本文主要是介绍[434]UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘\ufffd‘等类似问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 问题描述
- 错误原因
- 解决办法
- 解决过程
- 使用Python自带的集成开发环境IDLE
- 最终解决
- 常用中文编码名称
问题描述
在写爬虫爬取网页信息时,发生了以下错误:
UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\ufffd’
意思大致是Unicode编码错误,gbk编解码器不能编码\ufffd字符。
错误原因
-
cmd默认编码是GBK,字符\ufffd不能编码为GBK。
-
查阅Unicode编码表或者使用Python自带的集成开发环境IDLE(可以输出),可知\ufffd其实是�字符。
-
Python3的字符串以Unicode编码,也就是解析网页时,需要将字符串从网页原来的编码格式转化为Unicode编码格式。
-
出现�字符的原因:从某编码向Unicode编码转化时,如果没有对应的字符,得到的将是Unicode的代码\ufffd,也就是�字符。
-
在写爬虫解析网页时出现�字符,往往是因为没有注意原网页的编码格式,全按照默认编码UTF-8转化,导致有的字符转化失败。
在本问题中,是由于在网页上包含珺、玥这样的中文,由于珺、玥是生僻字没有相应的UTF-8编码,所以以默认UTF-8编码格式转化为Unicode时,没有对应的字符,转化出错,得到\ufffd。又因为在cmd运行,因此报错UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\ufffd’。
解决办法
写爬虫解析网页时,要注意原网页的编码格式和压缩格式(Gzip等)
查看原网页的编码格式,为’gb2312’。
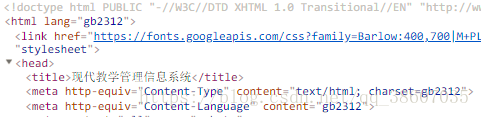
所以要按照gb2312编码向Unicode编码转化。
r = requests.get(url,cookies=cookies,headers=headers)
# 指定网页的编码格式
r.encoding = 'gbk'
# r.encoding = 'gb2312' 仍然会报错
最后再次在cmd运行代码,珺、玥这样的中文也成功显示。
注意:本解决办法适用于与本问题描述完全相同的问题,因为可能是相同的错误原因导致的。其它报错信息可能与本问题的情况不同,比如报错的为‘gbk’ codec can’t encode character ‘\xa0’
以下是问题的逐步分析解决过程。
解决过程
cmd显示编码是GBK,而有些Unicode字符不能编码成GBK
对于Unicode字符,需要print出来的话,由于本地系统是Windows中的cmd,默认codepage是CP936,即GBK的编码,所以python解释器需要先将上述的Unicode字符编码为GBK,然后再在cmd中显示出来。但是由于该Unicode字符串中包含一些GBK中无法显示的字符,导致此时提示'gbk' codec can’t encode的错误的。
分析:这个解释确实符合报错信息’gbk’ codec can’t encode character '\ufffd’的意思。
验证:编写python代码
print('\ufffd')
在cmd下运行,出现相同的报错信息'gbk' codec can't encode character '\ufffd'
解决办法1:改变标准输出的默认编码
在程序的开始加入以下代码
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
由于我输出的包含中文,所以使encoding=‘gb18030’,这段代码的作用就是把标准输出的默认编码修改为gb18030,也就是与cmd显示编码GBK相同。
效果:运行原来的爬虫代码后,没有了报错,但原先报错的输出位置显示为??,中文仍没有正确显示。


而且还有不能即时输出的问题,类似于python爬虫中文输出问题以及不即时输出问题
解决办法2:输出时忽略无法编码的字符
在对Unicode字符编码时,添加ignore参数,可以忽略无法编码的字符
print(你的字符串.encode('GBK', 'ignore').decode)
这句代码的作用为,把字符串以GBK编码,并忽略无法编码的字符,再以GBK解码,再输出。
效果:在解决办法1的效果基础上,??不再显示,但中文仍没有正确显示。


总结:由于\ufffd本身就没有对应的Unicode编码,所以要在cmd中不报错输出,只能把输出编码改为GBK或者在输出时忽略无法编码的字符,这样就算可以不报错输出,也不能正确显示\ufffd字符。
使用Python自带的集成开发环境IDLE
cmd的显示编码是GBK,要想正确显示\ufffd字符,就要使用支持多种输出编码的运行环境。Python自带的集成开发环境IDLE就对GBK、UTF-8、Unicode都支持。其实,Pycharm、jupyter notebook、sublimeREPL配置的python运行环境也支持多种输出编码。
IDLE打开方法:在python的安装目录下,打开lib/idlelib/idle.bat,就进入了IDLE环境
运行代码
print('\ufffd')
输出为: �
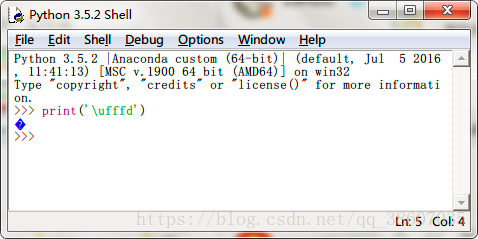
看到�这个结果,开始以为仍没有正确显示。但查询Unicode字符表,发现�字符的Unicode的值正是fffd。说明\ufffd字符已经正确显示了。

进一步分析
以上分析的原因和解决办法都是从最后显示输出的角度去考虑的,虽然一些方法不再报错,但仍然显示不正确,并没有真正解决。然后在IDLE中正确显示了字符,证明了\ufffd就是�字符。
从以上解决办法可以进一步验证和推测一些问题:
问题
- 本来应该显示的汉字是什么
- �是从哪来的
推测
对照原网页,发现是珺和玥字没有正确显示,而变成了\fffd�字符。这说明从一开始解析网页,珺和玥就被解析成了�字符。
验证
如果从报错信息找问题,报错原因是部分Unicode字符不能正确转码成GBK,所以无法显示。根据推测,原网页上的珺和玥字没有正确显示,而运行以下代码:
str = '珺玥'
str = str.encode('unicode_escape')
print(str)
# 输出 b'\\u73fa\\u73a5'
可知珺和玥的Unicode分别为73fa和73a5。而不是fffd。
经验证,print(’\u73a5’)是可以输出的玥字的。这说明并不是玥的Unicode转码为gbk失败,而是解析玥得到的Unicode都不正确,变成了\ufffd�字符。
使用爬虫 �作为关键字搜索,就找到了出现�字符的原因:
从某编码向Unicode编码转化时,如果没有对应的字符,得到的将是Unicode的代码“\uffffd”,也就是�这个字符。这个是你的爬虫根本不识别原网页的编码格式(ASCII或者GB2312等)和压缩格式(Gzip等),全都无脑转成UTF-8字符串导致的,出现这个字符说明转换失败,数据已经丢失了,这个字符本身并没什么实际意义。
最终解决
在进一步分析后,重新检查解析过程,显然是编码问题。
最后发现确实是因为没有注意到网页编码问题,网页编码是gb2312,而用requests请求的网页,如果不声明encoding值,默认是用UTF-8解析的。UTF-8编码支持大部分中文字,但不支持珺、玥这样的生僻字,这样转成UTF-8就转化失败。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1dWPllds-1631098910407)(https://upload-images.jianshu.io/upload_images/12504508-32440461df09d704.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
原网页的编码格式为’gb2312’
所以要按照gb2312编码向Unicode编码转化:
r = requests.get(url,cookies=cookies,headers=headers)
# 指定网页的编码格式
r.encoding = 'gbk'
# r.encoding = 'gb2312' 仍然会报错
最后再次在cmd运行代码,珺、玥这样的中文也成功显示。
最终总结,是由于在网页上包含珺、玥这样的中文,由于珺、玥是生僻字没有相应的UTF-8编码,所以以默认UTF-8编码格式转化为Unicode时,没有对应的字符,转化出错,得到\ufffd。又因为在cmd运行,因此报错UnicodeEncodeError: 'gbk' codec can't encode character '\ufffd'。
常用中文编码名称
| 编码名称 | 用途 |
|---|---|
| utf8 | 所有语言 |
| gbk | 简体中文 |
| gb2312 | 简体中文 |
| gb18030 | 简体中文 |
| big5 | 繁体中文 |
| big5hkscs | 繁体中文 |
来源:https://blog.csdn.net/qq_38607035/article/details/82595032
https://blog.csdn.net/jim7424994/article/details/22675759
这篇关于[434]UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘\ufffd‘等类似问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





