本文主要是介绍Re-ID----读罗浩《基于深度学习的行人重识别研究进展》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基本概念与发展过程
| (1)Re_ID 是图像检索的一个子问题,主要应用于视频监控,智能安防 |
| (2) 1)早期手工设计视觉特征(如何获得更好的相似度度量),现在主要用深度学习的方法自动进行。 A:手工特征:颜色,HOG(Histogram of oriented gradient), SIFT (Scale invariant feature transform),LOMO (Local Maximal Occurrence). B:相似度度量:XQDA (Cross-view Quadratic Discriminant Analysis), KISSME (Keep It Simple and Straightforward Metric Learning) C:传统方法的缺点:难以适应复杂场景,大数据量,传统度量学习求解困难。 2)现在利用深度学习,用欧式距离即可进行相似度度量。初期为单帧图片的全局特征。根据损失的类型不同可以分为:表征学习和度量学习。后引入局部特征和序列特征。最近的GAN在扩充数据集和解决图像偏差问题上有不错的效果。 整体来说,现大多数为监督学习,而迁移学习,半监督学习,无监督学习也值得研究。Re_ID主要是行人检测和行人重识别。只不过行人检测技术已经成熟,大家将其作为先验知识。将重点放在重识别。 |
主要数据集
| 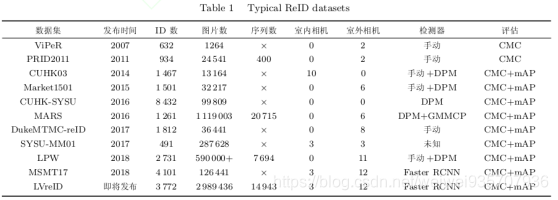
其中有红外数据集。 各数据集的行人检测方法:Deformable Part-based Model(DPM),手动标注,Faster RCNN 检测器 准确度的评估:累计匹配(Cumulative Match Characteristics, CMC), 平均准确度(Mean Average Precision, mAP)。 |
行人重识别的深度学习方法
- 基于表征学习的方法(representation learning):通过看成分类问题和验证问题。网络的最后一层softmax层的结果用以计算表征学习的损失,而前一层FC则是特征向量层。分类问题是输入一张图片来输出它可能分类的概率,而验证问题是输入两张图片,判断是否属于同一行人。
- 分类网络:常用ID损失和属性损失。即不仅使用行人ID作为标签(IDE),还要使用行人的属性。
ID损失和属性损失的算法一样: 
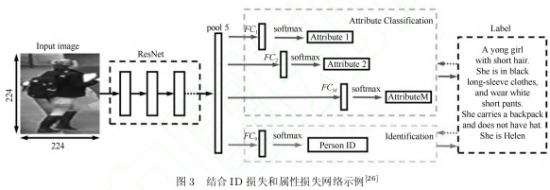
|
| 2)验证网络:将经过同一个CNN得到的两张图片的特征向量输入验证网络(两个神经元,多输入,单输出) 验证损失为:(v为网络输出结果向量) 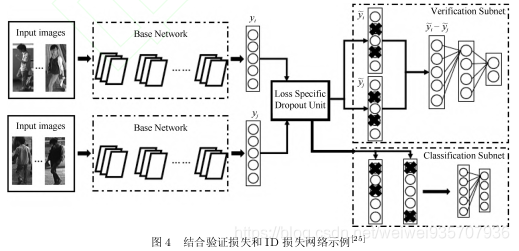
|
| 基于度量学习的方法:将图片从原始域映射到同一个特征域,定义一个距离度量函数(向前传播时。 使用欧式距离,余弦距离或者曼哈顿距离等等),通过最小化度量损失寻找最优映射(使同一行人距离尽可能小,不同行人距离尽可能大的CNN)。 | 对比损失 (contrastive loss) | y=1同一行人,y=0不同行人 | 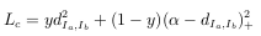 | | 三元组损失(triplet loss) | 正负样本距离对和超参 | 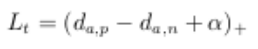 | | 改进的三元组损失(improved triplet loss) | 加入正样本对之间距离 | 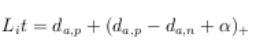 | | 四元祖损失(quadruplet loss) | 两个负样本对。推开负样本对时不会太影响固定图片的特征。 | 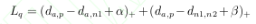 |
难样本:非常不像的正样本和非常像的负样本。 和表征的对比: | 度量 | 表征 | | 看作是在特征空间的聚类 | 看作特征空间的分界面 | | 末尾无需FC,即对ID数量不敏感。 适合大量数据 | (反之) |
|
| |
| - 基于局部特征的方法:
| | 描述 | 难点 | 解决 | | 图像切块 | 将图像从上到下几等分(头,上身,腿等)。使用孪生网络,将被分割好的送入长短时记忆网络,最后融合所有局部特征。 | 对齐要求较高。 | 动态对齐网络 AlignedReID | | 骨架关键点定位 | 人体姿态关键点进行局部特征对齐 | 需要额 外的姿态估计模型 | Spindle Net 网络 (提取14个关键点,题取7个区域。同原始图,共8个图得到特征。将8个特征的在不同尺度连接。) (2)全局 - 局 部对齐特征描述子 (Global-Local-Alignment De-scriptor, GLAD) |
CNN自动提取全局特征,但仅使用全局性能不能达到要求。 |
| - 基于视频序列的方法
单帧的方法要求图像质量很高 , 这对于相机的布置和使用的场景是一个非常大的限制 。用所有序列的平均池化,最大池化,作为最终特征。这是一个急需解决的问题,但是和单帧方法比无论思路还是多样性都有一定距离。 需要考虑的问题有: 1)帧与帧间运动信息 2)更好特征融合 3)图像帧质量判断 可能解决的问题: 1)噪声较大 2)背景复杂 使用的方法和思路: 融合图像内容和运动信息:CNN提取空间特征,RNN提取时序特征(如:累计运动背景网络AMOC。每一帧送Spat Nets取全局特征,相邻两帧送Moti Nets提取光流特征,两者融合到RNN,通过AMOC题取融合两个信息的特征)。每一帧图像提取特征不同,为跟好融合有DFGP(同前一样,单个深度特征之后,取池化。通过离平均值最近找出最稳定帧,之后即可手动规定权重),深度学习注意力机制。 对图像帧进行质量判断:RQEN以姿态估计为先验知识,对每一帧进行质量判断,将先验结果输出到网络,诱导网络学习更多高质量图像,将高质量打上权重然后叠加。 |
| - 基于GAN的学习方法:
| 解决问题 | 描述 | 方法 | | 扩展训练集 | | | | 训练集风格转换 | 两个风格相互转换,不断对抗,直至收敛。推理阶段则输入图片,进行风格转换。优点是保留了图片的ID信息。 | CycleGAN | | 减小场景差异 | 前景分割,尽量保留行人信息 | PTGAN | | 行人姿态校正 | PGNAN在Market1501 和 DukeMTMC-reID上有最高的rank1 | PGNAN |
-
|
- 各种方法比较

| 表征和度量 | 优点 | 缺点 | | 表征学习 | 数据量不大容易收敛 模型鲁棒性强 训练时间短 | ID数量过大时,网络最后一层是维度非常高FC,参数过多,想要收敛十分困难。 | | 度量学习 | 1.方便扩展新数据集,无需因为ID数量调整网络结构,可以适应数目较大数据集 | 1.收敛相对困难,虚较为丰富调参经验。 2.收敛训练时间较长。 |
现在很多方法也是将二者相结合进行训练。 | 全局和局部 | 优点 | 缺点 | | 全局特征 | 1.速度快,适合帧率较高实际应用 | 1.池化使图像空间信息特征丢失,姿态对不齐,图片不完整,易误识别。 | | 局部特征 | 信息较为完整,较少对不齐等 | 1.需要额外姿态点模型 | | 二者较为互补,通常联合使用。对全局和局部分别题取,拼接在一起作为最终特征。 (1.Spindle Net 全局特征和七个局部最后融合 2.AlignedReID 则分别计算两个图像的全局和局部特征距离,加权作为最后空间距离。 3.RQEN也可近似看成) |
| 挑战 | 描述 | 方法 | | 跨视角造成的姿态多变问题 | 角度位置不一,姿态多变 | 预训练的姿态模型实现姿态对齐。 1)GLAD 和 SpindleNet 2)PSE | | 行人图片分辨率变化 | 拍摄距离不一致 | SING | | 行人图片遮挡问题 | 失去部分行人特征,引入干扰特征 | 行人姿态模型估计可视部分,对可视部分进行特征题取融合 2)深度空间特征重建方法。完整图片经过稀疏表达后可以与不完整图片比较 | | 图像域变化的跨模态重识别 | 相机,天气,时间,城市,RGB相机与红外相机 | GAN 深度零填充模型 |
典型算法比较 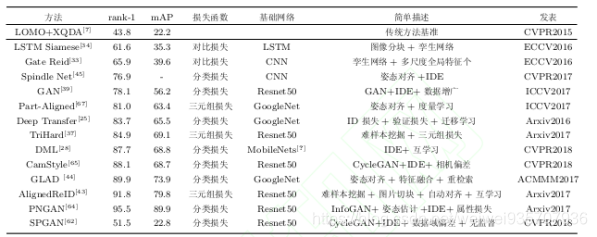
挑战与未来 | 方向 | 描述 | 解决 | | 构建更加适应真实环境的数据库 | 数据集不同,模型结果差距加大。 | 1)高质量提高鲁棒性 2)GAN造数据集 | | 半监督,无监督和迁移学习方法 | 1)标注代价较高。 2)每个场景训练专门模型很低效 | 1)半监督,无监督 2)迁移学习 | | 构造更加强大的特征 | 重排序时间换取准确度 | 使网络关注关键局部信息,即合理的局部特征 丰富的序列特征 | | 丰富场景下的行人重识别 | 室外室内 无人超市,商场,地铁 夜间 | | | 深度网络的可解释性 | 颜色和轮廓谁影响大 姿态如何对其 光线如何矫正 | 深度学习的可视化技术 | | 行人重识别与行人检测行人跟踪的结合 | 不再将行人检测作为先验条件 跨摄像头多目标跟踪是Re_ID一个直接应用。 | |
|
这篇关于Re-ID----读罗浩《基于深度学习的行人重识别研究进展》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





