本文主要是介绍SAP HR 工资核算schema 子schema XINO 文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:
本文仅作为SAP文档的中文版翻译分享,本人仅做了翻译工作,仅供参考,若有错误,欢迎您的指出。若本文有任何涉及侵权的行为,请立刻联系我删除,在此先致歉。

概述
Initialization of Payroll (INTERNATIONAL)
人员计算schema
用途:在工资核算过程中,这个子schema定义/执行对于后续工资核算过程来说所重要的信息/活动。
根据上面的图片所示,此schema包含以下主要的步骤
第一步
定义(工资核算程序)的类型是薪酬还是评估。(一般都是薪酬)
根据功能PGM的文档中所描述的:
(1)Function PGM
根据程序类型区别schema
//功能PGM为核算工资者提供关于相关shcema所表示的程序类型的信息处理过程
//不同的schema允许工资核算者在处理时运行多次不同的程序的功能,它们是工资核算之后的薪酬和评估程序。这两种不同的程序解读可用的薪酬数据(例如,为雇员和/或作为追溯性会计的参数)。
//如果一个schema不包含功能PGM,这个程序被假定(默认)是一个薪酬核算程序。
//如果一个schema包含多个PGM功能,则以最后一个为准(被使用)。
Syntax
//语法
//参数1 //程序类型
ABR Payroll//薪酬核算
AUS Evaluation//评估
MIX Payroll/Evaluation//混合
SP Special run//特别运行,只对澳大利亚和西班牙适用
TRN Legacy data transfer//遗留的数据转移
参数1必输
//如果程序类型是MIX,将进行模拟工资核算并且不会更改主数据。
Example示例
//你想建一个薪酬核算的子schema
Fct Par1 Par2 Par3 Par4
PGM ABR
实际使用上如图:
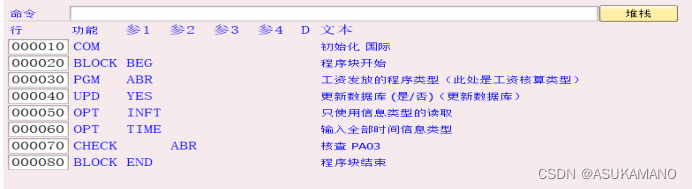 功能PGM的参数1为ABR
功能PGM的参数1为ABR
第二步
//选择是否更新数据库(即是否更新此员工的工资结果)(Y/N),所有的数据库更新由此处选择来决定。(除非是模拟工资核算,模拟工资核算不会更新此员工的工资核算结果)。
(2)Function UPD
根据功能UPD的文档中所写,Function UPD controls whether the results of a payroll accounting run are stored in the database or are only present during accounting(功能UPD 控制着是否将一个工资核算的结果存储在数据库中,或者只是用于核算过程)
功能UPD 必输的参数1是NO/YES,要更新员工工资核算结果则填写参数1为YES。
第三步
//只有适用于当前处理员工号的主数据记录会被读取。
参见功能OPT的文档。
第四步
//导入所有时间管理信息类型
第五步
//指定对照检查PA03状态
根据下述功能CHECK文档的描述:
(3)Function CHECK
功能CHECK完成两个任务
1.
按照schema类型检查规定的时间(期间)
2. 执行一个整体的检查
//详见如下:
//在员工号选定前(进行每个员工的核算前),会对每个被选中的工资范围进行检查。
//不符合check条件的工资范围会被排除,检查一般在对单个员工编号的处理前进行。即,如果工资范围不符合check条件,此工资范围内的员工号会被拒绝,不进行下一步处理。
Par2 //参数2 Type of check//检查类型
ABR Payroll//薪酬
AUS Evaluation//评估
BDE BDE
针对具体说明
CHECK ABR
//此参数(检查类型)进行以下的检查
1.是否已经释放了工资范围?(可以在PA03中检查,当绿色勾在“为工资核算范围”后面时,证明已经释放了工资范围。)如果不是,此(工资范围的)工资核算会被排除在选择之外。
2.是否存在此员工号的员工未来的工资核算结果?(例如,如果这次核算的是9月的工资核算,但存在此员工的10月的工资核算结果)如果存在,(此员工的)此次工资核算将不会进行。
CHECK AUS
//此参数(检查类型)进行以下的检查
1.上一次周期是否已经被评估?如果不是的话,此次评估将会被关闭不会再继续。这是为了防止已经被评估过的周期被反复评估。
CHECK BDE
目前对薪酬没有任何影响
说明
- 为了防止产生不连续数据集,接下来的function必须在生产系统中对check abr 是有效的。
- 'NOUPD’用来取消CHECK ABR的激活。一个schema对于生产系统而言是不足的。
这篇关于SAP HR 工资核算schema 子schema XINO 文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





