本文主要是介绍FLatten Transformer:聚焦式线性注意力模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
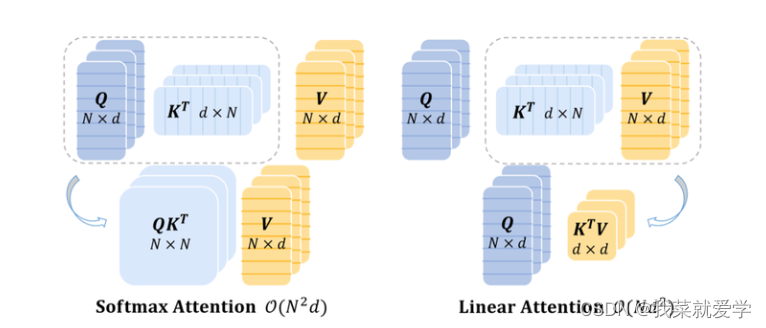
线性注意力将Softmax解耦为两个独立的函数,从而能够将注意力的计算顺序从(query·key)·value调整为query·(key·value),使得总体的计算复杂度降低为线性。然而,目前的线性注意力方法要么性能明显不如Softmax注意力,并且可能涉及映射函数的额外计算开销
首先,以往线性注意力模块的注意力权重分布相对平滑,缺乏集中能力来处理最具信息量的特征。作为补救措施,我们提出了一个简单的映射函数来调整查询和关键字的特征方向,使注意权值更容易区分。其次,我们注意到注意力矩阵的降低秩限制了线性注意力特征的多样性。提出了一个秩恢复模块,通过对原始注意矩阵进行额外的深度卷积(DWC),有助于恢复矩阵秩,并保持不同位置的输出特征多样化。
聚焦能力
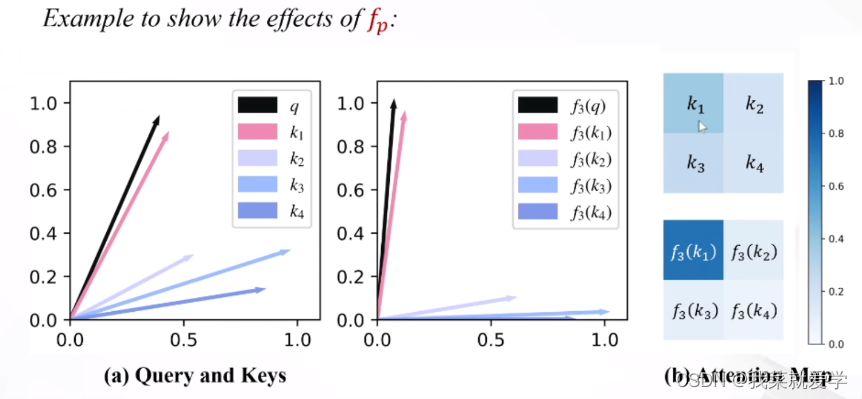
先前的一些工作中指出,在自注意力计算中,Softmax提供了一种非线性的权重生成机制,使得模型能够更好地聚焦于一些重要的特征。如下图所示,本文基于DeiT-tiny模型给出了注意力权重分布的可视化结果。可以看到,Softmax注意力能够产生较为集中、尖锐的注意力权重分布,能够更好地聚焦于前景物体;而线性注意力的分布则十分平均,这使得输出的特征接近所有特征的平均值,无法聚焦于更有信息量的特征。

Softmax Attention

Linear Attention
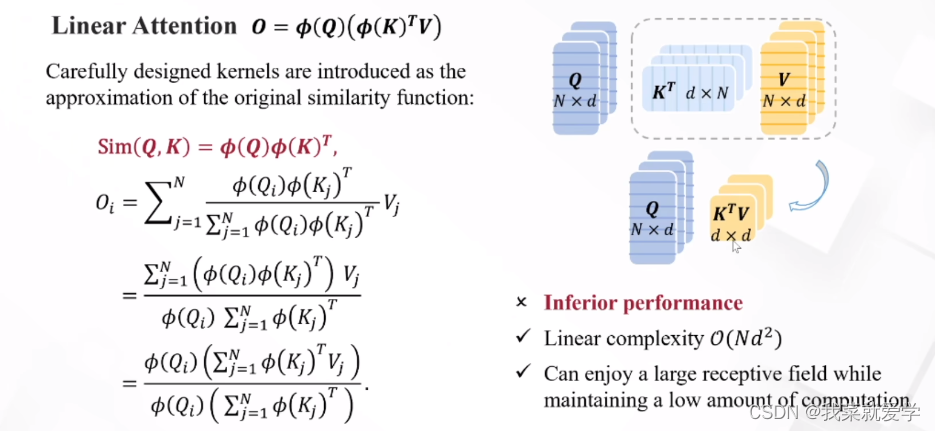
线性注意力被认为是一种有效的替代方法,它将计算复杂度从O(N2)限制到O(N)。具体来说,引入精心设计的核函数作为原始相似函数的近似,即
Focused Linear Attention
1、聚焦

2 、DWC 特征多样性
除聚焦能力外,特征多样性也是限制线性注意力性能的一个因素。本文基于DeiT-tiny可视化了完整的注意力矩阵,并计算了矩阵的秩,将Softmax注意力与线性注意力进行对比。从图中可以看到,Softmax注意力可以产生满秩的注意力矩阵,这反映出模型提取到的特征具有多样性。然而,线性注意力无法得到满秩的注意力矩阵,这意味着不同行的权重之间存在冗余性。。
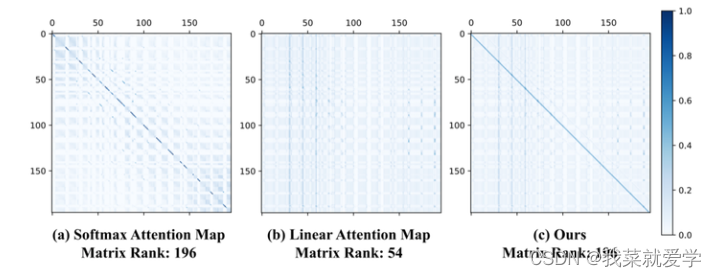
线性注意力矩阵的秩会被每个head的维度d和特征数量N中的较小者所限制:
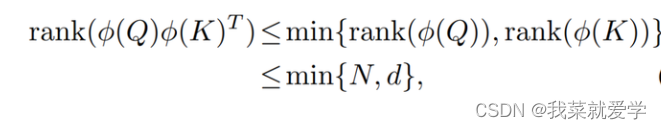
由于自注意力的输出是这些权重对同一组value加权组合得到的,权重的同质化就必然会导致模型输出的多样性下降,进而影响模型性能。
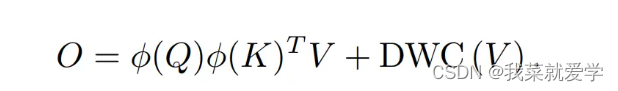
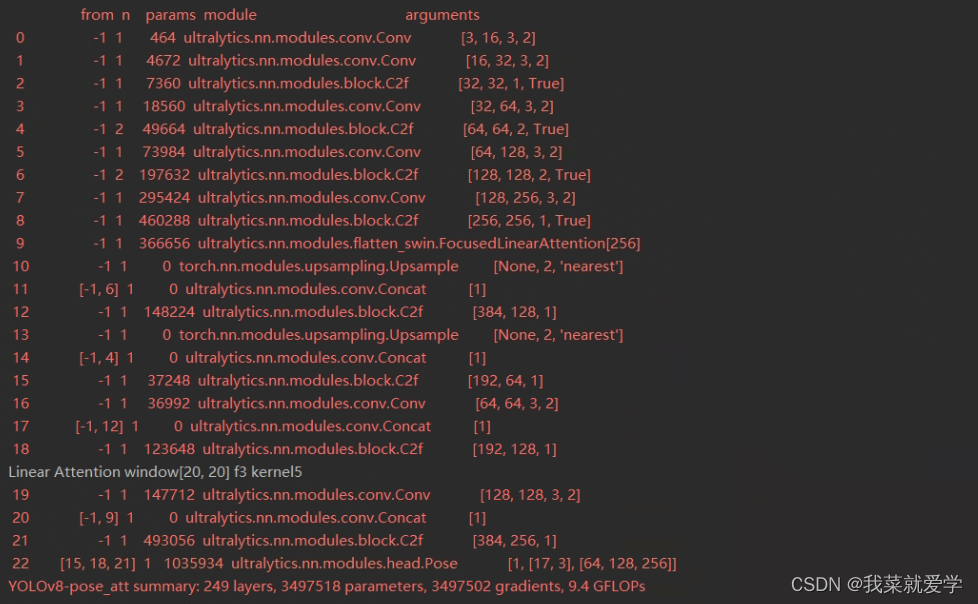
这篇关于FLatten Transformer:聚焦式线性注意力模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




