本文主要是介绍某和医院招采系统web端数据爬取, 逆向js,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标网址:https://zbcg.sznsyy.cn/homeNotice
测试时间: 2024-01-03
1 老规矩,打开Chrome无痕浏览,打开链接,监测网络,通过刷新以及上下翻页可以猜测出数据的请求是通过接口frontPageAnnouncementList获取的,查看返回可以看出来数据大概率是经过aes加密的,如图:
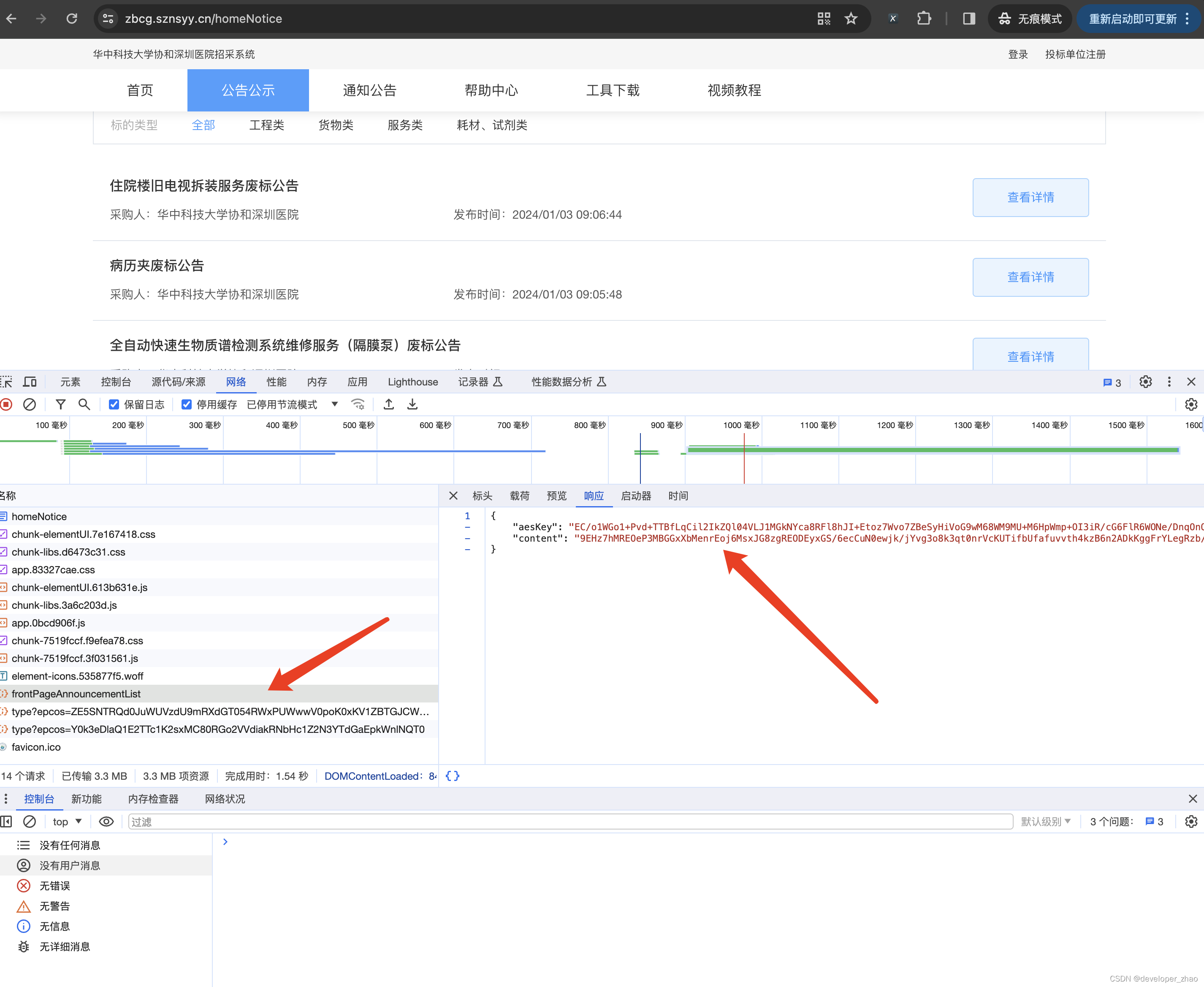
通过查看该请求的请求头可以发现该请求里携带了Aeskey请求头,对应值为字符串,看到这些信息其实已经可以大概猜出来加密方式了,应当为aes加密,请求头携带加密key方式来进行数据的传输,接下来我们进行断点来验证我们的猜想

2 复制aesKey字符串去js文件中搜索下出现的地方,分析下可能的代码段,并下断点,通过上下翻页来查看是否断下
3 通过翻页发现代码此处断下,分析参数可以看到该方法应当是对应的网络请求,所需参数如下:{"noticeName":null,"pageNum":3,"pageSize":10,"tenderCategory":"6","noticeType":null,"tenderClass":null}
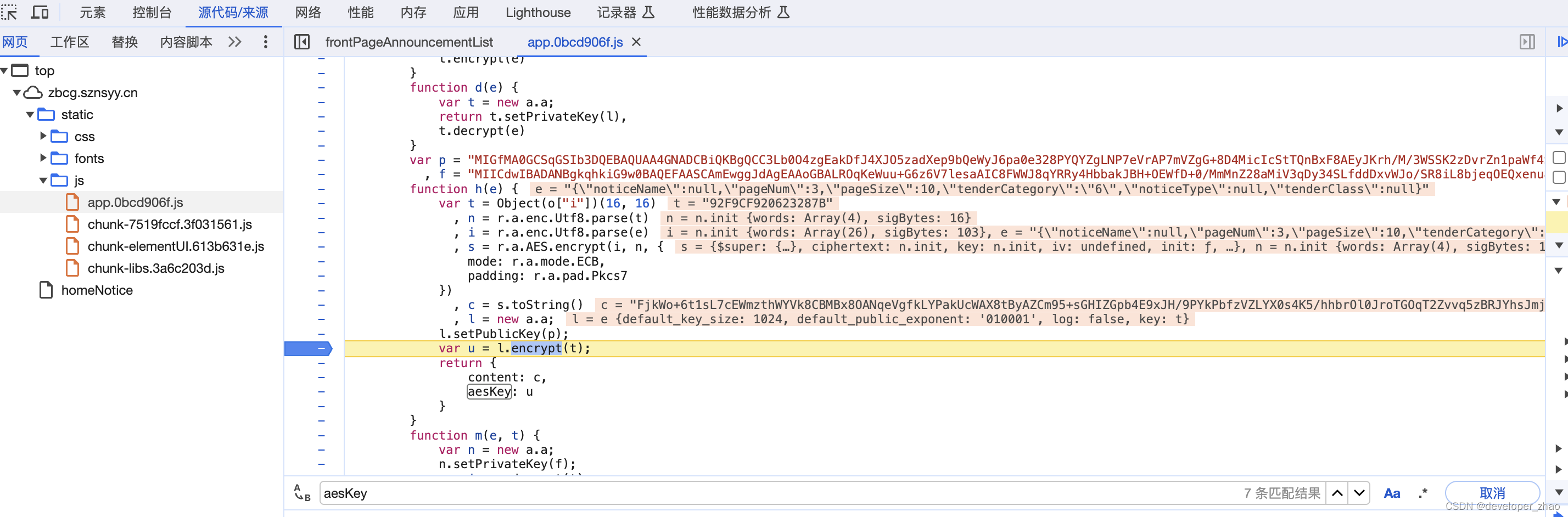
4 通过分析代码,可以看到整个流程应该是这样的,随机生成16长度的0到F的字符串,然后以该随机串当做aes的秘钥进行加密得到content字段对应的内容,另外再使用RSA加密算法使用公钥p对随机字符串进行加密得到aesKey字段对应的值, 话不多说,直接代码开始调试,博主对前端不太了解,一般都是通过pycharm中调用js函数来调试前端代码:
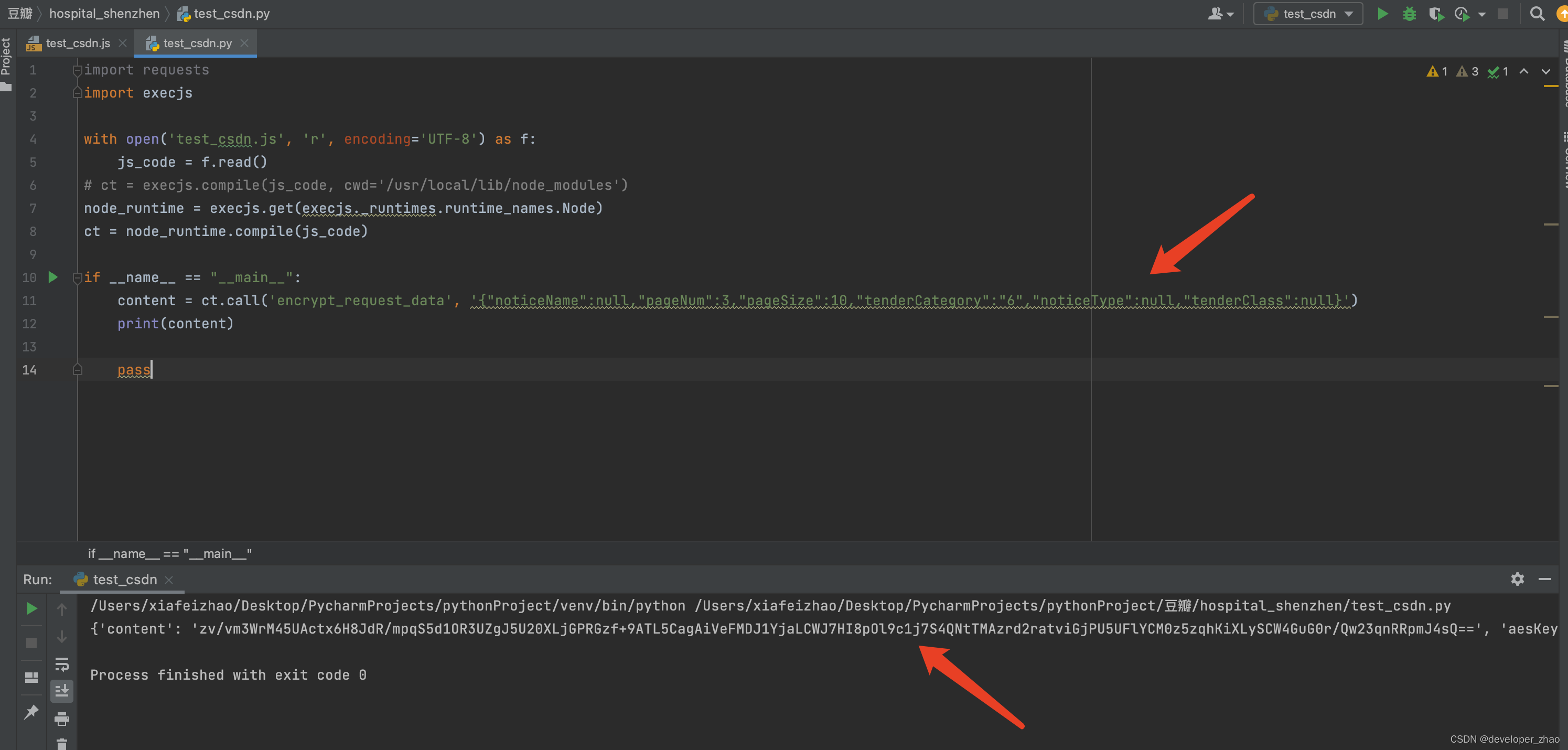
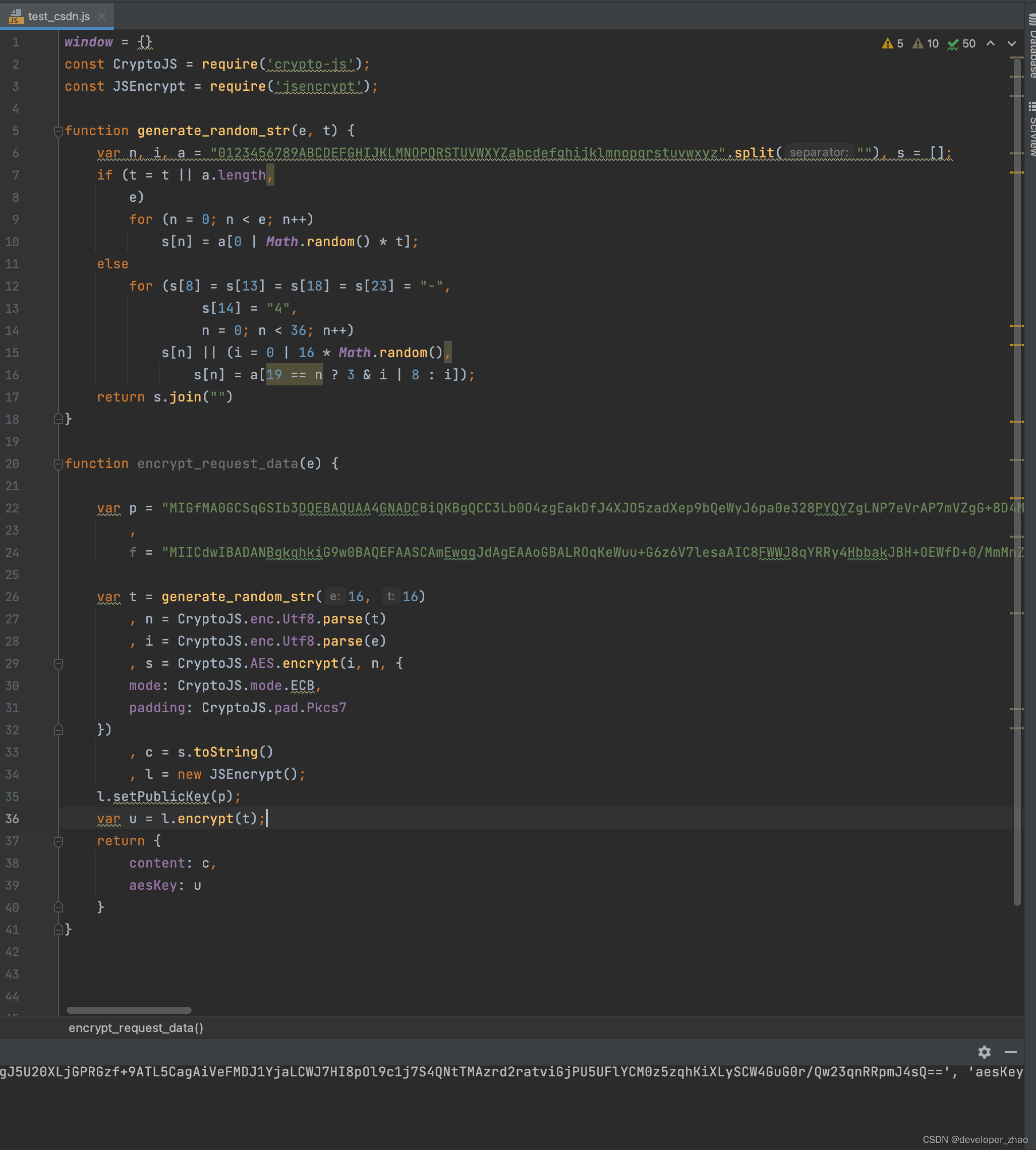
可以看到参数已经经过加密了
5 使用requests库编写请求代码:

此处已经可以看到正确的返回了
6 接下来根据加密方法编写对应的解密方法对返回数据进行解密, js文件中增加如下解密方法:

py文件中尝试调用解析方法:
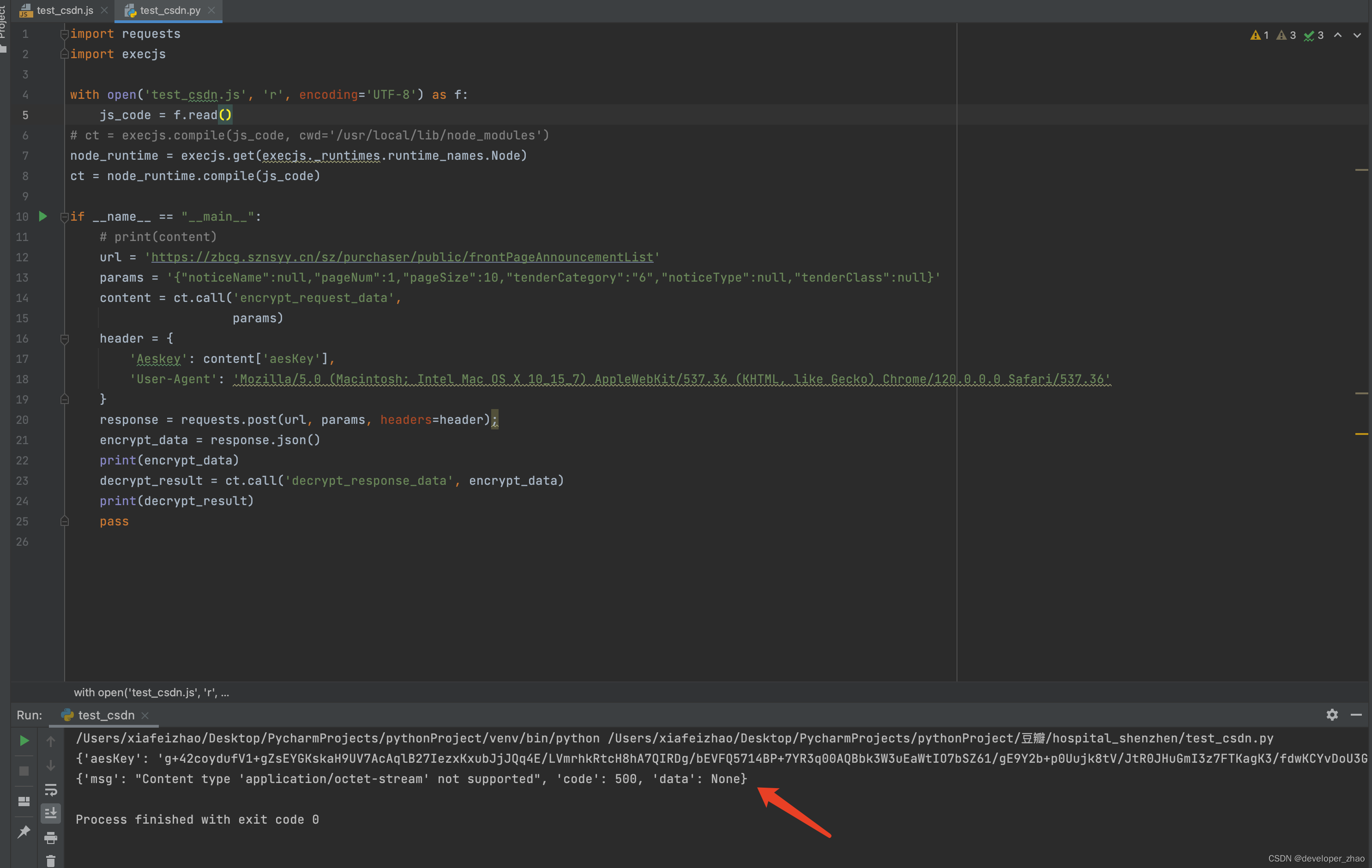
发现content-type报错,尝试修改请求头:
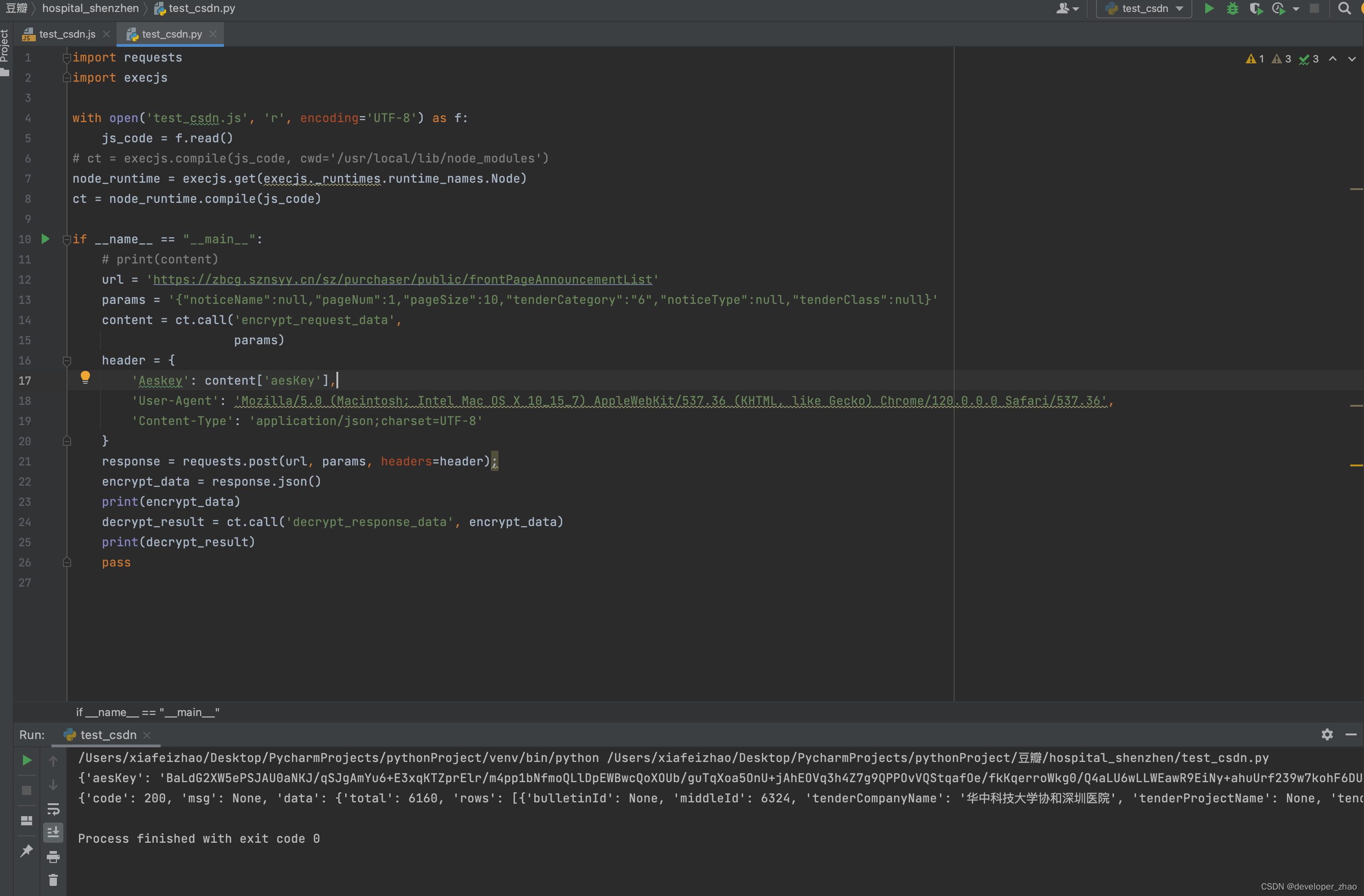
至此,主要内容已经叙述完毕了,感兴趣的小伙伴欢迎收藏点赞,谢谢大家
本文仅做学习交流使用,如做他用,后果自负
这篇关于某和医院招采系统web端数据爬取, 逆向js的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





