本文主要是介绍字正腔圆,万国同音,coqui-ai TTS跨语种语音克隆,钢铁侠讲16国语言(Python3.10),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

按照固有的思维方式,如果想要语音克隆首先得有克隆对象具体的语言语音样本,换句话说,克隆对象必须说过某一种语言的话才行,但现在,coqui-ai TTS V2.0版本做到了,真正的跨语种无需训练的语音克隆技术。
coqui-ai TTS实现跨语种、无需训练克隆语音的方法是基于Tacotron模型,该模型使用了一种音素输入表示来鼓励在不同语种之间共享模型容量。此外,还引入了对抗损失项,以鼓励模型将说话者身份与语音内容进行解耦。这使得模型能够在不同语种之间进行语音合成,而无需在任何双语或平行示例上进行训练。
具体来说,coqui-ai TTS首先使用音素输入表示:采用音素(语音的基本发音单位)作为输入表示,鼓励模型在不同语种之间共享模型容量,从而实现跨语种语音合成。
随后引入对抗损失项:对抗损失项的引入有助于模型将说话者身份与语音内容进行解耦,从而使模型能够在不同语种之间进行语音合成,而无需在双语或平行示例上进行训练。
此外,通过在训练过程中使用多个讲话者的语音数据,并引入自动编码输入来帮助稳定注意力,进一步扩展了模型的规模,使其能够在所有训练过程中看到的语种中一致地合成可理解的语音,包括训练讲话者的本地口音或外国口音。
本次我们基于coqui-ai TTS的2.0版本来让钢铁侠托尼斯塔克先生开口讲16国语言。
coqui-ai TTS语音克隆项目配置
首先克隆项目:
git clone https://github.com/v3ucn/coqui-ai_xTTS_v2.2_webui_cn.git
注意该项目并非官方项目,而是在其基础上的修改版本,添加了中文版本的webui。
进入项目的目录:
cd coqui-ai_xTTS_v2.2_webui_cn
随后安装依赖:
pip install -r requirements.txt
安装完成后,先在Python终端里测试一下:
import torch
from TTS.api import TTS
如果报下面这个错误:
from pydantic.typing import Annotated
ImportError: cannot import name 'Annotated' from 'pydantic.typing'
那么说明pydantic库的版本过高了,进行降级即可:
pip install pydantic<2
coqui-ai TTS语音克隆模型配置
随后下载2.0版本的模型,下载地址:
https://huggingface.co/coqui/XTTS-v2/tree/main
将其放入项目的models目录,结构如下:
E:\work\coqui-ai_xTTS_v2.2_webui_cn\models\tts>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
│
├───tts_models--multilingual--multi-dataset--xtts_v2
│ config.json
│ dvae.pth
│ hash.md5
│ mel_stats.pth
│ model.pth
│ speakers_xtts.pth
│ tos_agreed.txt
│ vocab.json
随后,需要做一件重要的事,那就是配置模型目录的环境变量 TTS_HOME = E:\work\coqui-ai_xTTS_v2.2_webui_cn\models\
如图所示:
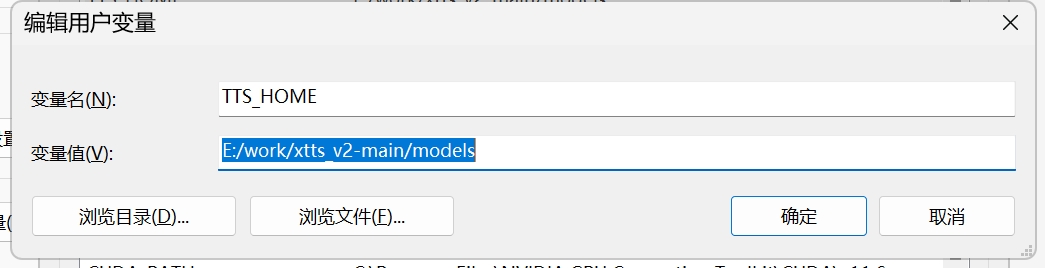
如果不设置环境变量,coqui-ai TTS会自动重复下载模型到C盘,非常的烦人。
coqui-ai TTS跨语种语音克隆推理
万事俱备,只欠推理,在终端执行命令:
python3 app.py
程序返回:
E:\work\coqui-ai_xTTS_v2.2_webui_cn>python app.py > tts_models/multilingual/multi-dataset/xtts_v2 is already downloaded. > Using model: xtts
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
注意程序初始化比较慢,另外设置了环境变量系统就会侦测到模型已下载。
此时访问 http://127.0.0.1:7860

默认用钢铁侠英文30秒素材作为克隆的数据集。
选择语速、语言即可直接推理,方便快捷。
这里需要注意的是,如果想让钢铁侠的音色讲日语,那么需要单独安装Mecab库,并且单独拷贝动态库,详见:Win11环境Mecab日语分词和词性分析以及动态库DLL not found问题(Python3.10),这里不再赘述。
除了钢铁侠的音色,我们也可以自主添加别的角色音色:
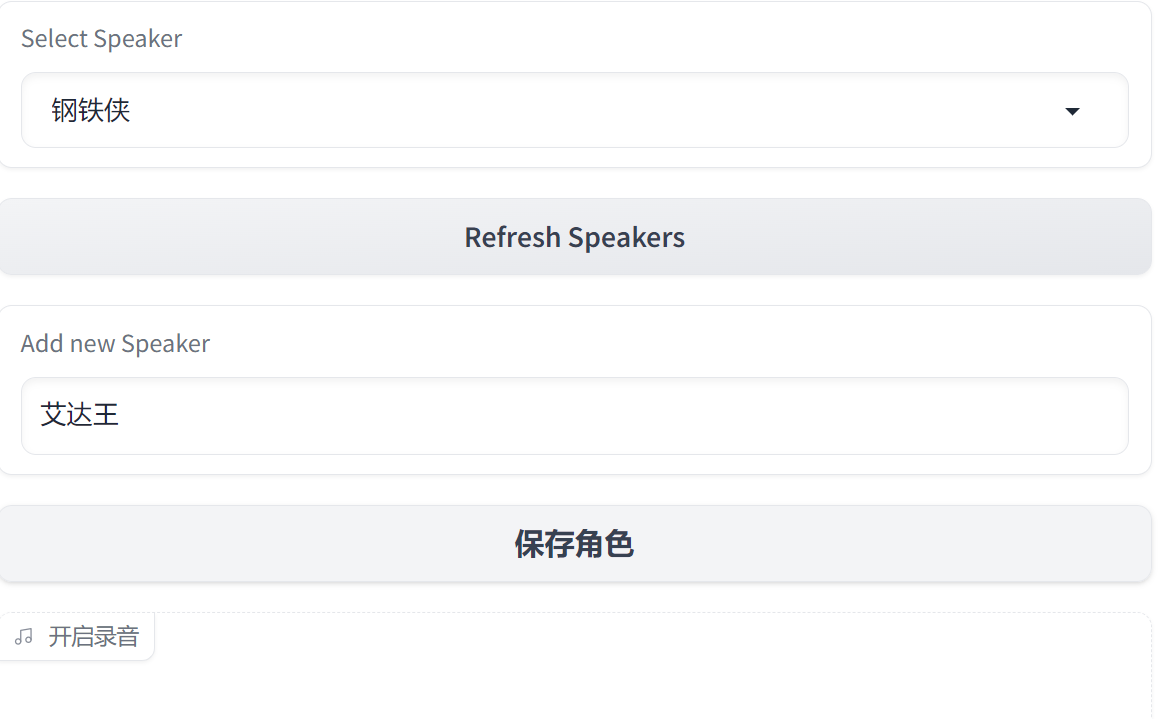
比如添加生化危机角色艾达王,那么把艾达王30秒的语音wav文件放入到项目的targets目录即可,命名规范:角色名.wav。
随后就可以在webui界面中选择艾达王的音色进行克隆。
结语
coqui-ai xtts支持多种语言,包括汉语、英语、韩语、日语、西班牙语、法语等。这意味着您可以使用coqui-ai xtts来合成多种语言的语音,而无需进行额外的训练或调整。其基于先进的深度学习技术,能够生成高质量、自然流畅的语音。这意味着即使在不同语种之间,coqui-ai xtts生成的语音也能保持高质量和自然度,正是居家旅行,口播嘴替的必备好库。
这篇关于字正腔圆,万国同音,coqui-ai TTS跨语种语音克隆,钢铁侠讲16国语言(Python3.10)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



