(Dice)从92.5%提高到94.8%,检测准确率(DA)从98.9%提高到99.7%。值得注意的是,尽管牙根信息在正畸治疗中是一个重要的考虑因素,但这些相互竞争的方法对牙根尖周围的分割关注较少,强度对比有限,往往导致牙根分割不足或过度,HD误差较高。
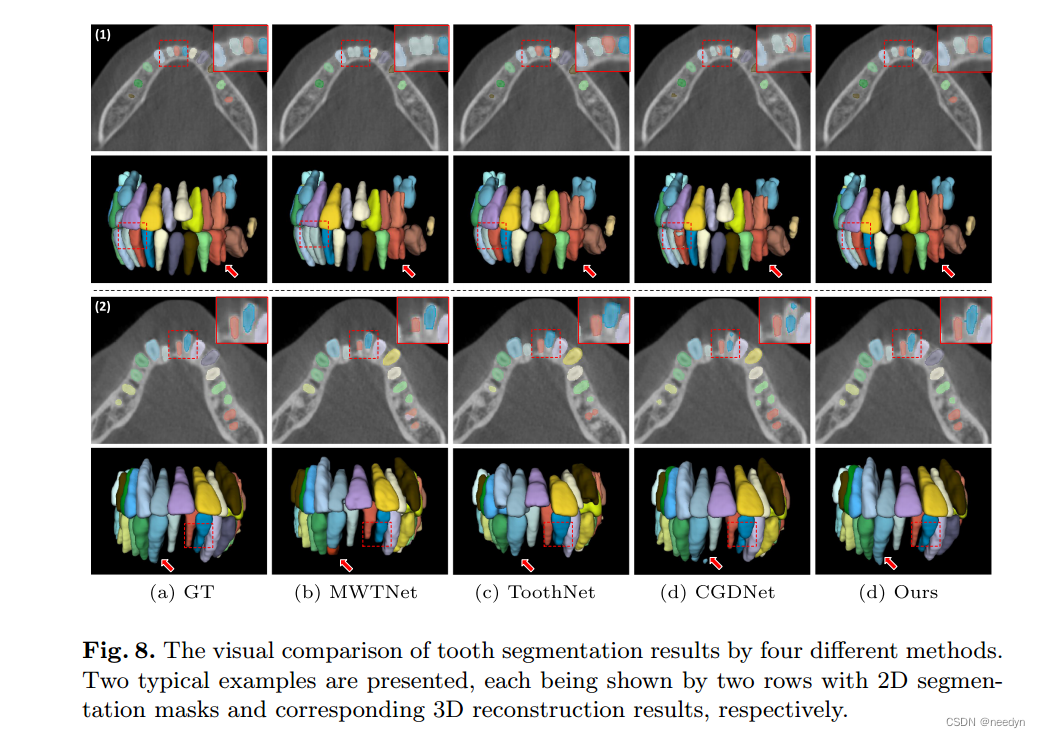
为了进一步证明我们的方法的优势,我们在图8中提供了两个典型例子的定量比较。可以发现,我们的方法生成的分割结果(最后一列)与ground truth(第一列)匹配更好,特别是在边界信号模糊的牙根尖和咬合面附近。值得注意的是,MWTNet(第二列)更容易导致牙齿分离失败。例如,在第一种情况下,两个门牙被视为同一物体,在第二种情况下,一个尖牙被分成两部分。这表明,由于牙齿之间的强度对比有限,牙齿边界本身并不是分割相邻牙齿的稳定信号。此外,牙网5和CDGNet14分别用边界框或中心点表示每颗牙齿,由于边界框或中心点的简单表示忽略了大多数牙齿拓扑特征,因此在牙齿边界和牙根区域附近会产生大量伪像。图8所示的视觉结果与定量对比结果一致,说明了分层形态引导的齿例分割框架的有效性和优势。
4 结论
在本文中,我们提出了一种新的基于CBCT图像的牙齿实例分割网络,该网络基于每个牙齿的分层形态表示,包括其质心和根尖(即点)标记、骨架、边界表面和体积掩模。具体来说,首先利用牙齿质心和骨架来检测和表示每颗牙齿。然后,提出了一种多任务学习机制,以获得较高的切分精度,特别是牙边界和牙根尖的切分精度。综合实验验证了我们的方法的有效性,表明它可以优于最先进的方法。这使得我们的方法在现实世界的诊所中有广泛应用的潜力
这篇关于Hierarchical Morphology-Guided Tooth Instance Segmentation from CBCT Images的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!