codec专题

【python 编码问题】UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-4: ordinal not
插入oracle 数据发生 错误:UnicodeEncodeError: 'ascii' codec can't encode characters in position 131-136: ordinal not in range(128) 先说解决办法: python2.7版本,在开头加入下面语句 import sysreload(sys)sys.setdefaultencoding

python2.7 的中文编码处理,解决UnicodeEncodeError: 'ascii' codec can't encode character 问题
python2.7 的中文编码处理 最近业务中需要用 Python 写一些脚本。尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息。 很快,我就遇到了异常: UnicodeEncodeError: 'ascii' codec can't encode characters in p
解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128
1.问题描述:一个在Django框架下使用Python编写的定时更新项目,在Windows系统下测试无误,在Linux系统下测试,报如下错误: ascii codec can't decode byte 0xe8 in position 0:ordinal not in range(128) 2.原因分析:字符问题。在Windows系统转Linux系统时,字符问题很容易出现。 3.解决办

《Python开发 - Python疑难杂症》Pyinstaller打包报错【UnicodeDecodeError: ‘utf-8‘ codec can‘t decode】分析与解决
1报错情景描述 笔者在使用PyQt5写了个程序后,使用Pyinstaller打包,出现以下错误: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 110: invalid continuation byte 2报错分析 从报错代码能够看出,编码问题导致的程序出错,解决办法就是修改编码方式。 3解决
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-3: ordinal not in range(128)
问题背景 在python2中安装了labelme,可以正常运行,然后又再python3中安装了labelme。后来python2中的labelme不能运行,python3中的labelme可以运行。 具体问题 UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-3: ordinal not in ra

aiohttp遇到非法字符的处理(UnicodeDecodeError: 'utf-8' codec can't decode bytes in position......)
这个问题困扰了我将近一天时间,如果使用text()函数会一直报“UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 24461-24462: invalid continuation byte”的错误,如果使用read()函数以二进制输出在后面解析的时候中文是乱码,网上查了很多资料,主要也是自己的疏忽自己看了源码,一直纠
使用CSDN-CODEC-IDE搭建php开发调试环境
问题求助于CSDN-肖恩老师 在CODE建立项目并进入C-IDE环境,这是Docker的ubuntu环境。ubuntu是已经安装了apache2的,修改一下ports.conf $ sudo vim /etc/apache2/ports.conf//修改端口为8080,并保存 3.新建一个php文件,写入几行代码(随便正确的代码就OK)后点击运行。这时候控制台会显示一个web应用访问地址。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 167
在用urllib.request库的时候一部小心就会碰到 url = "http://money.163.com/special/pinglun/"data_byte = urllib.request.urlopen(url).read()data = data_byte.decode('UTF-8')print(data) 报错: UnicodeDecodeError: 'utf-
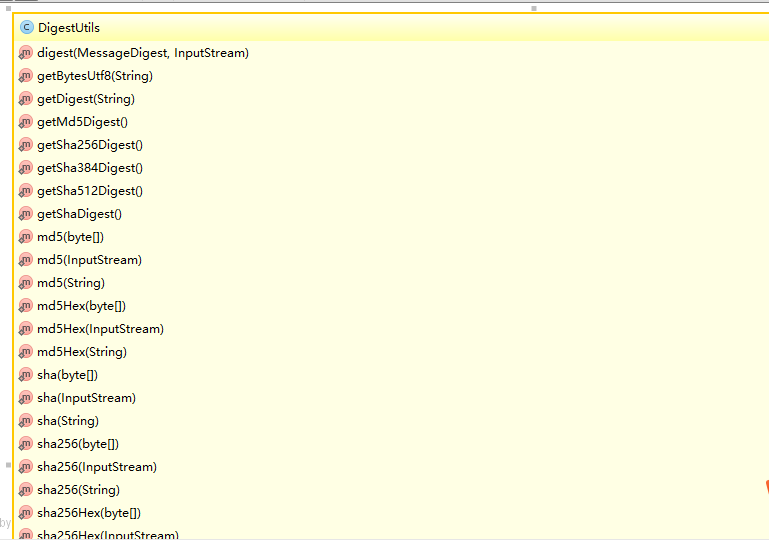
Apache commons codec |MD5 SHA BASE64 简单方便操作
Commons项目中用来处理常用的编码方法的工具类包,例如DES、SHA1、MD5、Base64,URL,Soundx等等。不仅是编码,也可用于解码 DigestUtils 对于原生的消息消息摘要实现的改进 code.digest 可以从图片上看出来,我们得到 MD5或者其他的更加的方便一些哦! 比如实现的SHA1和我们MD5这个都是单向的加密函数,不可逆的哦 package co

'ascii' codec can't decode byte 0xef in position 0:ordinal not in range(128)错误解决与原理分析
写python代码时出现’ascii’ codec can’t decode byte 0xef in position 0:ordinal not in range(128)的错误。 在解决错误之前,首先要了解unicode和utf-8的区别。 unicode指的是万国码,是一种“字码表”。而utf-8是这种字码表储存的编码方法。unicode不一定要由utf-8这种方式编成bytecode
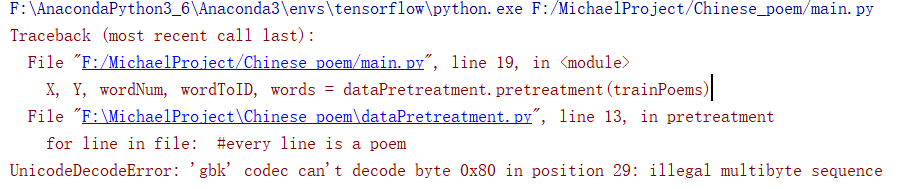
问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 29解决办法
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 python读文件: file = open(filename, "r") for line in file: #every line is a poem#print(line)title, poem = line.strip().
字符串编解码包----Commons-codec介绍
在实际的应用中,我们经常需要对字符串进行编解码,Apache Commons家族中的Commons Codec就提供了一些公共的编解码实现,比如Base64, Hex, MD5,Phonetic and URLs等等。 一、官方网址: http://commons.apache.org/codec/ 二、例子 1、 Base64编解码 private static Stri
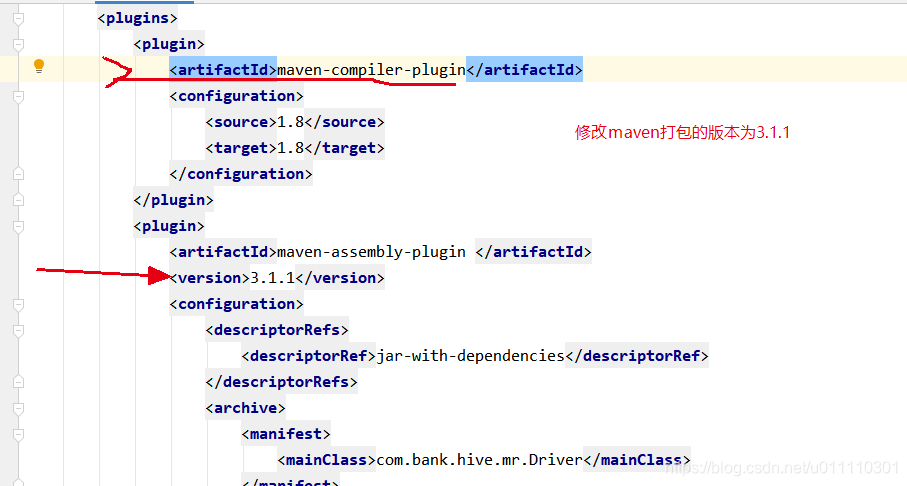
failed to find commons-codec:commons-codec:pom:1.15.......
问题描述:idea打jar包时,报错:failed to find commons-codec:commons-codec:pom:1.15........ 原因:jar包冲突或者少jar包,或者更改maven的打包版本 解决:去除jar包冲突或者下载相应jar包 1.如果你的集群环境有版本,去除jar包冲突时一定要手动输入jar包的<aetifactId>,比如spark-sql_2.

UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence
pycharm报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence 解决办法: 然后: 就好了!
python读取文件时提示UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multi
解决办法1. FILE= open('order.log','r', encoding='UTF-8') 解决办法2 FILE= open('order.log','rb')
codec engine代码阅读1~3:根目录package.xdc,release notes和example文件夹
codec engine代码阅读1~3: http://www.usr.cc/thread-52029-1-3.html http://www.usr.cc/thread-52030-1-3.html http://www.usr.cc/thread-52032-1-3.html codec engine代码阅读一---根目录下的package.xdc
多媒体视频开发_(25) hevc/h265/hev1/hvc1 codec_tag兼容问题
待梳理: reference: https://juejin.cn/post/6854573210579501070 https://stackoverflow.com/questions/32152090/encode-h265-to-hvc1-codec https://blog.csdn.net/qingzhuyuxian/article/details/89299565?utm_medi
Android上应用commons.codec包进行RSA加密问题。
Android上应用commons.codec包进行RSA加密问题踩坑小记。 问题描述原因解决感谢 问题描述 采用RSA加密由于后台也是java开发,所以直接把代码拿过来用了,看起来很好改一下base64编码就OK了。 可是很不幸,对服务端发送的加密数据处理的时候,解密会多出一些额外的�����������字符。 尝试多次后猜想是因为用的android.util.
【字符编码】‘utf8’ codec can’t decode byte 0xa1
办法1: 文件头部增加代码,如下 #!/usr/bin/env python# coding=utf-8 办法2: 用 codecs打开文件,如下 codecs.open() 办法3: 用 utf8编码打开文件,如下 with open(file, 'r', encoding='utf-8') as f: 办法4: 用 ISO-8859-1 编码打开文件(应用于


解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5
Python的str默认是ascii编码,和unicode编码冲突,就会报这个标题错误。那么该怎样解决呢? 通过搜集网上的资料,自己多次尝试,问题算是解决了,在代码中加上如下几句即可。 import sysreload(sys)sys.setdefaultencoding('utf8')
lucene4 codec反射
Lucene4 的codec通过反射加载相应的类。 与反射相关的信息放到了lucene的jar文件的META-INF\services目录下。 相关代码在NamedSPILoader.java中 某些特殊项目需要去掉codec的反射机制,修改这个函数即可(4.5.0版本)。修改之后,不需要META-INF\services。 public synchronized void reload
UnicodeDecodeError: 'utf8' codec can't decode bytesnbsp
▼ 编码问题真的是个很常见且困扰的问题: 原文是ansi编码,(windows下默认编码),换到linux下工作,需要转为utf8编码,文件多所以写了个小程序, 其中执行到这:outfile.write(line.encode('utf-8')),会报错: UnicodeDecodeError: 'utf8' codec can't decode bytes in positio
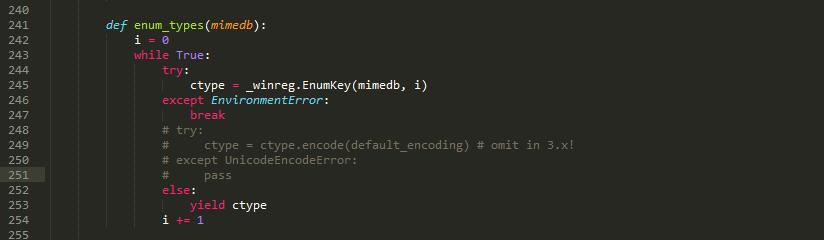
UnicodeDecodeError: 'ascii' codec can't decode byte 0Xb0 in postion 1: ordinal not in range(128)
Python 安装一些package包时会提示:UnicodeDecodeError 安照网上的方法解决方案: 在C:\Python27\Lib 里面找到 mimetypes.py 注释或者删除第249行的那一片断代码。
phthon踩雷(二):UnicodeEncodeError: ‘UCS-2‘ codec can‘t encode characters in position...
报错如下: UnicodeEncodeError: 'UCS-2' codec can't encode characters in position 3298-3298: Non-BMP character not supported in Tk 翻译一下就是: Unicode编码错误:'UCS-2’编码器不能编码在3298-3298这个位置的字符类: Non-BMP 字符类在Tk中不