本文主要是介绍【论文阅读】Context-aware Cross-level Fusion Network for Camouflaged Object Detection(IJCAI2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文题目:Context-aware Cross-level Fusion Network for Camouflflaged Object Detection
论文地址:https://arxiv.org/pdf/2105.12555.pdf
代码地址:https://github.com/thograce/C2FNet
文章贡献:
1. 提出了一个新的伪装目标检测模型C2F-Net,它整合了跨层特征,并考虑了丰富的全局上下文信息;
2. 提出了一个上下文感知模块DGCM,该模块可从融合的特征中获取全局上下文信息;
3. 提出了一个有效的融合模块ACFM集成跨层特征,该模块将特征与MSCA提供的有价值的注意线索集成在一起。
1 背景与动机
论文解决的是伪装目标检测(camouflflaged object detection,COD)的问题。由于伪装,物体和周围环境之间的边界对比度非常低,从而导致难以准确识别:

2 方法框架
总体架构

使用Res2Net50来获取5个stage的特征,对高维度特征E3\E4\E5使用接收域块(receptive fifield block,RFB)来扩展接收域,捕获更丰富的特征。
之后将E4和E5经过RFB后的结果输入注意诱导的跨级融合模块(Attention-induced Cross-level Fusion Module ,ACFM)集成多尺度特征,再经过双分支全局上下文模块(Dual-branch Global Context Module ,DGCM)来获取上下文信息。同样的,对E3经过RFB后的结果也经过上述处理,最终得到预测结果。
其中,RFB的结构如下,输出Y的通道数为64:


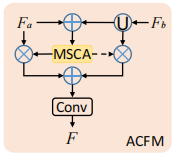
ACFM
由于相同的目标物体可能由于拍摄原因在图像中存在大小不同的问题,因此论文提出ACFM来集成多尺度特征。
![]()
对输入的2个特征Fa和Fb,将Fb上采样到与Fa相同的大小,进行相加的操作获得融合了不同尺度特征的总特征xy。将xy输入MSCA模块,获得输出结果wei,wei和wei的反向分别与Fa和上采样的Fb相乘,再将这两者相加,得到xo。最后xo经过3x3卷积,得到最终的输出特征F。

其中MSCA(Multi-Scale Channel Attention)的结构如下:
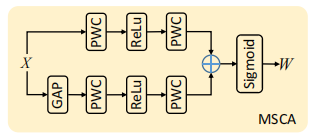
对输入的特征X经过一个双分支结构,分支1是局部注意分支,由1x1卷积+BN+ReLU+1x1卷积+BN组成。分支2是全局注意分支,由全局池化+1x1卷积+BN+ReLU+1x1卷积+BN组成。最后将双分支的结果经过加总,在经过sigmoid函数,得到输出特征W。

DGCM
全局上下文信息是提高伪装目标检测性能的关键,因此论文提出DGCM模块来获取上下文信息。
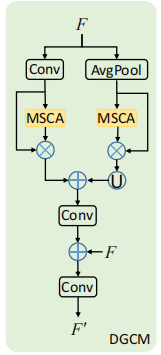
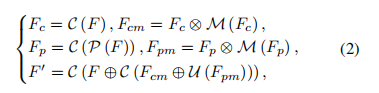
输入特征F经过两个分支,分支1对F进行3x3卷积操作得到Fc(CxHxW),再将Fc和Fc经过MSCA模块后的输入相乘,得到Fcm。分支2对F进行池化+3X3卷积操作得到Fp(CxW/2xH/2),跟Fc进行同样的操作后得到Fpm。之后将Fpm进行上采样并与Fcm相加,经过3x3卷积,加上特征F后再次经过3x3卷积,最终得到输出特征F'。

损失函数
![]()
使用加权二值交叉熵损失和加权IoU损失。

3 实验结果
数据集
- CHAMELEON,包含76张伪装图像;
- CAMO,1.25k图像,共8个类别;
- COD10K,共5066张图像,包含5个大类和69个子类。
评价指标
- MAE,评估归一化后的pred和GT之间的平均像素级相对误差;
- 加权F-measure,考虑加权精度和加权查全率的综合性能测度;
- S-measure,计算pred与GT之间的对象感知和区域感知结构相似性;
- E-measure,基于人类视觉感知机制来评估COD的整体和局部准确性。
与先进方法的比较:


各模块消融实验:


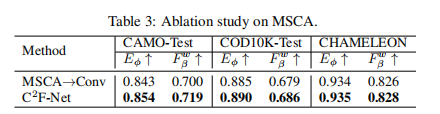
MSCA消融实验,第一列表示使用卷积操作替换MSCA模块:
这篇关于【论文阅读】Context-aware Cross-level Fusion Network for Camouflaged Object Detection(IJCAI2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






