本文主要是介绍提升三维模型数据的几何坐标纠正速度效率具体技术方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提升三维模型数据的几何坐标纠正速度效率具体技术方法

根据搜索结果,以下是提升倾斜摄影三维模型数据的几何坐标纠正和三维重建速度的具体技术方法:
1、增加控制点:通过增加控制点数量可以提高几何坐标精度。控制点是已知地面坐标的点,用于摄像机姿态计算和图像纠正。
2、优化相机参数:优化相机参数可以提高三维模型数据的几何坐标精度。通过获得摄像机的内部和外部参数,如主距、畸变系数、姿态和位置等,进行优化。
3、地形高差校正:地形高度变化是导致倾斜摄影三维模型数据几何坐标偏差的主要原因之一。通过使用GPS和地面控制点获取地物的实际高度,并将其与三维模型数据中的高度进行比较和校正。
4、影像匹配算法优化:优化影像匹配算法可以提高几何坐标重建的速度和精度。这涉及使用低复杂度的算法,避免冗余计算和IO操作等。
5、硬件优化:升级计算机硬件可以显著提高处理速度,例如使用多核CPU、快速硬盘驱动器和大容量内存等。
6、并行计算:利用并行计算技术可以将任务分解为多个子任务,并在不同的CPU或GPU上并行处理,从而提高处理速度。
7、优化算法:使用优化算法可以有效提高几何坐标纠正和三维重建的速度,例如使用低复杂度的算法和避免冗余计算。
8、数据预处理:进行数据预处理可以提高几何坐标纠正和重建的效率和精度。
需要注意的是,倾斜摄影三维模型数据的几何坐标纠正涉及到大量的计算和数学操作,建议在专业人员指导下进行操作。
三维工厂软件介绍:

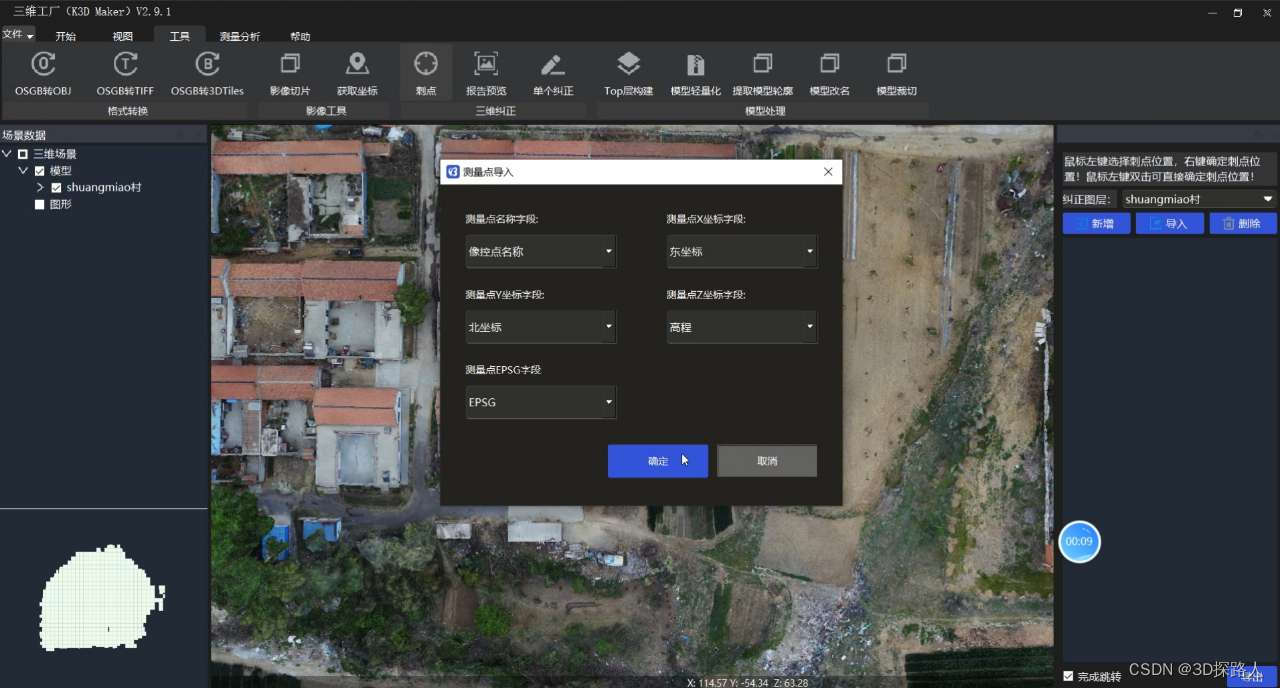
三维工厂K3DMaker是一款国内团队开发的三维模型浏览、分析、轻量化、顶层合并构建、根节点合并、几何校正(纠正)、格式转换、调色裁切、坐标转换等功能专业处理软件。可以进行三维模型的网格简化、纹理压缩、层级优化等操作,从而实现三维模型轻量化。轻量化压缩比大,模型轻量化效率高,自动化处理能力高;采用多种算法对三维模型进行几何精纠正处理,精度高,处理速度快,超大模型支持;优秀数据处理和转换工具,支持将OSGB格式三维模型转换为3DTiles等格式,可快速进行转换。优点在于免费、功能强大、支持多种文件格式,适用于多种领域。与常用三维重建软件配合,对三维模型进行优化处理,提高模型质量,丰富数据成果。来体验一下这个软件吧!


这篇关于提升三维模型数据的几何坐标纠正速度效率具体技术方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






