本文主要是介绍【Python机器学习】线性模型——lasso,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
除了岭回归,还有一种正则化的线性回归是lasso,与岭回归相同,使用lasso也是约束系数使其接近于0,但方法不同,叫做L1正则化。L1正则化的结果是使用lasso时某些系数刚好为0。说明某些特征被模型完全忽略。
同样以波士顿房价数据集为例:
import mglearn.datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge,LinearRegression,Lasso
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif']=['SimHei']X,y=mglearn.datasets.load_extended_boston()
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0
)lasso=Lasso().fit(X_train,y_train)
print('训练集score:{:.2f}'.format(lasso.score(X_train,y_train)))
print('测试集score:{:.2f}'.format(lasso.score(X_test,y_test)))
print('用到的特征:{}'.format(np.sum(lasso.coef_!=0)))

从结果可以看出,Lasso在训练集和测试集上表现都很差,说明存在欠拟合,因为在数据集的105个特征中只用到了4个。
与岭回归类似,Lasso也存在一个正则化参数alpha,可以控制系数趋向于0的强度,为了减低欠拟合成都,可以减小alpha,同时,增加max_iter(运行迭代的最大次数)
lasso_001=Lasso(alpha=0.01,max_iter=100000).fit(X_train,y_train)
print('训练集score:{:.2f}'.format(lasso_001.score(X_train,y_train)))
print('测试集score:{:.2f}'.format(lasso_001.score(X_test,y_test)))
print('用到的特征:{}'.format(np.sum(lasso_001.coef_!=0)))lasso_00001=Lasso(alpha=0.0001,max_iter=100000).fit(X_train,y_train)
print('训练集score:{:.2f}'.format(lasso_00001.score(X_train,y_train)))
print('测试集score:{:.2f}'.format(lasso_00001.score(X_test,y_test)))
print('用到的特征:{}'.format(np.sum(lasso_00001.coef_!=0) 
alpha变小可以拟合一个更复杂的模型,在训练集和测试集上 的表现也更好,但是alpha不能设置的太小,否则就会消除正则化的效果,并出现过拟合,得到与线性回归类似的模型。
对不同alpha系数的结果进行可视化对比:
import mglearn.datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge,LinearRegression,Lasso
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif']=['SimHei']X,y=mglearn.datasets.load_extended_boston()
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0
)
lasso=Lasso().fit(X_train,y_train)
lasso_001=Lasso(alpha=0.01,max_iter=100000).fit(X_train,y_train)
lasso_00001=Lasso(alpha=0.0001,max_iter=100000).fit(X_train,y_train)
ridge_01=Ridge(alpha=0.1).fit(X_train,y_train)plt.plot(lasso.coef_,'s',label='lasso alpha=1')
plt.plot(lasso_001.coef_,'^',label='lasso alpha=0.01')
plt.plot(lasso_00001.coef_,'v',label='lasso alpha=0.0001')plt.plot(ridge_01.coef_,'o',label='岭 alpha=0.1')
plt.xlabel('index')
plt.ylabel('系数大小')
plt.ylim(-25,25)
plt.legend(ncol=2,loc=(0,1.05))
plt.show()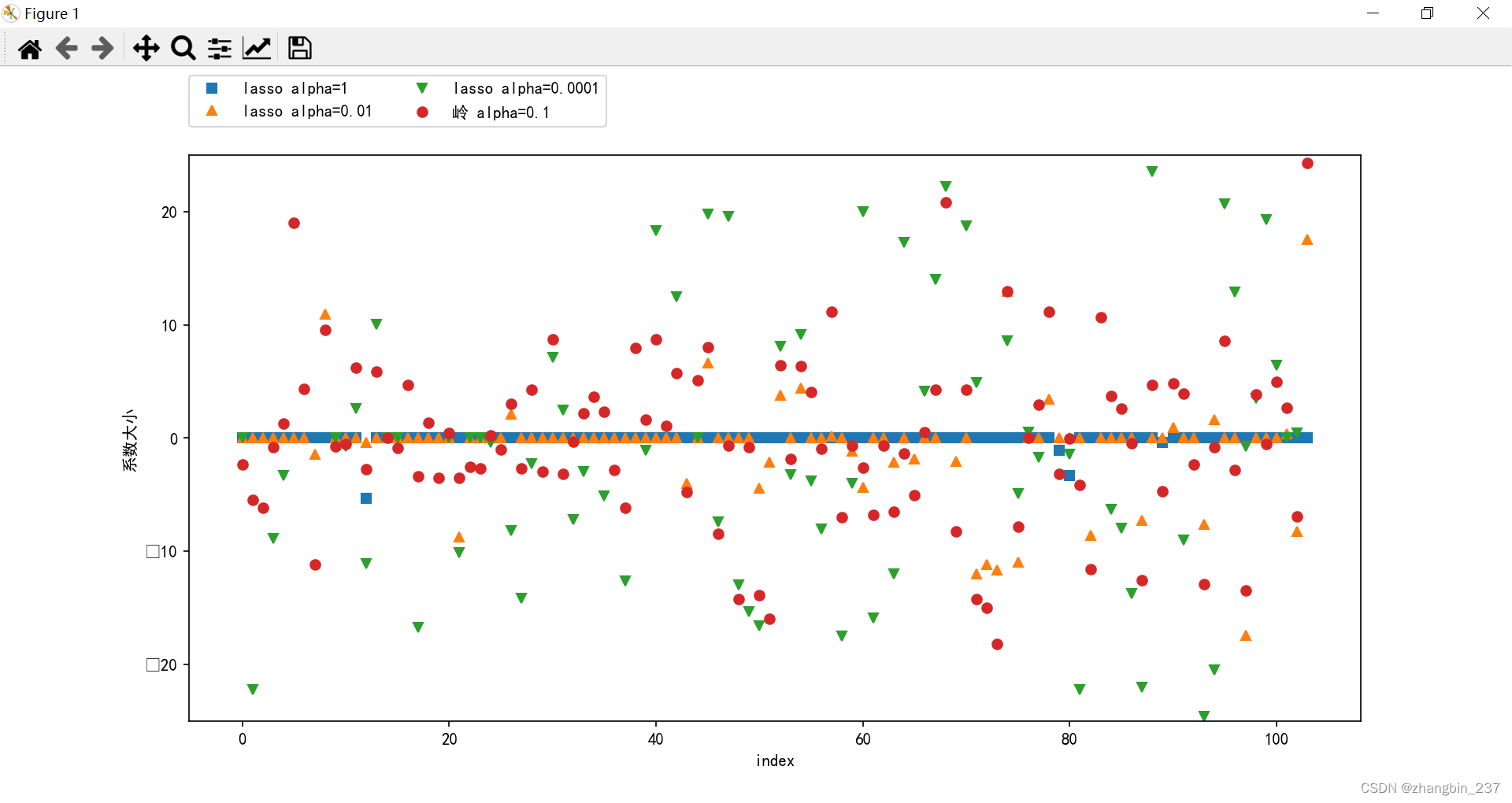
在alpha=1时,大部分系数大小都是0,而且其他系数也很小,alpha=0.01时,大部分特征等于0,alpha=0.0001时,大部分特征都不等于0且很大,就是一个正则化很弱的模型了 。
alpha=0.1的岭回归模型的预测功能与alpha=0.01的Lasso模型类似,但岭回归的所有系数都不为0。
在实践中,一般首选岭回归,但如果特征很多,且只有几个事重要的,那选择Lasso可能更好,且更容易解释。
这篇关于【Python机器学习】线性模型——lasso的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





