本文主要是介绍【Redis】集群-数据分片算法集群扩容集群宕机集群缩容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前置内容
- 如何获取更大的空间
- 数据分片算法
- 哈希求余
- 一致性哈希算法
- 哈希槽分区算法 (Redis 使用)
- 集群扩容
- 集群宕机情况
- 集群缩容
前置内容
哨兵模式提⾼了系统的可⽤性,但是真正⽤来存储数据的还是redis主从节点,所有的数据都需要存储在单个主/从节点中,如果数据量很⼤, 接近超出了主节点/从节点所在机器的物理内存, 就可能出现严重问题了
- 虽然硬件价格在不断降低, ⼀些中⼤⼚的服务器内存已经可以达到 TB 级别了, 但是 1TB 在当 前这个 “⼤数据” 时代, 俨然不算什么, 有的时候我们确实需要更⼤的内存空间来保存更多的数据
关于集群的概念
广义的集群:只要是多个机器构成了分布式系统都可以称为是一个集群,比如前面的主从结构,哨兵模式,都可以称为是广义的集群
狭义的集群:redis提供的集群模式,在这个集群模式下,主要是要解决存储空间不足的问题(拓展存储空间)
如何获取更大的空间
加机器即可! 所谓 “⼤数据” 的核⼼, 其实就是⼀台机器搞不定了, ⽤多台机器来处理
Redis 的集群就是在上述的思路之下, 引⼊多组 Master / Slave , 每⼀组 Master / Slave 存储数据全集的 ⼀部分, 从⽽构成⼀个更⼤的整体, 称为 Redis 集群 (Cluster).
假定整个数据全集是 1TB, 引⼊三组 Master / Slave 来存储. 那么每⼀组机器只需要存储整个 数据全集的 1/3 即可
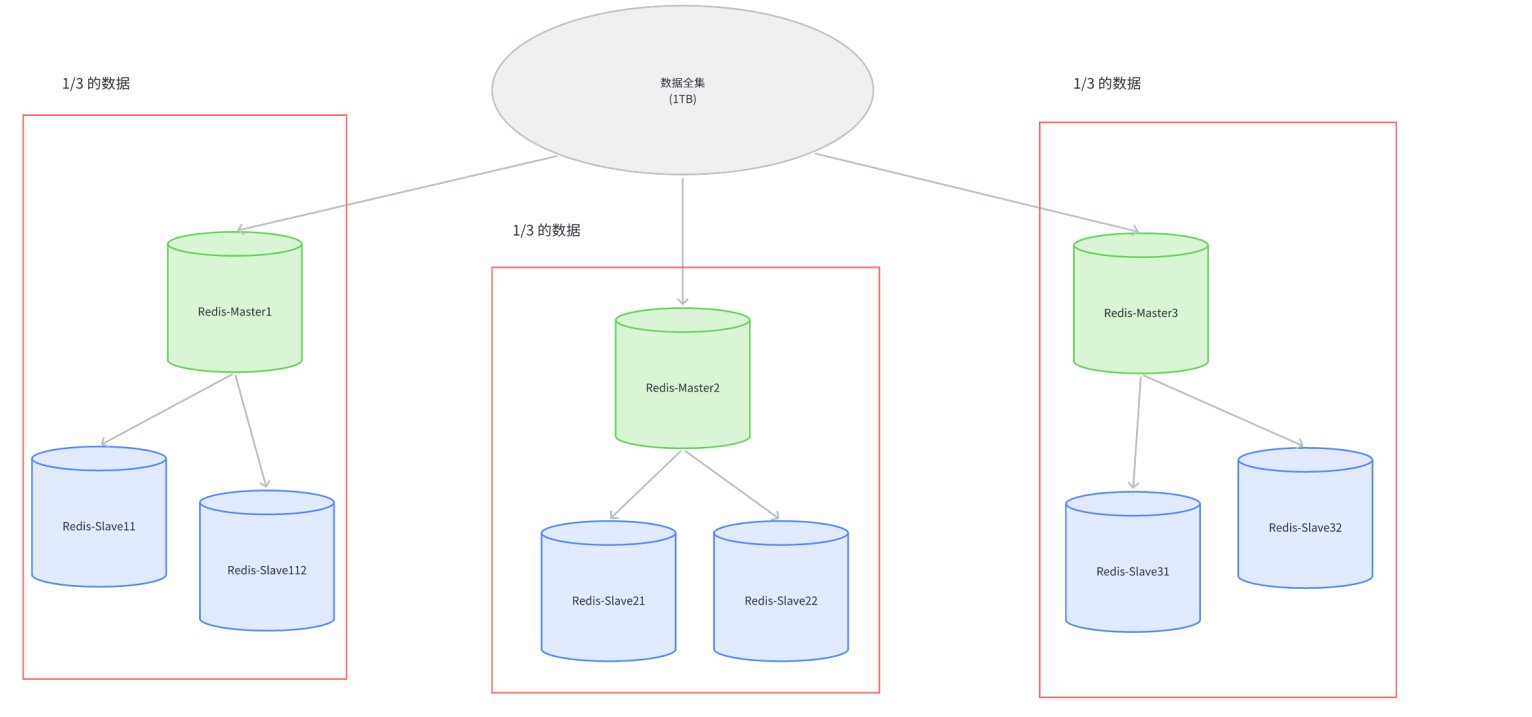
Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3…但是这三组机器存储的数据都是不同的
此时每个 Slave 都是对应 Master 的备份(当 Master 挂了, 对应的 Slave 会补位成 Master),每个红框部分都可以称为是⼀个分片,如果全量数据进⼀步增加, 只要再增加更多的分片即可解决.
数据量多了, 使⽤硬盘来保存不就⾏了?
硬盘只是存储多了, 但是访问速度是⽐内存慢很多的. 但是事实上, 还是存在很多的应⽤场景, 既希望存储较多的数据, ⼜希望有⾮常⾼的读写速度,比如搜索引擎
数据分片算法
redis集群的核⼼思路是⽤多组机器来存数据的每个部分,接下来的问题是:
- 给定⼀个数据 (⼀个具体的 key)那么这个数据应该存储在哪个分⽚上?
- 读取的时候⼜应该去哪个分⽚读取?
分片主要目的是为了提高存储能力,分片越多,能存的数据越多,成本越高
哈希求余
算法思想:设有 N 个分片, 使⽤ [0, N-1] 这样序号进⾏编号,针对某个给定的 key,先计算 hash 值(可以通过md5算法计算), 再把得到的结果 % N, 得到的结果即为分片编号
比如:N 为 3. 给定 key 为 hello, 对 hello 计算 hash 值,使用md5 算法得到的结果为
bc4b2a76b9719d91, 再把这个结果% 3结果为 0, 那么就把 hello 这个 key 放到 0 号分⽚上
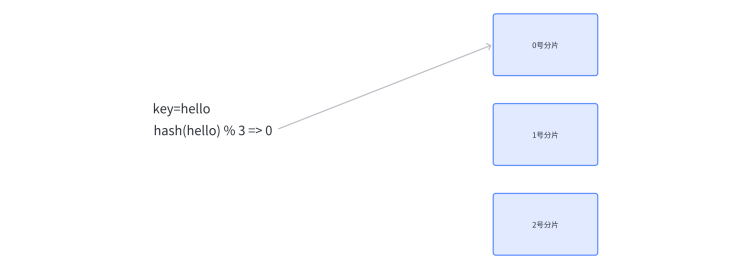
后续如果要取某个 key 的记录, 也是针对 key 计算 hash , 再对 N 求余, 就可以找到对应的分⽚编号
关于MD5加密算法
1.md5计算结果是定长的
2.md5计算结果是分散的,两个字符串哪怕大部分都相同,只有一个字符不相同,计算结果差别会很大
3.md5计算结果是不可逆的(加密)
- 给定原字符串很容易算出md5值,给定md5的值很难还原出原始的字符串
- 网络上的一些md5破解,其实是把一些常见的字符串的md5值提前算好保存下来,后续通过打表的方式根据md5值映射到原来的字符串,能不能查到就随缘了
优缺点
优点: 简单⾼效, 数据分配均匀
缺点: ⼀旦需要进⾏扩容, N 改变了, 原有的映射规则被破坏, 就需要让节点之间的数据相互传输, 重新排列来满⾜新的映射规则. 此时需要搬运的数据量是⽐较多的, 开销较⼤
例子:当引⼊⼀个新的分⽚, N 从 3 => 4 时, ⼤量的 key 都需要重新映射. (某个key % 3 和 % 4 的结果不⼀样, 就映射到不同机器上

整个扩容⼀共 21 个 key, 只有 3 个 key 没有经过搬运, 其他的 key 都是搬运过的
一致性哈希算法
为了降低上述的搬运开销, 能够更⾼效扩容, 业界提出了 “⼀致性哈希算法”,将key 映射到分⽚序号的过程不再是简单求余了, ⽽是改成以下过程
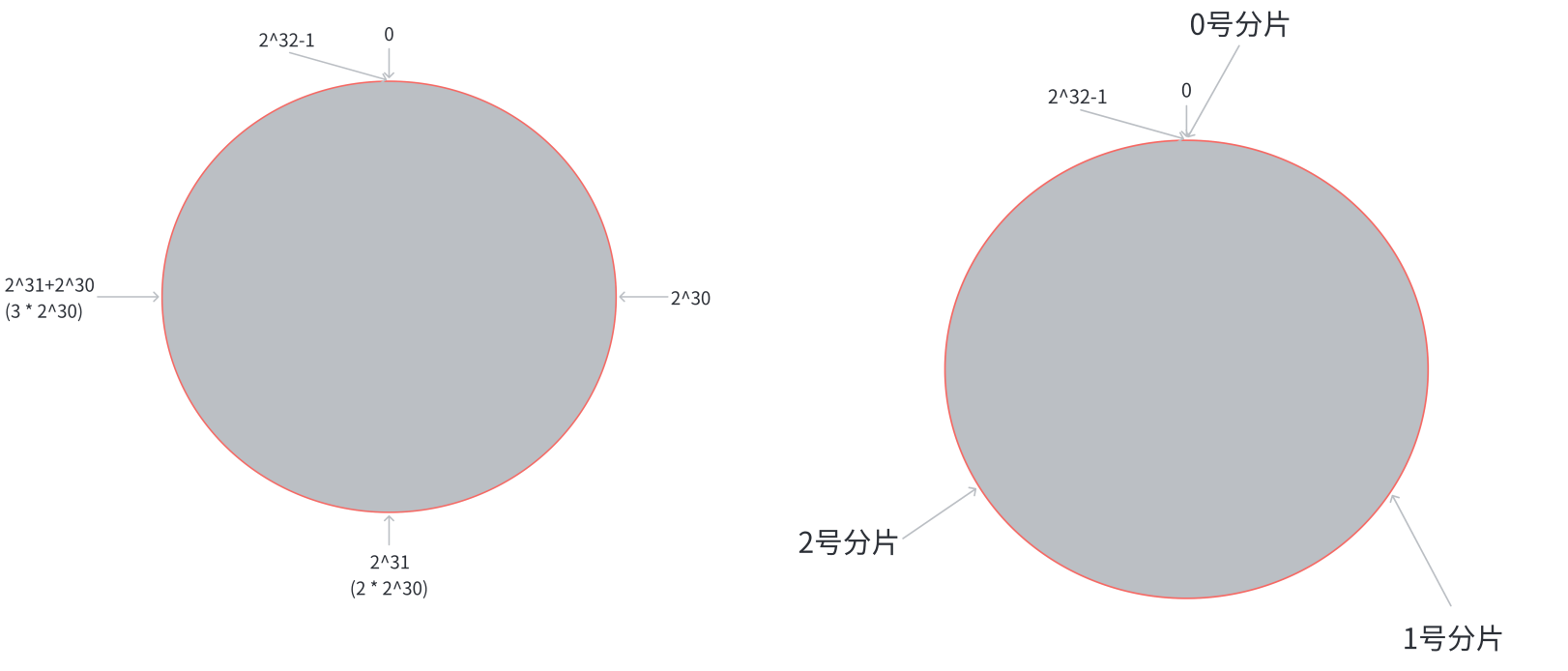
第⼀步: 把 [ 0 , 2 32 − 1 ] [0,2^{32} - 1] [0,232−1] 这个数据空间, 映射到⼀个圆环上. 数据按照顺时针⽅向增⻓
第⼆步, 假设当前存在三个分⽚, 就把分⽚放到圆环的某个位置上
第三步, 假定有⼀个 key, 计算得到 hash 值 H,从 H 所在位置, 顺时针往下找, 找到的第⼀个分⽚, 即为该 key 所从属的分⽚
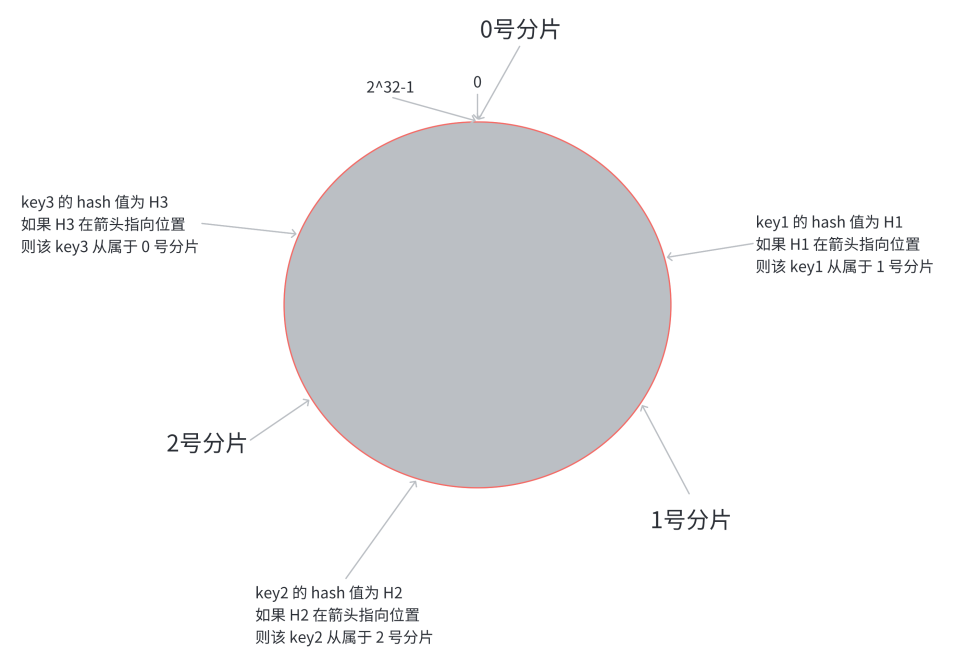
相当于, N 个分⽚的位置, 把整个圆环分成了 N 个管辖区间. Key 的 hash 值落在某个区间内, 就归对 应区间管理.
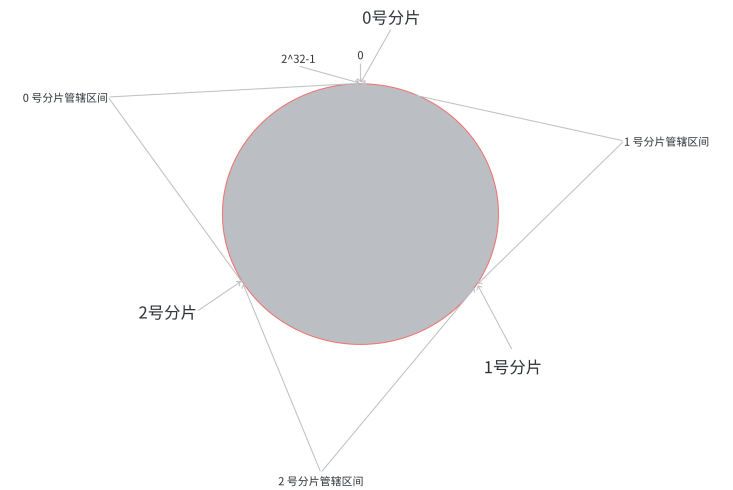
在这个情况下, 如果扩容⼀个分⽚, 如何处理呢
原有分⽚在环上的位置不动, 只要在环上新安排⼀个分⽚位置即可,比如:只需要把 0 号分⽚上的部分数据, 搬运给 3 号分⽚即可,1 号分⽚和 2 号分⽚管理的区间都是不变的,虽然仍然有搬运成本,但是比哈希求余时的搬运成本更低

优点: 降低了扩容时数据搬运的规模, 提⾼了扩容操作的效率,在一致性哈希的设定下,将数据从哈希求余的交替出现变成了连续出现
缺点: 数据分配不均匀 (有的多有的少, 数据倾斜)
哈希槽分区算法 (Redis 使用)
为了解决上述问题 (搬运成本高 和 数据分配不均匀),Redis的集群当中引⼊了哈希槽 (hash slots) 算法
//crc16也是一种hash算法 16384 = 2^14 = 16 * 1024 = 16k
hash_slot = crc16(key) % 16384
相当于是把所有哈希值映射到 16384 个槽位上, 也就是哈希槽的 [ 0 , 16383 ] [0, 16383] [0,16383]范围,然后再把这些槽位⽐较均匀的分配给每个分片. 每个分片的节点都需要记录自己有哪些槽位
假设当前有三个分⽚, ⼀种可能的分配⽅式:
0 号分⽚: [ 0 , 5461 ] [0, 5461] [0,5461], 共 5462 个槽位, 1 号分⽚: [ 5462 , 10923 ] [5462, 10923] [5462,10923], 共 5462 个槽位, 2 号分⽚: [ 10924 , 16383 ] [10924, 16383] [10924,16383],共 5460 个槽位
这⾥的分⽚规则是很灵活的. 每个分⽚持有的槽位也不⼀定是连续的,每个分片的节点都会使用位图这样的数据结构来表示自己持有哪些槽位. 对于 16384 个槽位来说, 需要 2048 个字节(2KB) 大小的内存空间表示,16384个比特位,用每一位0/1来区分当前分片是否持有该槽位
假设现在需要扩容:⽐如新增⼀个 3 号分⽚, 就可以针对原有的槽位进⾏重新分配
可以把之前每个分⽚持有的槽位, 各拿出⼀点, 分给新分⽚,⼀种可能的分配⽅式如下:
0 号分⽚:$ [0, 4095]$,共 4096 个槽位,1 号分⽚: [ 5462 , 9557 ] [5462, 9557] [5462,9557], 共 4096 个槽位,2 号分⽚:$ [10924, 15019] ,共 4096 个槽位, 3 号分⽚ : , 共 4096 个槽位 ,3 号分⽚: ,共4096个槽位,3号分⽚: [4096, 5461] + [9558, 10923] + [15019, 16383]$,共 4096 个槽位
然而在实际使⽤ Redis 集群分⽚的时候, 不需要⼿动指定哪些槽位分配给某个分片, 只需要告诉某个分片应该持有多少个槽位即可, Redis 会⾃动完成后续的槽位分配, 以及对应的 key 搬运的⼯作
问题1:Redis 集群是最多有
16384个分⽚吗
并不是,如果⼀个分⽚只有⼀个槽位, 此时很难保证数据在各个分片上的均衡性 => 有的槽位可能有多个key,有的槽位可能没有key
key先映射到槽位,再映射到分片的,如果每个分片包含的槽位比较多,并且槽位个数相当,就可以认为是包含的key数量相同。如果每个分片包含的槽位非常少,槽位个数不一定能直观的反应到key的数目
Redis 的作者建议集群分⽚数不应该超过 1000,⽽且16000 这么⼤规模的集群, 本⾝的可⽤性也是⼀个⼤问题. ⼀个系统越复杂, 出现故障的概率是越⾼的
问题2:为什么是16384个槽位
1)节点之间通过⼼跳包通信. ⼼跳包中包含了该节点持有哪些 slots. 这个是使⽤位图这样的数据结构 表⽰的. 表⽰ 16384 (16k) 个 slots, 需要的位图⼤⼩是 2KB. 如果给定的 slots 数更多了, ⽐如 65536 个了, 此时就需要消耗更多的空间, 8 KB 位图表⽰了. 8 KB, 对于内存来说不算什么, 但是在频繁的⽹ 络⼼跳包中, 还是⼀个不⼩的开销的
2) Redis 集群⼀般不建议超过 1000 个分⽚. 所以 16k 对于最⼤ 1000 个分⽚来说是⾜够⽤ 的, 同时也会使对应的槽位配置位图体积不⾄于很⼤
集群扩容
随着业务的发展, 现有集群很可能⽆法容纳⽇益增⻓的数据. 此时给集群中加⼊更多新的机器, 就可以使 存储的空间更⼤了.
所谓分布式的本质, 就是使⽤更多的机器, 引⼊更多的硬件资源
1) 把新的主节点加⼊到集群
2)重新分配 slots
- 在搬运 key 的过程中, 对于那些不需要搬运的 key, 访问的时候是没有任何问题的
- 对于需要搬运的 key, 进⾏访问可能会出现短暂的访问错误 (因为key 的位置出现了变化),但是随着搬运完成, 这样的错误⾃然就恢复了
3)给新的主节点添加从节点
- 光有主节点了, 此时扩容的⽬标已经初步达成. 但是为了保证集群可⽤性, 还需要给这个新的主节点添加 从节点, 保证该主节点宕机之后, 有从节点能够顶上
集群宕机情况
1.某个分片所有的主节点和从节点都挂了
- 此时该分片就无法提供数据服务了
2.某个分片上主节点挂了,但是没有从节点
- 此时该分片就无法提供数据服务了
3.超过半数的主节点挂了
- 因为此时master挂了但是还有slave做补充,此时突然一系列的master都挂了,说明集群遇到了非常严重的问题,需要进行检查
集群缩容
主要思路:把一些节点拿掉,减少分片的数量
第⼀步: 删除从节点
第⼆步: 重新分配 slots
第三步: 删除主节点
这篇关于【Redis】集群-数据分片算法集群扩容集群宕机集群缩容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






