本文主要是介绍Deep Learning for Extreme Multi-label Text Classification阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概述
模型
Dynamic max pooling
损失函数
Hidden Bottleneck layer
实验参数设置
实验结果
概述
Extreme multi-label就是说总的标签量非常多, 成千上万甚至数百万.
Extreme multi-label text classification主要难点在于数据稀疏, 并且计算量较大(标签太多).
本文作者对textcnn进行改进, 使其在extreme multi-label text classification问题上获得更好的效果.
模型

模型是基于text-cnn改进的.
创新点:
- dynamic max pooling.
- 改进了损失函数
- 在pooling和输出层之间加了一个bottleneck layer, 减小模型规模, 加快训练.
Dynamic max pooling
text-cnn是对每个feature map做max pooling, 所以每个feature在pooling之后只得到一个特征.
作者认为, 这样做pooling, 如果句子很长, 会损失很多信息, 并且没有利用任何位置信息.
对此, 作者提出使用Dynamic max pooling, 对于每个feature map, pooling生成p个特征. 具体做法如下,
- 对于一个包含m个词的句子, 把这个句子分成p块, 每一块分别做max-pooling然后进行拼接.
损失函数
损失函数使用binary cross-entropy, 而不是 softmax cross-entropy
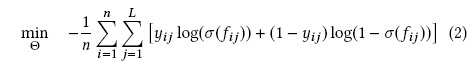
Hidden Bottleneck layer
其实就是在pooling层和ouput层之间加了个全连接
实验
参数设置
- 卷积核大小:{2, 4, 8}
- 每种卷积核数量(也就是输出通道数): 对于小数据集是128, 大数据集32
- dropout: 0.5
- bottleneck layer: 512
实验结果

这篇关于Deep Learning for Extreme Multi-label Text Classification阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







