本文主要是介绍USB -- STM32F103缓冲区描述表及USB数据存放位置讲解(续),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
链接快速定位
前沿
1 0x40005C00和0x40006000地址的区别和联系
2 USB_BTABLE寄存器介绍
3 USB缓冲区描述表(SRAM)介绍
3.1 发送缓冲区地址寄存器n(n=[0..7])
3.2 发送数据字节数寄存器n(n=[0..7])
3.3 接收缓冲区地址寄存器n(n=[0..7])
3.4 接收数据字节数寄存器n(n=[0..7])
3.5 地址偏移和USB本地地址的联系
4 应用举例
5 512Byte SRAM讲解
链接快速定位
USB -- 初识USB协议(一)
源码下载请参考链接:USB -- STM32-FS-USB-Device驱动代码简述(二)
USB -- STM32F103虚拟串口bulk传输讲解(三)
USB -- STM32F103自定义HID设备及HID上位机中断传输讲解(四)
USB -- STM32F103 U盘(MassStorage)SDIO接口SCSI协议Bulk传输讲解(五)
USB -- STM32F103 USB DFU设备固件升级(IAP)控制传输讲解(六)
USB -- STM32F103 USB AUDIO(音频)Speak同步传输(Out传输)讲解(七)
USB -- STM32F103 USB AUDIO(音频)Microphone同步传输(In传输)讲解(八)
USB -- STM32F103 USB VIDEO(视频)Camera同步传输讲解(九)
USB -- STM32F103复合设备(HID+MassStorage)传输讲解(十)
前沿
我们在查看用户手册的时候,会发现USB的寄存器地址有两块,一块是0x40005C00 - 0x40005FFF,一块是0x40006000 - 0x400063FF,本章为大家讲解这两个寄存器地址有什么区别和联系。

1 0x40005C00和0x40006000地址的区别和联系
0x40005C00是USB寄存器的基地址,所有其他USB寄存器会相对于基地址有所偏移。
0x40006000是USB的SRAM的地址(可以理解为0x40006000地址处挂了一块512Byte的SRAM),也叫缓冲区描述表,此地址存放USB的数据信息,包括端点数据的相对地址、端点数据长度以及端点的数据。
因此0x40005C00和0x40006000地址没有必然的联系,只是0x40005C00是USB寄存器的基地址,0x40006000是存放USB数据是SRAM的起始地址。
接下来重点讲解0x40006000这块RAM。
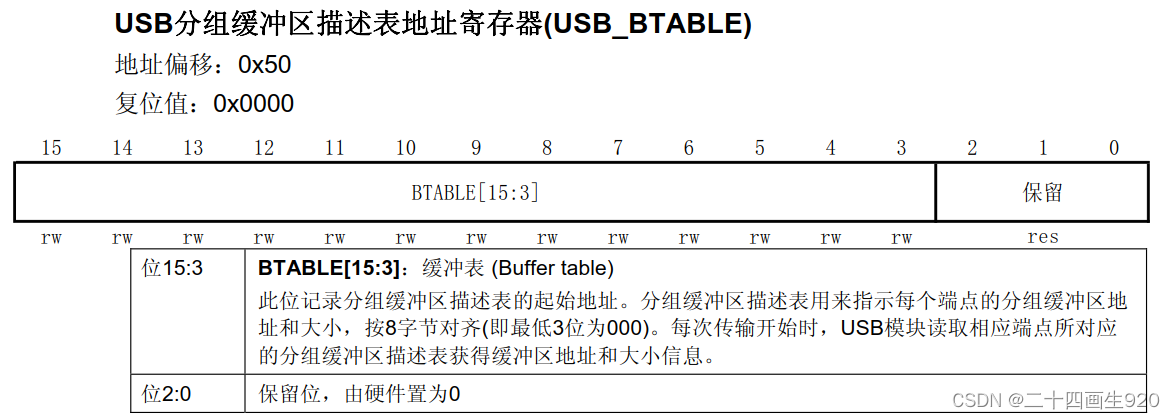
2 USB_BTABLE寄存器介绍
我们查看USB的用户手册的时候,会看到USB_BTABLE寄存器,该寄存器的目的是相对于0x40006000(SRAM)地址的偏移,默认不偏移。
举个例子,如果该寄存器的值为0x100,那么SRAM的起始地址就变成了0x40006200了(供应用程序使用的分组缓冲区地址需要乘以2才能得到缓冲区在微控制器中的真正地址),USB的数据就从0x40006200开始存储。一般情况下,这个值保持为0。
3 USB缓冲区描述表(SRAM)介绍
虽然缓冲区描述表位于分组缓冲区内,但仍可将它看作是特殊的寄存器,用以配置USB模块和微控制器内核共享的分组缓冲区的地址和大小。由于APB1总线按32位寻址,所以所有的分组缓冲区地址都使用32位对齐的地址,而不是USB_BTABLE寄存器和缓冲区描述表所使用的地址。 以下介绍两种地址表示方式:一种是应用程序访问分组缓冲区时使用的,另一种是相对于USB模块的本地地址。供应用程序使用的分组缓冲区地址需要乘以2才能得到缓冲区在微控制器中的真正地址。分组缓冲区的首地址为0x4000 6000。下面将描述与USB_EPnR寄存器相关的缓冲区描述表。
缓冲区描述表分为:
- 发送缓冲区地址寄存器n(n=[0..7])
- 发送数据字节数寄存器n(n=[0..7])
- 接收缓冲区地址寄存器n(n=[0..7])
- 接收数据字节数寄存器n(n=[0..7])
下图是一张缓冲区描述表的数据存放位置示意图,从表中可知,端点的发送缓冲区地址寄存器、发送数据字节数寄存器、接收缓冲区地址寄存器和接收数据字节数寄存器依次从0x40006000地址往上存储。

排完了发送缓冲区地址寄存器、发送数据字节数寄存器、接收缓冲区地址寄存器和接收数据字节数寄存器的地址之后,地址所存的数据又在哪里查看呢,我们接着往下面看。
3.1 发送缓冲区地址寄存器n(n=[0..7])

发送缓冲区地址寄存器就是存放发送数据的地址,比如此地址为0x20,那么我们就能够在0x40006000+0x20*2=0x40006040地址处填写发送的数据。
3.2 发送数据字节数寄存器n(n=[0..7])

也就是要发送的字节数,最大为1023个字节,但是我们的SRAM最大为512byte,还要去掉前面几个已使用的字节(存放数据地址和数据字节数),最多就只支持400多个字节,所以这里的1023字节需要根据SRAM的实际情况所决定。
3.3 接收缓冲区地址寄存器n(n=[0..7])

接收缓冲区地址寄存器就是存放接收数据的地址,比如此地址为0x20,那么我们就能够在0x40006000+0x20*2=0x40006040地址处读取USB接收到的数据。
3.4 接收数据字节数寄存器n(n=[0..7])

接收数据字节寄存器根据表161具体配置最大能够接收的数据的长度,如果超过此长度,USB模块将忽略超过的数据。
3.5 地址偏移和USB本地地址的联系
这里对地址偏移和USB本地地址做一个个人的理解,如果我们只是应用编程,我们完全不需要关心USB本地地址,我们只需要关注地址偏移。
这四个寄存器都只使用了16bit的数据,按照传统来说,地址偏移应该是(BTABLE=0,并且认为只有一个端点):
- 发送缓冲区地址寄存器地址=0x40006000
- 发送数据字节数寄存器地址=0x40006002
- 接收缓冲区地址寄存器地址=0x40006004
- 接收数据字节数寄存器地址=0x40006006
这就是USB本地地址
但是考虑这个MCU是一个32位寻址的MCU,所以需要做32位对齐,所以地址偏移变成了(BTABLE=0,并且认为只有一个端点):
- 发送缓冲区地址寄存器地址=0x40006000
- 发送数据字节数寄存器地址=0x40006004
- 接收缓冲区地址寄存器地址=0x40006008
- 接收数据字节数寄存器地址=0x4000600C
这就是地址偏移


4 应用举例
这里我们使用官方自带的USB虚拟串口例程进行讲解,不知道怎么下载和使用的读者可以参看博主的以下博客:
USB -- STM32-FS-USB-Device驱动代码简述(二)
USB -- STM32F103虚拟串口bulk传输讲解(三)
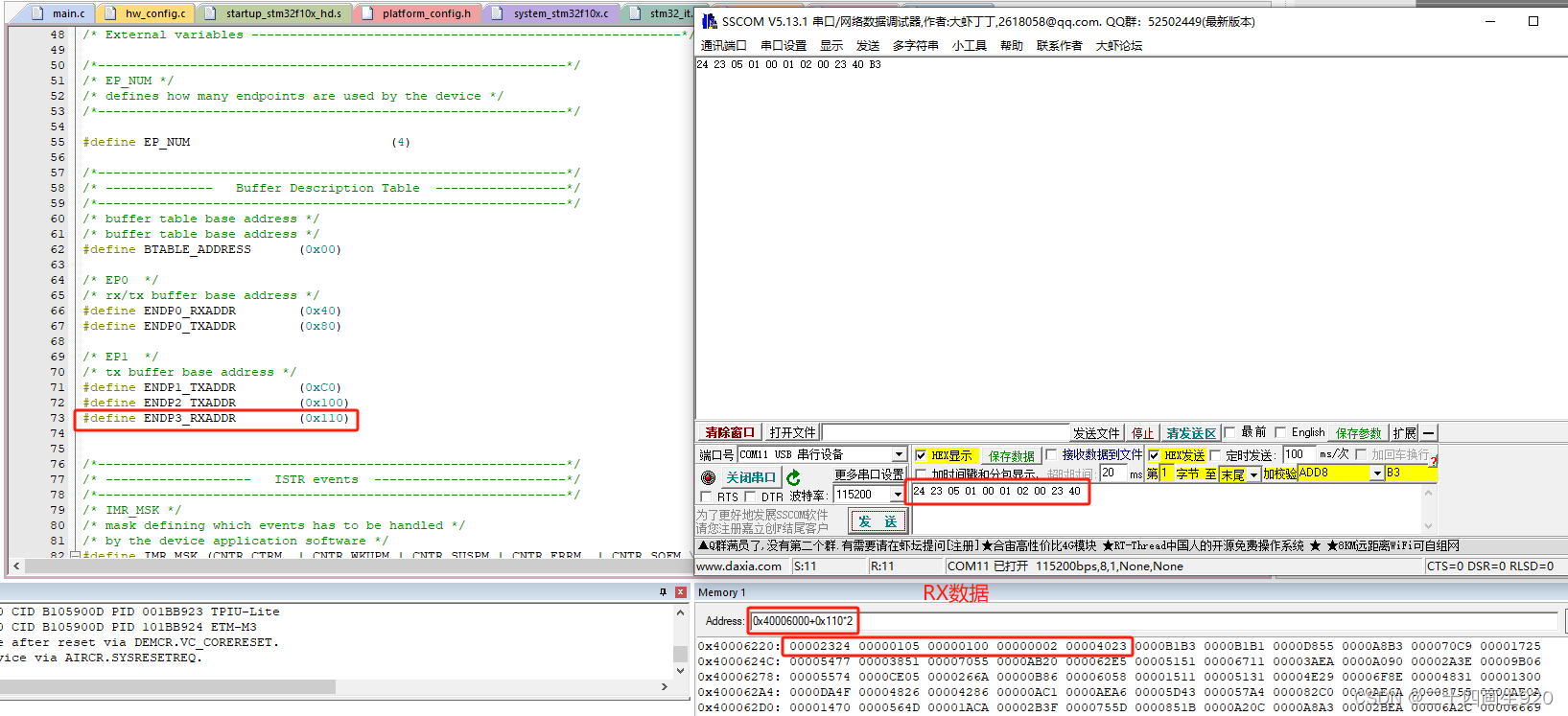
下载好程序,进入调试模式,查看定义的发送缓冲区地址寄存器0的值是0x80,定义的接收缓冲区地址寄存器0的值是0x40,发送缓冲区地址寄存器1的值是0xC0,发送缓冲区地址寄存器2的值是0x100,接收缓冲区地址寄存器3的值是0x110。

定义的端点0接收数据字节数寄存器0为0x40,也就是接收64字节的数据,端点3的接收数据字节数寄存器3为0x40,也就是接收64字节的数据。
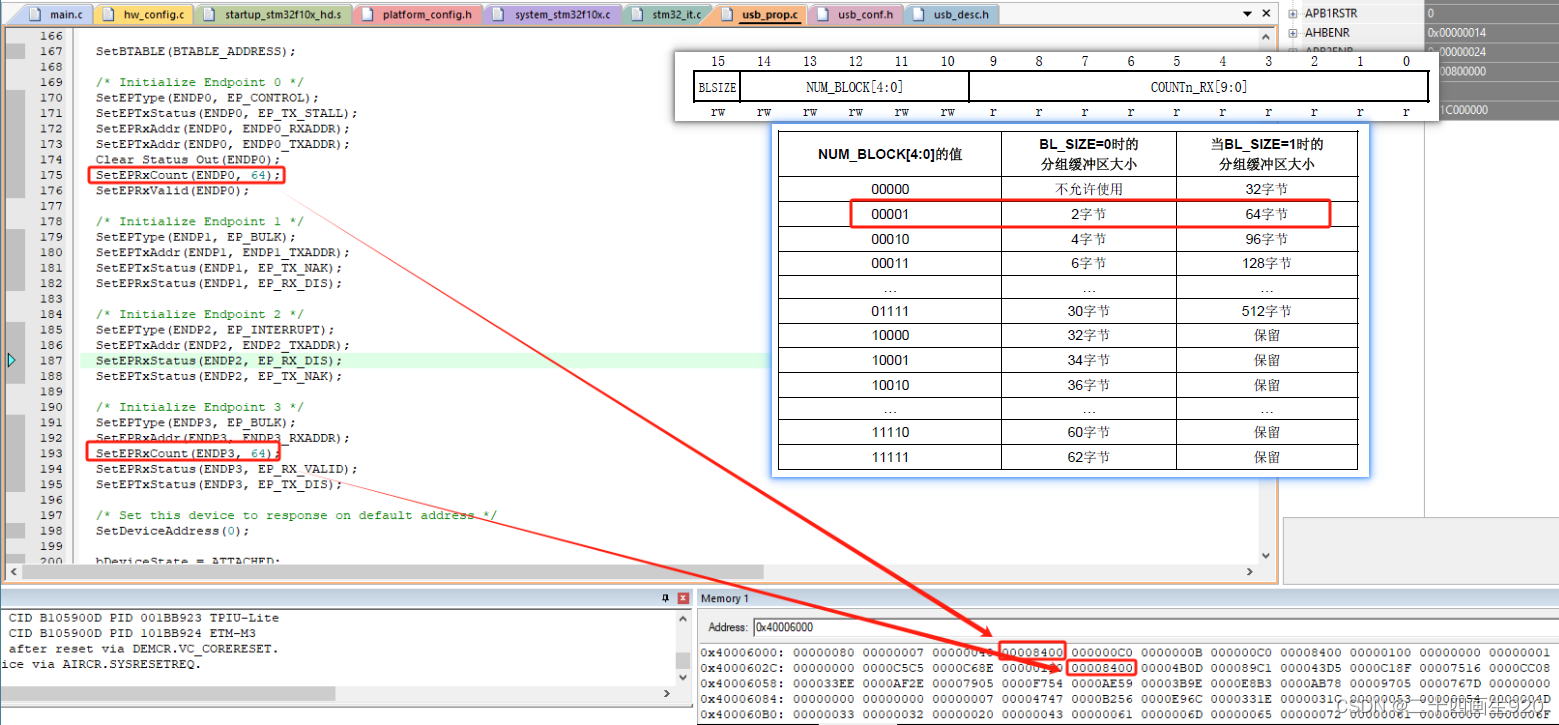
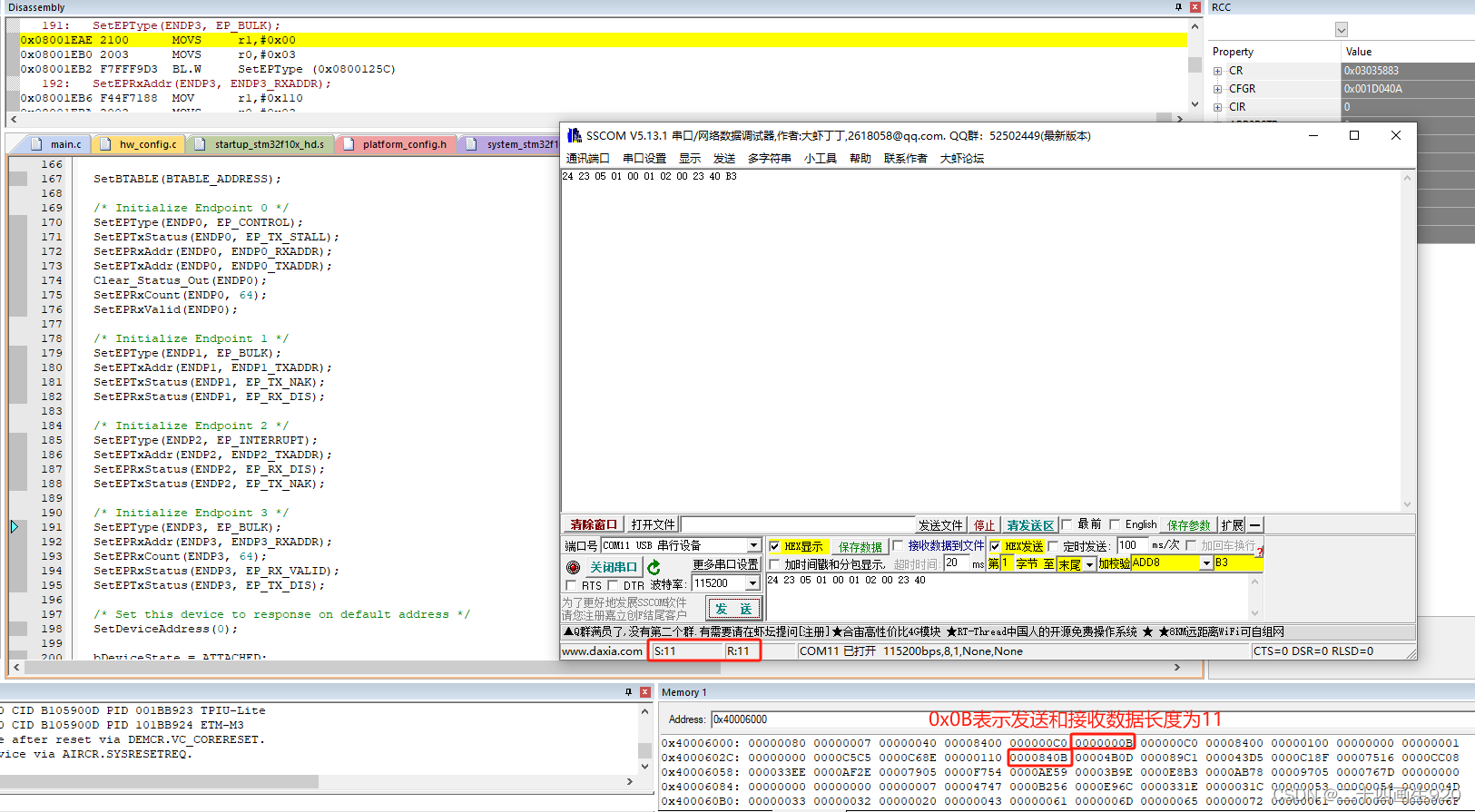
这里发送11个字节和接收11个字节的数据,查看到发送数据字节寄存器1为0x0B,接收数据字节寄存器3为0x840B,只看0-9位,所以为0x0B。

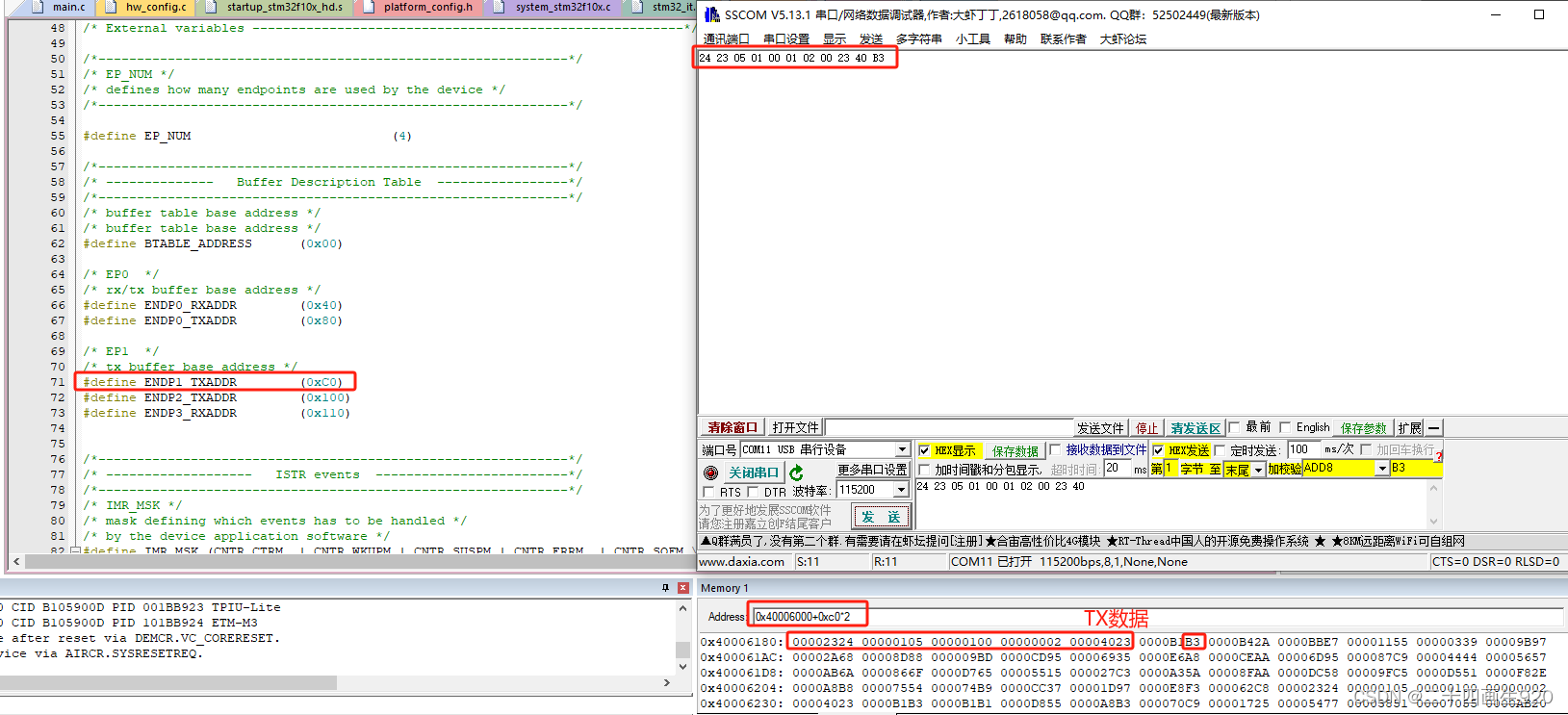
前面定义了发送和接收缓冲区的地址,截下来我们查看地址的值是否和串口助手的值一致,我们TX的地址为0xC0,RX的地址为0x110,根据手册,我们需要在0x40006000+0xC0*2地址处找到发送数据的起始地址,在0x40006000+0x110*2地址处找到接收数据的起始地址,见下图。
5 512Byte SRAM讲解
有的读者比较细心,发现ST的手册上面说的是USB的SRAM是512Byte的空间,为什么查看《存储器和总线架构》章节的时候,发现地址空间从0x40006000 - 0x400063FFF,这里是1024Byte,难道是ST的笔误吗,博主查看了最新的ST手册,发现也是这样写的。

经过一番研究,最终发现此SRAM只使用了低16位,此MCU是32位的MCU,如果只是使用低16位,想要达到512Byte,就需要增加一倍的地址空间,所以这里的地址空间才会是0x40006000 - 0x40003FFF。
这个问题同样可以解释以下问题:
我们可以看到ST的官方例程写的ENDP0_RXADDR和ENDP0_TXADDR值分别是0x40和0x80,实际数据的地址分别是0x40006000+0x40*2和0x40006000+0x80*2,这里两个地址相减得到0x40006000+0x80*2-0x40006000+0x40*2=0x80,此时是128个字节,那么就超了64个字节了,这样可能造成地址空间的浪费(端点0最大64字节)。
是否可以改为ENDP0_RXADDR和ENDP0_TXADDR值分别是0x40和0x60,这样0x40006000+0x60*2-0x40006000+0x40*2=0x40,刚好是64字节。其实是不可以这样修改的,因为SRAM使用的是低16位,高16位未使用,如果这里地址空间为0x40,实际可使用的空间为0x20。

这篇关于USB -- STM32F103缓冲区描述表及USB数据存放位置讲解(续)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








