gbk专题

解决IDEA报错:编码GBK的不可映射字符问题
《解决IDEA报错:编码GBK的不可映射字符问题》:本文主要介绍解决IDEA报错:编码GBK的不可映射字符问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录IDEA报错:编码GBK的不可映射字符终端软件问题描述原因分析解决方案方法1:将命令改为方法2:右下jav

maven项目中程序运行编译的时候出现:编码GBK的不可映射字符
由于JDK是国际版的,我们在用javac.exe编译时,编译程序首先会获得我们操作系统默认采用的编码格式(也即在编译java程序时,若我们不指定源程序文件的编码格式,JDK首先获得操作系统的file.encoding参数(它保存的就是操作系统默认的编码格式,如WIN2k,它的值为GBK),然后JDK就把我们的java源程序从file.encoding编码格式转化为JAVA内部默认的UNICODE格

Android 打开 GBK项目如何设置成UTF-8
1.标题 今天打开一个eclipse老项目,编码格式为GBK,Android studio导入项目报错,本人想到一个方案就是批量修改文件格式从 GBK到 UTF-8,这样可以一键解决问题 2.开发脚本 使用前请备份代码 使用前请备份代码 使用前请备份代码 脚本代码如下,保存到文件下为 shell.ps1 # 获取当前脚本的所在目录$folderPath = Get-Loca

utf-8、gbk、unicode相互转码的几种方式
utf-8、gbk、unicode相互转码的几种方式 以下代码是java对于常见编码方式进行相互转换的,主要是gbk和utf-8互转,gbk与uncode互转,utf-8与unicode互转。 package com.encoding.util;import java.io.UnsupportedEncodingException;import java.lang.Characte

在Mysql数据库中执行函数报错: Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE
SQLSTATE[HY000]: General error: 1267 Illegal mix of collations (utf8_general_ci,IMPLICIT) and (gb2312_chinese_ci,COERCIBLE) for operation ‘=’ 在操作MySQL数据库时,报“ error code [1267]; 在Mysql数据库中执行函数报错: Illeg
使用python按拼音归类GBK编码表中的所有汉字
按拼音归类GBK编码表中的所有汉字,每个拼音对应的第一个汉字前面用左大括号,每一个拼音的最后一个汉字后面用右大括号,并保存到txt文本中,并统计包含了多少汉字 安装必要的库 确保安装 pypinyin 库用于拼音转换: pip install pypinyin 代码 import collectionsimport pypinyin# 生成 GBK 编码中的所有汉字gbk_char

Python实现文件(xml,txt)编码转换GB2312、GBK、UTF-8
Python实现文件编码转换GB2312、GBK、UTF-8 1、查看文件编码格式 import chardetfilename = './flash.c'with open(filename, 'rb') as f:data = f.read()encoding_type = chardet.detect(data)print(encoding_type) 运行结果: 2、文件编码
javac编译错误: 编码UTF8/GBK的不可映射字符
本文出处: http://blog.csdn.net/leytton/article/details/52740171 Linux下为UTF-8编码,javac编译gbk编码的java文件时,容易出现“错误: 编码UTF8的不可映射字符” 解决方法是添加encoding 参数:javac -encoding gbk WordCount.java Windows下为G
iOS_技巧(4)_转码(UTF-8 /GBK/Unicode/GBK2312)
一丶 UTF-8 /GBK UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。 GBK全称《汉字内码扩展规范
优化C++ utf8,gbk,unicode编码间的转换函数
好久没写博客了,不是太忙,是太懒了。。。 最近都在重构公司项目上的代码,然后就发现有部分函数的运行方式可以优化。这些函数的运行的运行方式都是先new出一堆内存,使用,最后delete掉。我就想,可不可以通过静态局部变量来重复使用已经new了的动态内存,以达到优化代码的运行的目的?然后我就用visual studio 2017进行了测试,下面是我的测试代码: #include <random>
中文字符编码之GBK,UTF-16和UTF-8
编程中经常会遇到这三种字符编码形式的相互转换问题,以至于许多第三方的库不明原因的调用失败,其实很多都是由于第三方库支持的是utf-8而不是windows默认支持的utf-16导致的。 下面介绍一下windows系统下常见的这三种字符编码方式。 GB2312 是我们国家自己国标的汉字编码字符集,该字符集以一个16位的2进制数据单元表示一个汉字,所以能够将两个char型数据单元保存一个汉字。

【Android Studio错误汇总】Error:(105, 20) 错误: 编码GBK的不可映射字符
最近从eclipse迁移项目到Android Studio,发现文件注释编程乱码,提示也是乱码。 刚开始,项目和错误都是乱码,参考Android Studio 中GBK中文乱码和因此无法运行程序的一些经验 在File->Setting->File Encoding设置中文件的编码格式为GBK,自己选择了reload,给自己埋下好大一颗雷。 设置之后,log中乱码没有了,却一直提示:
使用node中的iconv-lite实现对“gbk”格式的转码
在window中,gbk和utf-8是最常见的两种格式,但是我们在显示的时候往往需要将GBK转换为UTF-8,我现在有一个同步读取文件的操作: const fs = require('fs');const path = require('path');const buffer = fs.readFileSync(path.join(__dirname, '../lyrics/友谊之光.lrc'
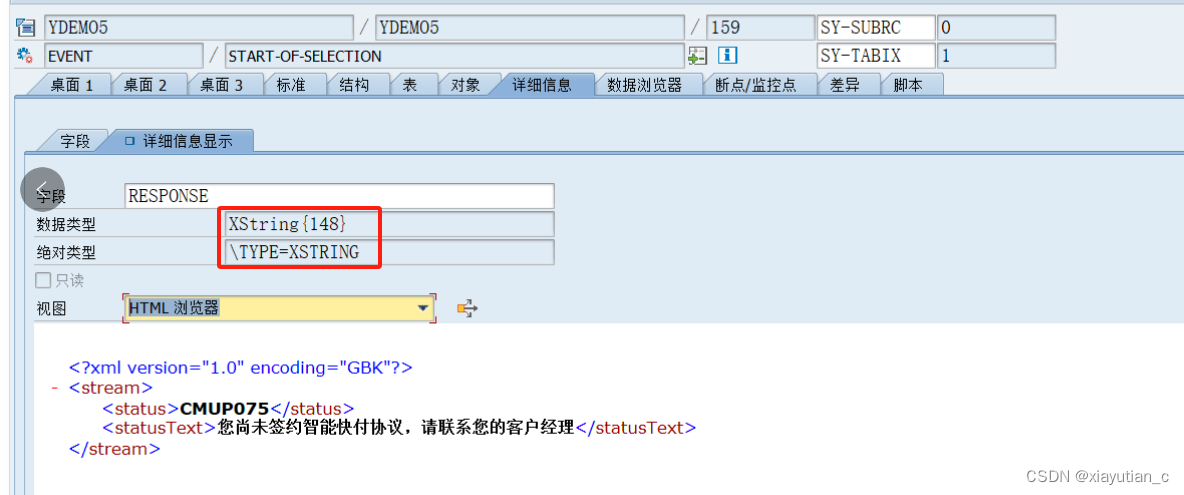
XML Encoding = ‘GBK‘ after STRANS,中文乱码
最近帮同事处理了一个中信银行银企直连接口的一个问题,同事反馈,使用STRANS转换XML后,encoding始终是’utf-16’,就算指定了GBK也不行。尝试了很多办法始终不行,发到银行的数据中,中文始终是乱码。 Debug使用HTML视图看报文时也可以看到中文是乱码。 解决方案: 使用cl_sxml_string_writer=>create创建一个GBK编码的对象 ,用来做为ST

字符集、字符编码、国际化、本地化简要总结(UNICODE/UTF/ASCII/GB2312/GBK/GB18030)
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 普通的linux 和 普通的windows。 VS2015 和 GCC 7.0 前言 曾记得,我在(https://blog.csdn.net/u011728480/article/details/100277582 《数与计算机 (编码、原码

Java——IO流(一)-(4/8):前置知识-字符集、UTF-8、GBK、ASCII、乱码问题、编码和解码等
目录 常见字符集介绍 标准ASCII字符集 GBK(汉字内码扩展规范,国标) Unicode字符集(统一码,万国码) 小结 字符集的编码、解码操作 方法 实例演示 常见字符集介绍 标准ASCII字符集 ASCll(American Standard Code for Information Interchange):美国信息交换标准代码,包括了英文、符号等。标准
Maven: 编码GBK的不可映射字符不能编译
使用mvn compile命令,出现错误: 编码GBK的不可映射字符不能编译。这是因为代码或注释中存在中文引起的,一般在ide中会自动处理编译时的字符集,就不会碰到这个错误。这个错误是在生成代码后,其中自动加上了中 文注释,手动删除中文注释处理这个问题太麻烦。这个错误是在命令行执行编译命令才出现的,需要设置编译的字符集,设置方式是: <plugin> <artifactId>maven-comp
乱码之UTF-8 GBK
在提交JSP时对于乱码问题,首先我们要搞清楚为什么会出现乱码? 看JSP的头文件:<%@ page contentType="text/html;charset=UTF-8" language="java"%> 在这个头文件中,还有一个与编码的相关的属性:pageEncoding --------------------------------------------------
批量把文本文档的GBK编码转化为UTF-8
package cwj.bbb;import java.io.*;import java.util.Collection;import org.apache.commons.io.FileUtils;/** 批量把文本文档的GBK编码转化为UTF-8* 使用用commons-io.jar实现文件的读取和写入* */public class EncodeTest1 {public static
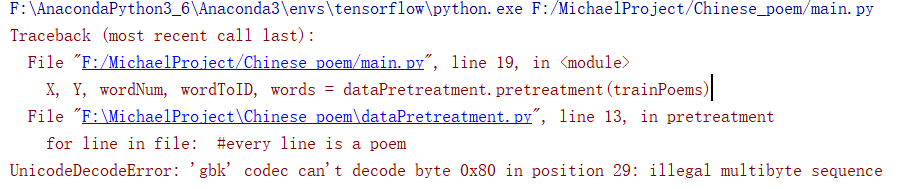
问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 29解决办法
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 python读文件: file = open(filename, "r") for line in file: #every line is a poem#print(line)title, poem = line.strip().
常用编码GBK,Unicode,UTF-8,单个中英文字符占用的字节数
GBK是在ANSI的基础上对中文(含繁体)的扩展,简体中文的windows环境中,VS默认GB2312编码. 编码 单个英文(含标点符号)占用 字节数 单个中文(含标点符号)占用字节数 GBK 1 2 UNICODE 2 2 UTF-8 1 3
编码GBK和GB2312、Unicode、UTF-8
一、编码GBK和GB2312 随着计算机发展,各国已经不满足于单纯用ASCII码; 对于我们来说能在计算机中显示中文字符是至关重要的,所以我们还需要一张关于中文和数字对应的关系表; 一个字节8位二进制,只能最多表示256个字符,要处理中文显然一个字节是不够的; 所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突; 所以1980年中国制定了GB2312编码,国家简体中文字
gbk,utf-8占用字节数
GBK: 中文、英文、数字均使用双字节来表示 UTF-8: 汉字占3个字节、数字占1个字节、英文字母占1个字节 例: <?php //测试时文件的编码方式要是UTF8 $str='中文a字1符'; echo strlen($str).'<br>';//14 echo mb_strlen($str,'utf8').'<br>';//6 echo mb_s
编码 字符集 历史 utf-8 gb2312 gbk unicode
1、美国人首先对其英文字符进行了编码,也就是最早的ascii码,用一个字节的低7位来表示英文的128个字符,高1位统一为0; 2、后来欧洲人发现尼玛你这128位哪够用,比如我高贵的法国人字母上面的还有注音符,这个怎么区分,得,把高1位编进来吧,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。欧美人就是喜欢直来直去,字符少,编码用得位数少; 3、但是即使位数少,不同国家地区用不同的字符
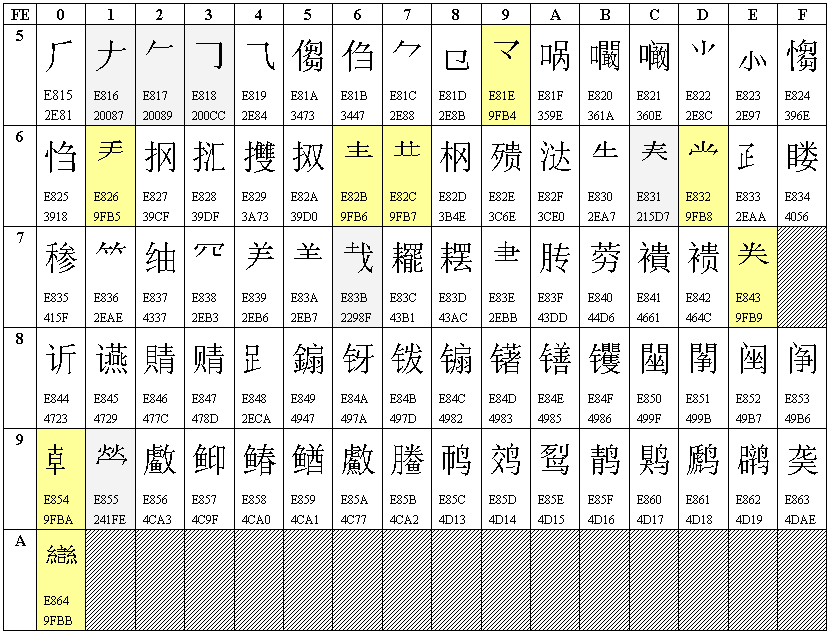
Unicode、GB2312、GBK和GB18030中的汉字
Unicode、GB2312、GBK和GB18030中的汉字 GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标

UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence
pycharm报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence 解决办法: 然后: 就好了!