本文主要是介绍我的cs231n学习笔记(1)lecture2-data driven approach,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
lecture2:image classification
图像分类是计算机视觉中真正核心的任务。当你做图像处理时,分类系统接受一些输入图像,并且系统清楚一些已经确定了分类或者标签的集合(图像中具体所指事物的名称如:狗、猫),计算机的工作就是看图片然后将进行分类哪些是狗哪些是猫。这对人类来说简单无比但是对于计算机来说难于登天,因为计算机并没有图片的概念,它看到的只是一堆数字阵列,这就成为语义鸿沟(Semantic Gap)。
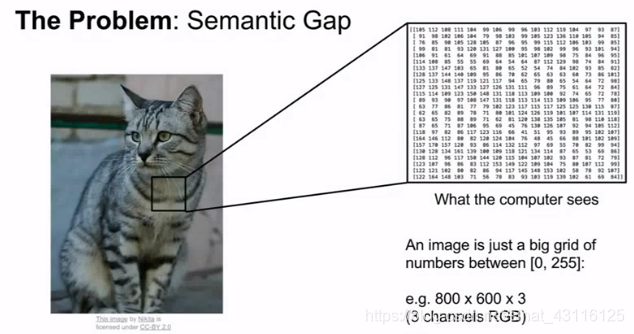
识别出这张图片是非常具有难度的,因为存在以下挑战:
- Viewpoint variation(视角变换)
- Background clutter(背景混乱)
- Illumination(照明)
- Occlusion(遮挡)
- Deformation(变形)
- Intra class variation(类内差异)
尽管如此,人们还是尝试写出一组硬编码的规则(high-end coded rules),来识别不同的物体,如Hubel和Wiesel的研究,边缘识别对于图形检测是非常重要的,所以我们可以计算出图像的边缘,根据各种边、角、各种形状分类好,根据这种规则来识别图像,但是这种方法并不好,很容易出错,而且再识别其他事物时还要重新再来一遍,所以这不是一种可推演的方法。
基于此,我们想到了利用数据驱动的方法,并不用写具体的分类规则来识别一只猫或一条狗,取而代之的是,我们从网上抓取大量猫、狗、飞机等等的图片数据集,整理出不同类别图片的示例图:

根据收集到的数据集,我们训练机器来分类这些图片,机器根据某种方法进行总结然后生成一个模型,总结出这些图片的核心知识要素,然后我们利用这个模型尝试识别新的图片。
一个最简单的分类器称为最近邻(Nearest Neighbor)
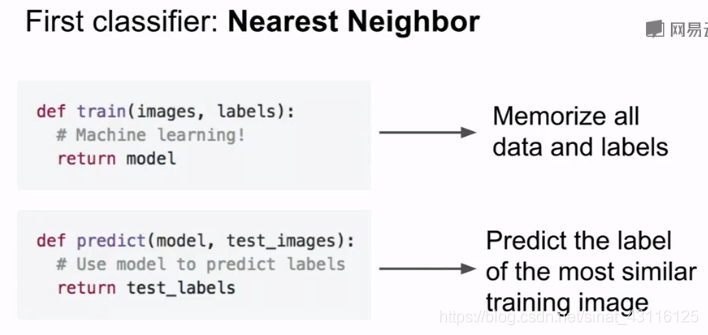
在训练过程中无需做其他事,仅单纯记录所有的训练数据,在图片预测的步骤,我们拿出新的图片,在训练数据中去寻找与新图片最相似的,然后基于此给出一个标签。
CIFER-10数据集
CIFER-10给出10个类别每个类别给出5万张训练图,再给出1万张测试图用来检测算法。
那么两张图片如何比较呢?
- 方式一: L1 distance(Manhatten distance)
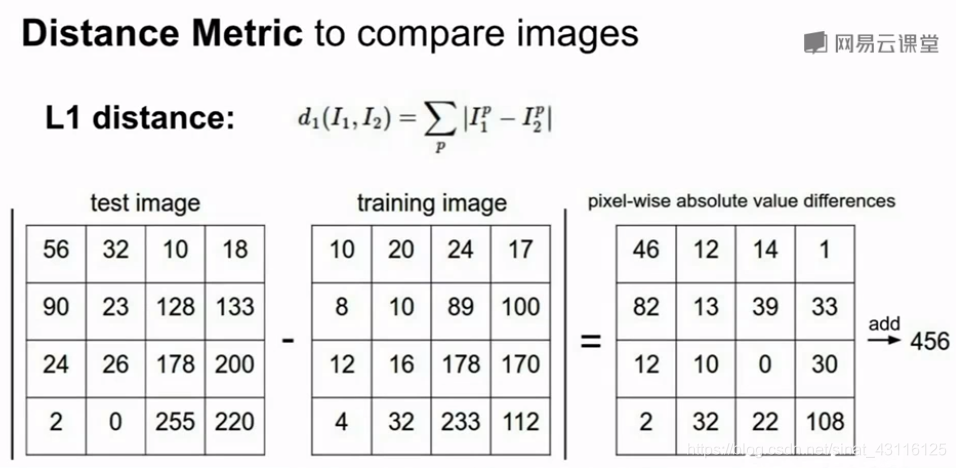
对图片中的单个像素进行比较,如图,假设测试图片和训练图片均是4*4的小图片,对应位置的像素值相减,再取绝对值,最后将处理后的单个像素值全部加起来,所以这两幅图片中有456个不同之处。但是这种方式有很大的缺陷——训练时间短但是测试时间长。
在实际工作中,最近邻算法的表现
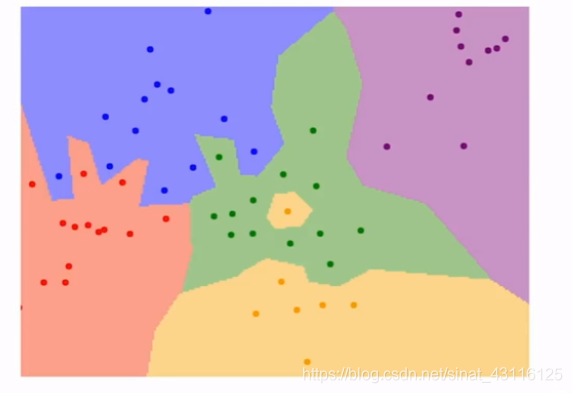
最近邻算法根据点的颜色对空间进行切割并着色,但我们可以看到边缘不够圆滑,且黄色的噪点没有消除掉。基于这种现象,K-近邻法诞生了,根据距离的度量,找到最近的k个点然后在这些相邻的点中进行投票,根据票数多的近邻点预测出结果。
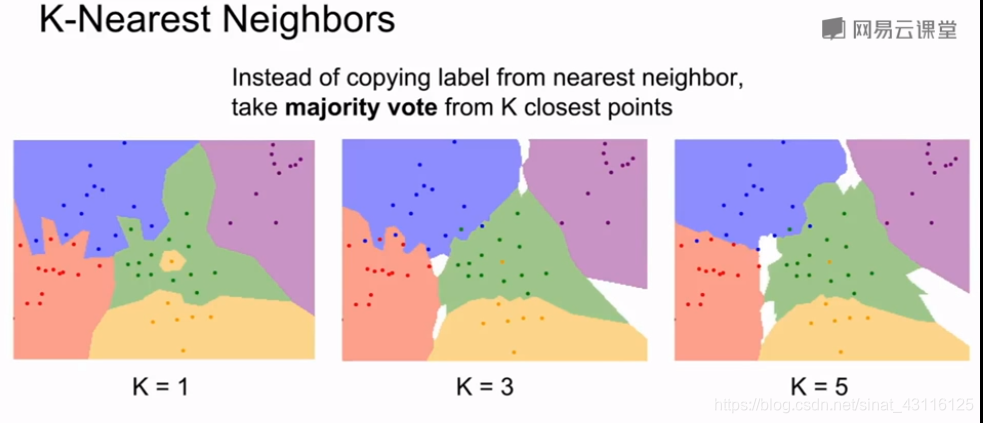
从图中可以明显看出,k=3时黄色噪点被消除了,k=5时蓝色和红色的边界明显变得平滑。
这篇关于我的cs231n学习笔记(1)lecture2-data driven approach的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







