本文主要是介绍基于LeNet5的手写数字识别神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于CNN,迄今为止已经提出了各种网络结构。在这里我们着重介绍一下在1998年首次被提出的CNN元组LeNet。LeNet子啊1998年被提出,是进行手写数字识别的网络,如下图所示,他又连续的卷积层和池化层(正确地讲,是只“抽选元素”的子采样层),最后经全连接输出结果。
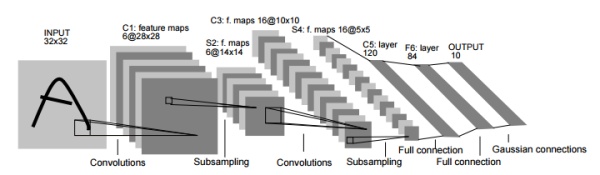
在初始的LeNet中,输入时32*32的图像,经过卷积层输出channel为6,大小28*28的feature map,在经过子采样(Subsampling)池化后,将图像大小变为14*14,(stride=2)在进行卷积,output_channel变为16,大小10*10,在经过一层子采样池化,将图像最终变为5*5,传给全连接层,经过全连接层处理后输出。具体处理流程如下图:
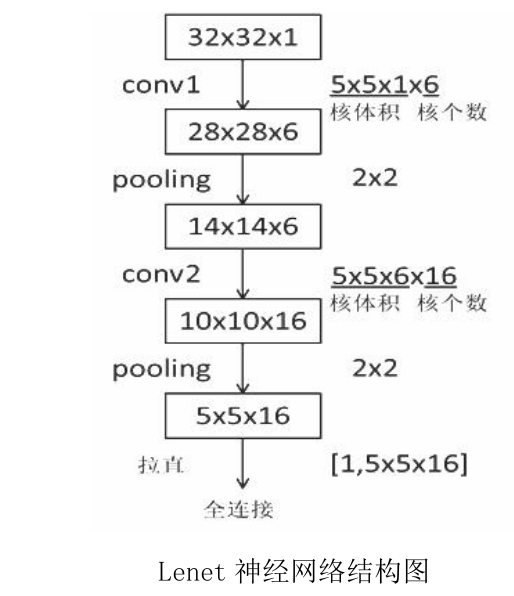
和现在的CNN相比,LeNet有几个不同点。第一个不同点在于激活函数,LeNet中使用的是sigmoid函数 ,而现在的CNN中主要使用ReLU函数。此外,原始的LeNet中使用子采样(Subsampling)缩小中间数据大小,而现在的CNN中Max池化是主流。
下面我们完成一个基于LeNet5的网络对MNIST数据集的识别:
首先我们先建立数据集,在这里可以说利用datasets下载这样的简易数据集简直不要太好用
mnist_train = datasets.MNIST('MNIST',True,transform=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor()]),download=True)mnist_train = DataLoader(mnist_train,batch_size=batch_size,shuffle=True)mnist_test = datasets.MNIST('MNIST',False,transform=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor()]),download=True)mnist_test = DataLoader(mnist_test,batch_size=batch_size,shuffle=True)
我们对下载好的数据集进行输出,看看情况怎么样(batch_size = 32)
x,label = iter(mnist_train).next()print('x:',x.shape,' label:',label.shape)#输出结果:x: torch.Size([32, 1, 28, 28]) label: torch.Size([32])下面我们来建立一个LeNet网络:
class lenet5(nn.Module):"""for MNIST DATASET"""def __init__(self):super(lenet5, self).__init__()# convolutionsself.cov_unit = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,stride=1,padding=1),nn.MaxPool2d(kernel_size=2,stride=2,padding=0),nn.Conv2d(6,16,kernel_size=5,stride=1,padding=1),nn.MaxPool2d(kernel_size=2,stride=2,padding=0))#flattenself.fc_unit = nn.Sequential(nn.Linear(16*5*5,120),nn.ReLU(),nn.Linear(120,84),nn.ReLU(),nn.Linear(84,10))def forward(self,x):batchsz = x.size(0)x = self.cov_unit(x)x = x.view(batchsz,16*5*5)logits = self.fc_unit(x)return logits在这里需要借鉴一下:LeNet论文阅读:LeNet结构以及参数个数计算_silent56_th的博客-CSDN博客![]() https://blog.csdn.net/silent56_th/article/details/53456522
https://blog.csdn.net/silent56_th/article/details/53456522
博主的博客内对输入数据和隐藏层的参数分析以及为何不全采用全连接做了解释:我自己对于kernel_size部分的参数选定还有理解不到位的地方,在这里借鉴一下:

 已经搭建好了LeNet网络,下面定义优化器和损失函数已经利用GPU进行加速:
已经搭建好了LeNet网络,下面定义优化器和损失函数已经利用GPU进行加速:
device = torch.device('cuda')
model = lenet5().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(),lr=1e-3)在这里我们可以将model在控制台打印出来,观察一下,在整体观察一下LeNet网络模型:
# 控制台打印输出
model: lenet5((cov_unit): Sequential((0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(1, 1))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1), padding=(1, 1))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(fc_unit): Sequential((0): Linear(in_features=400, out_features=120, bias=True)(1): ReLU()(2): Linear(in_features=120, out_features=84, bias=True)(3): ReLU()(4): Linear(in_features=84, out_features=10, bias=True))
)从这里可以看到,基本是我们所设置的一个网络模型,现在网络已经搭建完毕,优化器和参数都以设定,下面开始进行训练:
for batchidx,(x,label) in enumerate(mnist_train):x,label = x.to(device),label.to(device)logits = model(x)loss = criteon(logits,label)optimizer.zero_grad()loss.backward()optimizer.step()print('epoch:',epoch,' loss:',loss.item())这里的logits原指sigmoid函数(标准logits函数),但是在这里用来表示最终全连接层输出,而非其本意。在每个epoch结束后,将损失函数loss的值打印在控制台
下面是进行的测试:
model.eval()with torch.no_grad():total_num = 0total_correct = 0for x,label in mnist_test:x,label = x.to(device),label.to(device)logits = model(x)pred = logits.argmax(dim=1)total_correct += torch.eq(pred,label).float().sum().item()total_num += x.size(0)acc = total_correct/total_numprint('epoch:',epoch,' accuarcy:',acc)这里的pred = logits.argmax(dim=1),argmax函数是返回最大值的索引,即经过训练后预测结果概率最大的索引,这里将pred和监督标签label进行比较,如果equal便加到total_correct中,最后计算acc。
在进行训练和测试之前,分别添加了model.train()以及model.eval()
(1). model.train()
启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为True
(2). model.eval()
不启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为False
BatchNormalization的思路是调整各层的激活值分布使其拥有适当的广度,要向神经网络中插入数据分布进行正规化的层,可以使学习快速进行、不那么依赖初始值同时还可以一定程度抑制过拟合
Dropout是一种在学习过程中随机删除神经元的方法,通过随机选择并删除神经元,停止向前传递信号,使用Dropout可以使训练数据和测试数据的识别精度的差距变小了,即使是表现力很强的网络,也可以抑制过拟合。
最后,我们为了使数据可以更好的展现和反馈,我们利用visdom进行可视化
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train_loss'))
global_step = 0对于train_loss,从[0,0]坐标开始,每一个epoch执行完,global_step += 1
global_step += 1viz.line([loss.item()],[global_step],win='train_loss', update='append')将本次epoch内计算的loss以折线图的方式绘制
viz.images(x.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',opts=dict(title='pred'))此时x.shape为[16,1,28,28],str(pred.detach().cpu.numpy())是将预测值变为数据类型打印出来

经过15个epoch我们可以看到,这个识别的精确度已经很高了,我们在看一下visdom可视化的结果:
 也是可以看到的,虽然略有起伏,但是train_loss还是在逐步下降的,我们抽取了10个数据进行展示,可以看到, 预测的结果也是十分准确的。
也是可以看到的,虽然略有起伏,但是train_loss还是在逐步下降的,我们抽取了10个数据进行展示,可以看到, 预测的结果也是十分准确的。
Conclusion:LeNet只是在1998年最早提出来的CNN,与现在的CNN虽然有些许不同,但是差别也不是很大,考虑到提出的时间很早,所以LeNet还是十分令人称奇的
这篇关于基于LeNet5的手写数字识别神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






