本文主要是介绍摘要抽取算法——最大边界相关算法MMR(Maximal Marginal Relevance) 实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NLP(自然语言处理)领域一个特别重要的任务叫做——文本摘要自动生成。此任务的主要目的是快速的抽取出一篇文章的主要内容,这样读者就能够通过最少的文字,了解到文章最要想表达的内容。由于抽取出来的摘要表达出了文章最主要的含义,所以在做长文本分类任务时,我们可以采用文本摘要算法将长文本的摘要抽取出来,在采用短文本分类模型去做文本分类,有时会起到出奇的好效果。
文本摘要自动生成算法
文本摘要抽取算法主要分为两大类:
- 一种是生成式:生成式一般采用的是监督式学习算法,最常见的就是sequence2sequence模型,需要大量的训练数据。生成式的优点是模型可以学会自己总结文章的内容,而它的缺点是生成的摘要可能会出现语句不通顺的情况。
- 另一种是抽取式:常见的算法是 textrank,MMR(Maximal Marginal Relevance),当然也可以采用深度学习算法。抽取式指的摘要是从文章中抽出一些重要的句子,代表整篇文章的内容。抽取式的优点是生成的摘要不会出现语句不通顺的情况,而它的缺点是缺乏文本总结能力,生成的摘要可能出现信息丢失的情况。
最大边界相关算法MMR(Maximal Marginal Relevance)
MMR算法又叫最大边界相关算法,此算法在设计之初是用来计算Query文本与被搜索文档之间的相似度,然后对文档进行rank排序的算法。算法公式如下: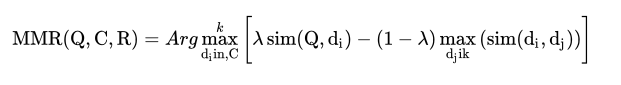
其中 Q 是 Query文本,C 是被搜索文档集合,R是一个已经求得的以相关度为基础的初始集合,
指的是搜索返回的K个的句子的索引。
当我们做摘要抽取时,我们需要换个角度去看公式中的字符表示,在摘要抽取时:
- 公式中的 Q和C 都代表整篇文档。
- 而
则代表文档中的某个句子。
- 公式中的
指的是文档中的某个句子和整篇文档的相似度。
指的是 文档中的某个句子和已经抽取的摘要句子的相似度。
仔细观察下公式方括号中的两项,其中前一项的物理意义指的是待抽取句子和整篇文档的相似程度,后一项指的是待抽取句子和已得摘要的相似程度,通过减号相连,其含义是希望:抽取的摘要既能表达整个文档的含义,有具备多样性 。而
则是控制摘要多样性程度的一个超参数,你可以根据自己的需求去调节。
MMR摘要抽取算法python实现
使用sklearn 的 CountVectorizer 接口计算句子的词袋向量,然后定义余弦相识度函数计算句子和文档直接相似度,最后实现MMR算法。
from sklearn.feature_extraction.text import CountVectorizer
from pprint import pprint
import operatordef encode_sen(sen,corpus):"""input: sentence and corpus output : bag of words vector of sentence """cv = CountVectorizer()cv = cv.fit(corpus)vec = cv.transform([sen]).toarray()return vec[0]def cosin_distance(vector1, vector2):"""input: two bag of words vectors of sentence output : the similarity between the sentence"""dot_product = 0.0normA = 0.0normB = 0.0for a, b in zip(vector1, vector2):dot_product += a * bnormA += a ** 2normB += b ** 2if normA == 0.0 or normB == 0.0:return Noneelse:return dot_product / ((normA * normB) ** 0.5)def doc_list2str(doc_list):"""transform the doc_list to str """docu_str = ""for wordlist in doc_list:docu_str += " ".join(wordlist)return docu_strdef MMR(doc_list,corpus):"""input :corpus and the docment you want to extract output :the abstract of the docment """Corpus = corpusdocu = doc_list2str(doc_list)doc_vec = encode_sen(docu,Corpus)QDScore = {}###calculate the similarity of every sentence with the whole corpusfor sen in doc_list:sen = " ".join(sen)sen_vec = encode_sen(sen,corpus)score = cosin_distance(sen_vec,doc_vec)QDScore[sen] = scoren = 2alpha = 0.7Summary_set = []while n > 0:MMRScore = {}### select the first sentence of abstractif Summary_set == []:selected = max(QDScore.items(), key=operator.itemgetter(1))[0]Summary_set.append(selected)Summary_set_str = " ".join(Summary_set)for sentence in QDScore.keys():#calculate MMR if sentence not in Summary_set:sum_vec = encode_sen(Summary_set_str, corpus)sentence_vec = encode_sen(sentence,corpus)MMRScore[sentence] = alpha * QDScore[sentence] - (1 - alpha) * cosin_distance(sentence_vec,sum_vec)selected = max(MMRScore.items(), key=operator.itemgetter(1))[0]Summary_set.append(selected)n -= 1# print(len(Summary_set))return Summary_set测试MMR算法
在网上找了一个关于2018年世界杯后姆巴佩转会巴黎的新闻,进行摘要抽取。
import jieba
docment = "伴随着世界杯的落幕,俱乐部联赛筹备工作又成为主流,转会市场必然也会在世界杯的带动下风起云涌,不过对于在本届赛事上大放异彩的姆巴佩而言,大巴黎可以吃一颗定心丸,世界杯最佳新秀已经亲自表态:留在巴黎哪里也不去。在接受外媒采访时,姆巴佩表达了继续为巴黎效忠的决心。“我会留在巴黎,和他们一起继续我的路途,我的职业生涯不过刚刚开始”,姆巴佩说道。事实上,在巴黎这座俱乐部,充满了内部的你争我夺。上赛季,卡瓦尼和内马尔因为点球事件引发轩然大波,而内马尔联合阿尔维斯给姆巴佩起“忍者神龟”的绰号也让法国金童十分不爽,为此,姆巴佩的母亲还站出来替儿子解围。而早在二月份,一场与图卢兹的比赛,内马尔也因为传球问题赛后和姆巴佩产生口角。由此可见,巴黎内部虽然大牌云集,但是气氛并不和睦。内马尔离开球队的心思早就由来已久,而姆巴佩也常常与其它俱乐部联系在一起,在躲避过欧足联财政公平法案之后,巴黎正在为全力留下二人而不遗余力。好在姆巴佩已经下定决心,这对巴黎高层而言,也算是任务完成了一半。本届世界杯上,姆巴佩星光熠熠,长江后浪推前浪,大有将C罗、梅西压在脚下的趋势,他两次追赶贝利,一次是在1/8决赛完成梅开二度,另一次是在世界杯决赛中完成锁定胜局的一球,成为不满20岁球员的第二人。另外他在本届赛事中打进了4粒入球,和格列兹曼并列全队第一。而对巴黎而言,他们成功的标准只有一条:欧冠。而留下姆巴佩,可以说在争夺冠军的路上有了仰仗,卡瓦尼在本届世界杯同样表现不错,内马尔虽然内心波澜,但是之前皇马官方已经辟谣没有追求巴西天王,三人留守再度重来,剩下的就是图赫尔的技术战术与更衣室的威望,对图赫尔而言,战术板固然重要,但是德尚已经为他提供了更加成功的范本,像团结法国队一样去团结巴黎圣日耳曼,或许这才是巴黎取胜的钥匙。"
sen_list = docment.strip().split("。")
sen_list.remove("")
doc_list = [jieba.lcut(i) for i in sen_list]
corpus = [" ".join(i) for i in doc_list]
corpus
结果如下:从抽取的摘要基本可以得知本篇报道主要是想说明世界杯后姆巴佩将转化巴黎,而且可能性很大。和全文主要想表达的含义基本吻合。证明MMR算法确实厉害。
MMR(doc_list,corpus)
abstract
结语
这里笔者只是简单的介绍了MMR摘要算法的原理,以及简单实现。代码部分也不是此算法的最优实现。真正能够落地的摘要算法,一定是融合了更多的其他思想,如textrank,文本句子和标题的相似度,或者引入词向量或者句子向量来更好的表达句子语义等等。本文只是想让大家初步了解摘要算法的一些知识,以及感受一下摘要算法的神奇之处。
这篇关于摘要抽取算法——最大边界相关算法MMR(Maximal Marginal Relevance) 实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




