本文主要是介绍基于多反应堆的高并发服务器【C/C++/Reactor】(中)创建一个TcpConnection实例 以及 接收客户端数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#CSDN 年度征文|回顾 2023,赢专属铭牌等定制奖品#
一、主线程反应堆模型的事件添加和处理详解
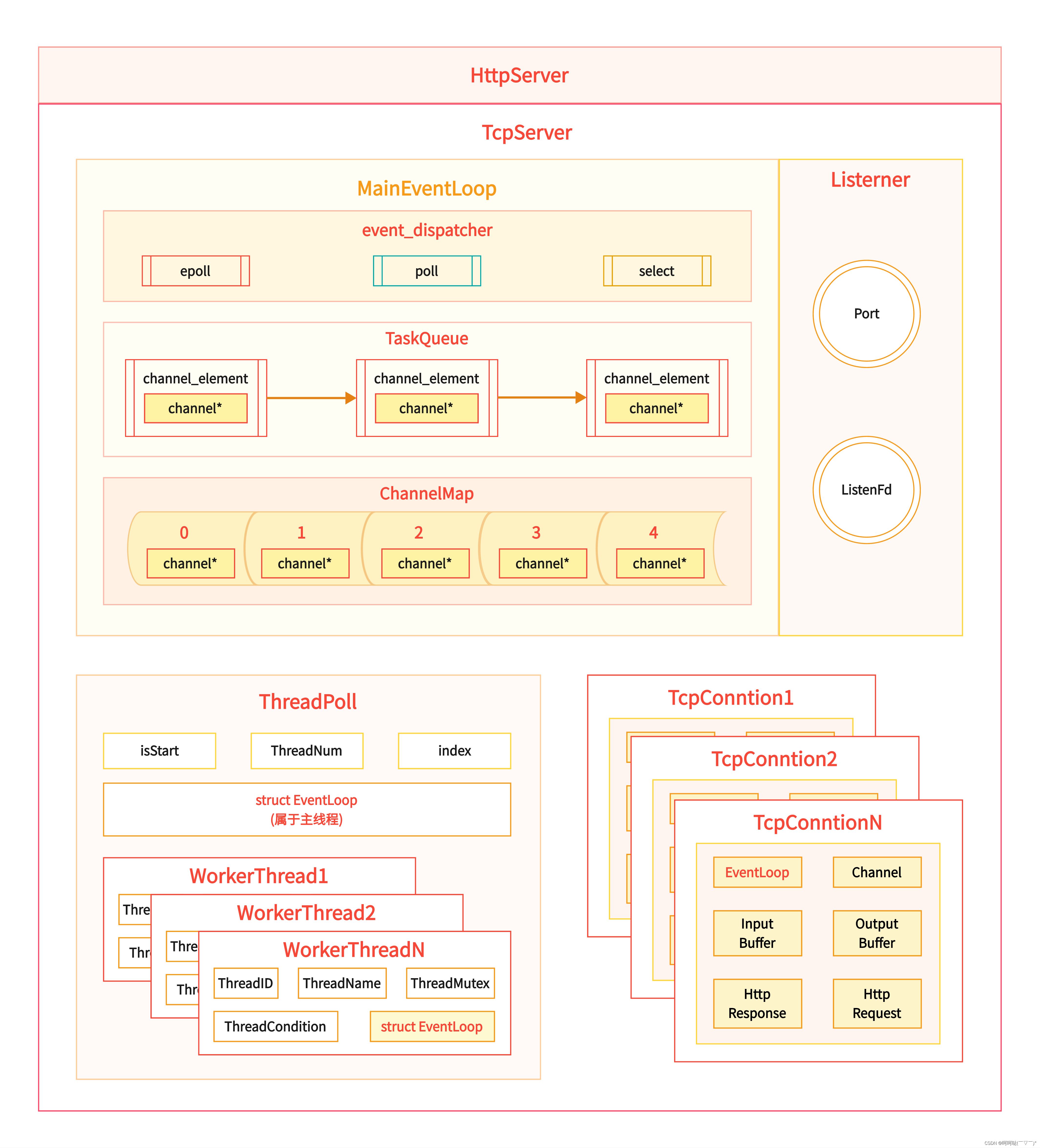
>>服务器和客户端建立连接和通信流程:
基于多反应堆模型的服务器结构图,这主要是一个TcpServer,关于HttpServer,主要是用了Http协议,核心模块是TcpServer。这里边有两种线程:主线程和子线程。子线程是在线程池里边,线程池的每个子线程都有一个反应堆模型,每个反应堆模型都需要有一个TcpConnection。
如果这个反应堆实例所属的线程是主线程,主线程是如何在这个反应堆模型里边工作的呢?在服务器端有一个用于监听的文件描述符ListenFd(简写为lfd),基于lfd就可以和客户端建立连接,如果想要让lfd去工作,就得把它放到反应堆模型里边,首先要对lfd封装成Channel类型,之后添加到TaskQueue这个任务队列里边,接着MainEventLoop就会遍历TaskQueue,取出对应的任务节点(ChannelElement),基于任务节点里边的type对这个节点进行添加/删除/修改操作。
补充说明:取出这个节点之后,判断这个节点的类型type,如果type==ADD,把channel里边的文件描述符fd添加到Dispatcher的检测集合中;如果type==DELETE,把channel里边的文件描述符fd从 Dispatcher的检测集合中删除;如果type==MODIFY,把channel里边的文件描述符fd在 Dispatcher的检测集合中的事件进行修改。主线程往属于自己的反应堆模型里边放的文件描述符是用于监听的,那么这个lfd肯定是要添加到Dispatcher的检测集合里边,所以操作肯定是添加操作(ADD)。
很显然,这个lfd需要添加到反应堆模型的Dispatcher里边,Dispatcher主要封装了poll/epoll/select模型,不管使用了这三个里边的哪一个,其实都需要对用于监听的文件描述符的读事件进行检测。在检测的时候,如果是epoll模型,它会调用epoll_wait函数; 如果是poll模型,它会调用poll函数;如果是select模型,它会调用select函数;通过这三个函数,传出的数据,我们就能够知道用于监听的文件描述符lfd它对应的读事件触发了。对应的读事件触发了,就可以基于得到的文件描述符(此处为lfd)。通过ChannelMap里边的fd(fd其实就是数组的下标)可以找到对应的channel地址,那么基于lfd就可以找到对应的channel地址,就能知道lfd所对应的读事件要干什么。也就是和客户端建立连接,也就可以得到一个通信的文件描述符(cfd)。
首先把用于通信的文件描述符封装成一个Channel类型,接着把channel封装到TcpConnection模块里边。另外,这个TcpConnection模块需要在子线程里边运行的,故需要通过子线程去访问线程池,从线程池找出一个子线程,每个子线程都有一个EventLoop,再把子线程的EventLoop也放到我们封装的TcpConnection模块里边。也就是把子线程的反应堆实例传给TcpConnection模块。
一定要注意:TcpConnection模块里边的EventLoop是属于子线程的,是从子线程传过来的一个反应堆模型的地址。然后就可以在TcpConnection模块里边通过Channel里边封装的通信的文件描述符(cfd)和客户端进行通信,就是接收数据和发送数据。关于通信的文件描述符的事件检测,读事件或者是写事件检测都是通过EventLoop来实现的。
二、创建一个TcpConnection实例 以及接收客户端数据
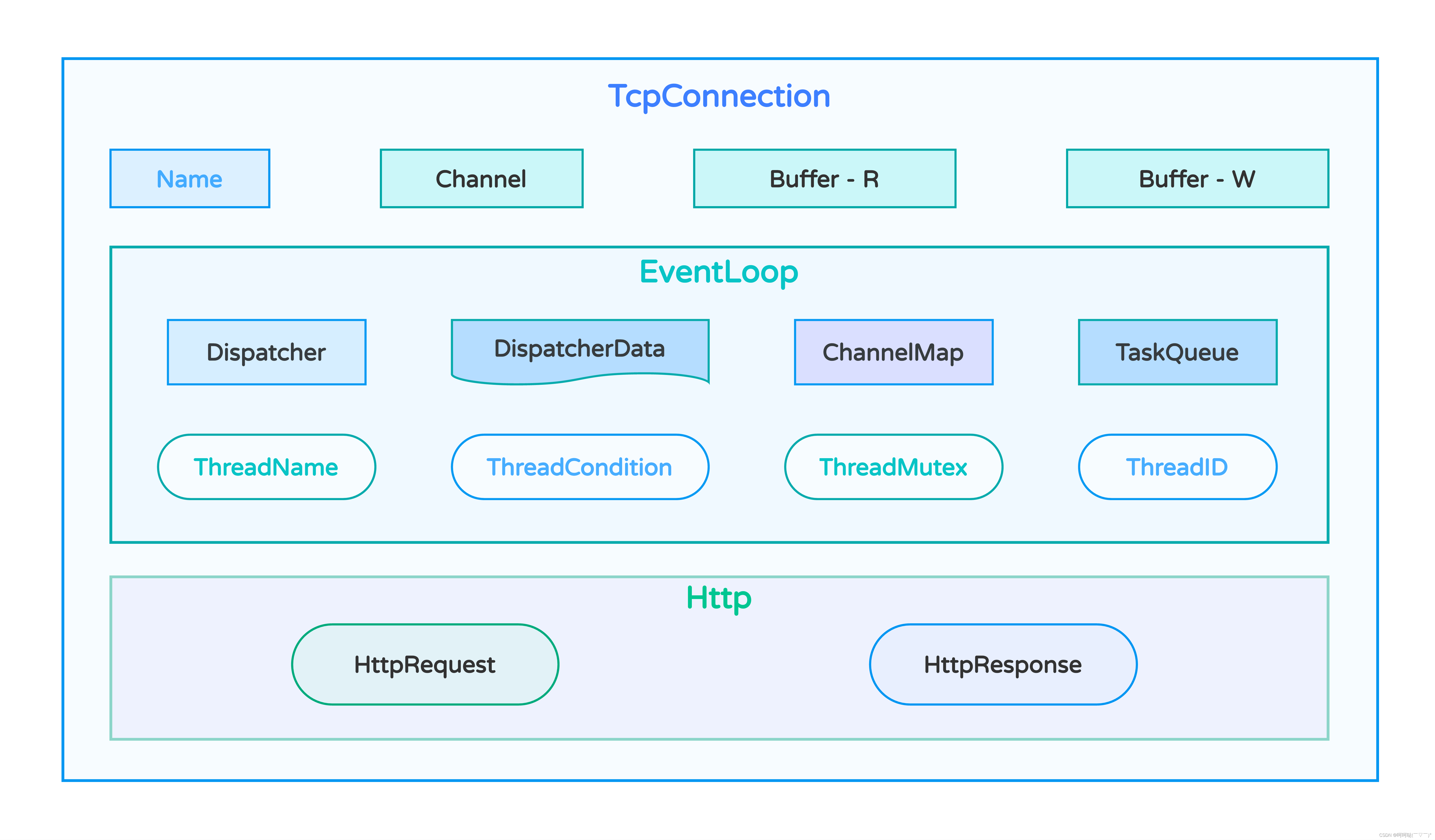
每个通信的文件描述符都对应一个TcpConnection,并且每个TcpConnection都对应一个子线程。假设说我现在有10个TcpConnection,4个线程,那么每个通信的文件描述符所对应的TcpConnection的Name是不一样的。但是,有可能有若干个TcpConnection是在同一个子线程里边执行的。在处理任务时,进行套接字通信的线程个数是有限的。
关于任务的分配:假如有六个任务,但是只有4个线程,那么把第一个任务给第一个子线程,再把第二个任务给第二个子线程,再把第三个任务给第三个子线程,再把第四个任务给第四个子线程。而把第五个任务就给到第一个子线程,把第六个任务给到第二个子线程,以此类推。
所以不同的TcpConnection有可能是在同一个线程里边被处理的,但是每个TcpConnection里边都有一个用于通信的文件描述符,这个文件描述符对应的连接的名字(Name)是唯一的。如果你发现出现相同的名字的,除非是这个文件描述符通信完了之后被释放了,而我们又建立了新的连接。被释放的这个文件描述符被复用了,所以我们就会发现当前的这个文件描述符对应的连接的名字和之前的某个文件描述符对应的连接的名字是相同的。
Name:用于标识每个连接的名称。当文件描述符被释放时,可以被重用,因此可能存在名称相同的连接。
struct TcpConnection {struct EventLoop* evLoop;struct Channel* channel;struct Buffer* readBuf;struct Buffer* writeBuf;char name[32];
};(1)创建一个TcpConnection实例
// 初始化
struct TcpConnection* tcpConnectionInit(int fd,struct EventLoop* evLoop);// 初始化
struct TcpConnection* tcpConnectionInit(int fd,struct EventLoop* evLoop) {struct TcpConnection* conn = (struct TcpConnection*)malloc(sizeof(struct TcpConnection));conn->evLoop = evLoop;struct Channel* channel = channelInit(fd,ReadEvent,processRead,NULL,conn);conn->channel = channel;conn->readBuf = bufferInit(10240); // 10kconn->writeBuf = bufferInit(10240); // 10ksprintf(conn->name,"TcpConnection-%d",fd);// 把channel添加到事件循环对应的任务队列里边eventLoopAddTask(evLoop,conn->channel,ADD);return conn;
}第一步:channel初始化
- 其中,会把用于通信的文件描述符cfd作为参数传入tcpConnectionInit里去,也就是fd为用于通信的文件描述符。将fd封装成channel。需要检测文件描述符什么事件呢?在服务器端通过文件描述符fd和客户端通信,如果客户端不给服务器发数据,服务器就不会给客户端回数据。因此在服务器端迫切想知道的有没有数据到达:就是有没有发过来请求数据。关于这个读事件我们需要指定一个processRead回调函数。
struct Channel* channel = channelInit(fd,ReadEvent,processRead,NULL,conn);第二步:把channel添加到事件循环对应的任务队列里边去
eventLoopAddTask(evLoop,conn->channel,ADD);(2)接收客户端数据 => processRead回调函数
- 回顾Buffer模块的接收套接字数据 bufferSocketRead函数

// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd);- bufferSocketRead函数实现功能:当调用这个bufferSocketRead函数之后,一共接收到了多少个字节
- bufferSocketRead函数具体细节:在这个函数里边,通过malloc申请了一块临时的堆内存(tmpbuf),这个堆内存是用来接收套接字数据的。当buf里边的数组容量不够了,那么就使用这块临时内存来存储数据,还需要把tmpbuf这块堆内存里边的数据再次写入到buf中。当用完了之后,需要释放内存。
- processRead回调函数
// 接收客户端数据
int processRead(void* arg) {struct TcpConnection* conn = (struct TcpConnection*)arg;// 接收数据int count = bufferSocketRead(conn->readBuf,conn->channel->fd);if(count > 0) {// 接收到了Http请求,解析Http请求...(待续写)}else {// 断开连接...(待续写)}
}总结:当文件描述符的读事件触发时,表示有客户端发送了数据。在通信的文件描述符内核对应的读缓冲区里边已经有数据了,我们就需要把数据从内核读到自定义的Buffer实例里边,就是conn(TcpConnection实例)里边的readBuf。故需要给这个processRead回调函数传递的实参是conn(TcpConnection实例)。因为在conn里边,既有需要的readBuf,也有文件描述符fd。这个fd就是通信的文件描述符。它已经被封装到了这个channel里边。
在processRead回调函数里边,先对参数arg进行类型转换。然后我们就可以接收数据了。接收到的数据最终要存储到readBuf里边。readBuf对应的是一个Buffer结构体,在这个Buffer结构体里边,我们提供了一个读取套接字数据的bufferSocketRead 函数:
// 接收数据
int count = bufferSocketRead(conn->readBuf,conn->channel->fd);我们只需要把readBuf(Buffer实例)传进来,也把文件描述符传进bufferSocketRead 函数。那么接收到的数据就存储到了这个readBuf结构体对应的那块内存里边。
这篇关于基于多反应堆的高并发服务器【C/C++/Reactor】(中)创建一个TcpConnection实例 以及 接收客户端数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







