本文主要是介绍Chart 9 Adreno GPU的 OpenCL 扩展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 9.1 OS-dependent vendor extensions
- 9.1.1 Performance hint (cl_qcom_perf_hint)
- 9.1.2 Priority hint for context creation (cl_qcom_priority_hint)
- 9.1.3 Recordable command queue (cl_qcom_recordable_queues)
- 9.1.4 cl_qcom_protected_context
- 9.1.5 cl_qcom_create_buffer_from_image
- 9.1.6 cl_qcom_onchip_global_memory
- 9.1.7 cl_qcom_extended_query_image_info
- 9.2 Subgroup
- 9.2.1 Subgroup size (wave size) selection
- 9.2.2 Subgroup shuffle
- 9.3 图像相关操作
- 9.3.1 卷积
- 9.2.3 Box Filter
- 9.3.3 绝对值差之和(SAD)和平方差之和(SSD)
- 9.3.4 Bicubic Filter
- 9.3.5 (强大的)图像矢量化操作
- 9.3.5.1 2x2 read
- 9.3.5.2 4x1 read
- 9.3.5.3 image write
- 9.3.6 压缩图片
- 9.4 机器学习
- 9.4.1 SNPE/QNN(神经网络处理引擎)
- 9.4.2 OpenCL ML SDK for Adreno GPU
- 9.4.3 Tensor virtual machine (TVM) and the `cl_qcom_ml_ops` extension
- 9.4.3.1 TVM
- 9.4.3.2 How TVM works with the `cl_qcom_ml_ops` extension
- 9.4.3.3 How to use TVM with the cl_qcom_ml_ops extension
- 9.4.4 Other features for ML
- 9.4.4.1 Support of bfloat16 data
- 9.5 Other enhancements
- 9.5.1 8-bit 操作
- 9.5.2 cl_qcom_bitreverse
前言
OpenCL平台或设备可能通过扩展机制支持未纳入核心标准的功能。硬件供应商可以根据实际进行实现:
- KHR扩展由OpenCL标准工作组批准,但供应商支持是可选的。表示这些扩展的字符串以cl_khr开头。
- 这些扩展通常由多个供应商支持,并且如果它们声称支持这些扩展,就必须通过一些一致性测试。
- KHR扩展的规范可在Khronos的官方OpenCL网站上找到。
- 一些KHR扩展可能会在OpenCL标准的新版本中成为核心功能。
- EXT扩展由OpenCL标准工作组批准,但供应商支持是可选的。表示这些扩展的字符串以cl_ext开头。
- 这些更多用于实验目的,通常没有符合性测试。
- 这些EXT扩展可能会成为KHR甚至核心功能。
- 厂商扩展具有特定的语法,通常仅在特定厂商的平台上运行。它们的名称通常包含厂商公司名称的首字母缩写。
- 例如,Adreno GPU 中的 OpenCL 厂商扩展中包含 “qcom”,例如cl_qcom_accelerated_image_ops
此外,还可能存在私有或内部扩展,供应商可能不会公开,但可能提供给客户。扩展可以针对 OpenCL 平台或 OpenCL 设备:
-
在给定平台上可用的扩展可以通过 API 函数 clGetPlatformInfo 获取,参数 cl_platform_info 设置为 CL_PLATFORM_EXTENSIONS。
-
对于 OpenCL 设备可用的扩展可以通过 API 函数 clGetDeviceInfo 获取,设备信息参数设置为 CL_DEVICE_EXTENSIONS。
这两个函数将返回可用扩展的名称字符串列表。在使用扩展时有一些注意事项:
- 一个扩展可能有不同的版本。
- 厂商的扩展可能会被厂商弃用或取消支持。
- 扩展可能成为 OpenCL 标准的核心特性。如果一个扩展不可用,请检查核心规范是否已经采用。
- 开发人员在使用扩展之前必须查询平台上可用的扩展列表,以提高可移植性。
以下表格显示了在 Snapdragon 888 设备上支持的 KHR 和厂商扩展。这些扩展的详细文档可在 Adreno OpenCL SDK 中找到,可以从 QTI 开发者网络网站(https://developer.qualcomm.com)下载。
在接下来的几节中,将跳过 KHR 扩展,并提供 Adreno GPU 可用的厂商扩展的高级概述。


9.1 OS-dependent vendor extensions
这一部分介绍的一些扩展可能依赖于 Android 操作系统及其底层设计,这可能会发生变化。检查 OpenCL SDK 开发文档以获取扩展详细信息。本文档其他部分介绍的扩展将被跳过。例如,零拷贝扩展的详细信息在第 7.4 节中。
9.1.1 Performance hint (cl_qcom_perf_hint)
该扩展允许应用程序在 OpenCL 上下文中请求所需设备的性能级别。更高的性能意味着设备上的频率更高。该扩展支持三个性能提示级别,包括高、正常和低,分别使用标志 CL_PERF_HINT_HIGH_QCOM、CL_PERF_HINT_NORMAL_QCOM 和 CL_PERF_HINT_LOW_QCOM。
- CL_PERF_HINT_HIGH_QCOM 是 OpenCL 上下文中设备的默认设置(请求设备的最高性能级别)。
- CL_PERF_HINT_NORMAL_QCOM 是一种平衡的性能设置,由 GPU 频率和功耗管理动态设置。
- CL_PERF_HINT_LOW_QCOM 请求一个性能设置,优先考虑较低的功耗。
使用这个扩展的两种方式:
- 在使用 clCreateContext 函数创建上下文时,在上下文属性参数中指定性能提示标志。以下是一个示例:
cl_context_properties properties[] = {CL_CONTEXT_PERF_HINT_QCOM,CL_PERF_HINT_LOW_QCOM, 0}; clCreateContext(properties, 1, &device_id, NULL, NULL, NULL); - 使用 clSetPerfHintQCOM,这是一个独立的 API 函数,用于为现有上下文设置性能提示属性。该函数可用于设置或更新 CL_CONTEXT_PERF_HINT_QCOM 属性,无论在上下文时间是否将其指定为上下文属性之一。以下是一个示例:
clSetPerfHintQCOM(context, CL_PERF_HINT_NORMAL_QCOM); .
9.1.2 Priority hint for context creation (cl_qcom_priority_hint)
(内核优先级)该扩展允许应用程序指定要提交到 OpenCL 上下文中的设备的已入队内核的期望优先级。与性能提示标志一样,它定义了三个优先级级别:
- 高优先级,CL_PRIORITY_HINT_HIGH_QCOM,相较于上下文中其他较低优先级的内核,较高优先级的内核会
更早的被设备处理。 - 普通优先级,CL_PRIORITY_HINT_NORMAL_QCOM,这是默认行为。如果未指定优先级,设备将选择该策略并作用于上下文。
- 低优先级,CL_PRIORITY_HINT_LOW_QCOM,与高优先级相反,较低优先级的内核
晚于上下文中其他较高优先级的内核提交到设备上。
这个提示应该在创建上下文时使用 clCreateContext 作为上下文属性提供。
9.1.3 Recordable command queue (cl_qcom_recordable_queues)
内核入队函数调用 clEnqueueNDRangeKernel 是关键且要求较多的函数,它将内核分派到 GPU 硬件,因为它要求应用程序配置和验证许多内核参数,如全局工作大小、工作组大小、事件依赖性等。对于需要重复处理的内核,比如视频处理应用,在每帧中重复执行相同内核的情况下,开发者可以最小化(反复)设置参数的开销。
- 该扩展引入了一组新的 API 函数,用于记录内核入队的序列,而不是重复这些操作。一个序列只需要记录一次,但可以多次调度。在记录的序列中,称为记录的序列,任何内核的参数都可以修改,而无需重新记录整个命令序列。因此,该扩展可以节省 CPU 功耗并提高调度的延迟。以下是该扩展的使用方式:
- 需要一个命令队列进行记录,必须使用 clCreateCommandQueue 创建具有可记录属性 CL_QUEUE_RECORDABLE_QCOM 的队列。
- 必须使用名为 clNewRecordingQCOM 的函数创建一个记录对象。
- 通过 clNewRecordingQCOM 创建的记录对象启动记录,并使用标准的入队函数 clEnqueueNDRangeKernel。
- 目前只能记录 clEnqueueNDRangeKernel。
- 使用 clEndRecordingQCOM 来结束记录。
- clEnqueueRecordingQCOM 用于将记录队列中的所有内核排队等待 GPU 执行,这需要记录对象和一个“活跃”的命令队列。
- 这个函数可用于更新记录队列中内核的参数。
- 与记录的命令队列不同,此函数所使用的“活跃”命令队列必须是有序的。
- 定义了一种机制,用于指定要更新的内核,要更改的参数列表,以及要更改的每个参数的新值。
- 所有内核参数都可以更改,包括内核参数、全局大小等。
- 应用程序可以选择不更新记录。
- 这个扩展不适用于kernel enqueue kernel(KEK)功能或 printf。
- Khronos 的 OpenCL 工作组一直在进行努力,以标准化一个支持类似功能但更通用的 KHR 扩展。
- 未来,一旦 Khronos 扩展定稿,这个扩展将被支持,作为 Khronos 扩展的补充。
9.1.4 cl_qcom_protected_context
此扩展允许应用程序创建所谓的受保护的 OpenCL 上下文。在受保护的上下文上创建的 OpenCL 命令队列也被隐式地视为受保护的。受保护的 OpenCL 上下文使得可以使用特定 Qualcomm GPU 上可用的内容保护功能。此功能的主要目的是将内存分隔为受保护和非受保护的区域,并防止从受保护区域复制数据到非受保护区域。要使用此功能,必须创建一个带有 CL_CONTEXT_PROTECTED_QCOM 属性的上下文:
cl_context_properties properties[] = {CL_CONTEXT_PROTECTED_QCOM, 1, 0};protected_context = clCreateContext(properties, 1, &device_id, NULL, NULL, &err);
一旦使用上述上下文创建了受保护的命令队列,在整个应用程序中使用了它:
protected_queue = clCreateCommandQueue(protected_context, device_id, 0, &err);
在 Android 上创建受保护的内存对象基本上有两种方式:
- 可以使用 GRALLOC_USAGE_PROTECTED 标志分配受保护的图形缓冲区,并且可以通过使用 cl_qcom_android_native_buffer_host_pointer 扩展与 clCreateBuffer 或 clCreateImage2D 在 OpenCL 中访问。
- 可以使用 ION_SECURE 标志从受保护的堆创建受保护的 ION 分配,并且可以通过使用 cl_qcom_ion_host_pointer 扩展与 clCreateBuffer 或 clCreateImage2D 在 OpenCL 中访问。
在这两种情况下,缓冲区都被 OpenCL 视为受保护的内存对象。在 OpenCL 应用程序中,如果要将一个或多个受保护的内存对象作为参数入队到内核中,只能使用受保护的命令队列。
9.1.5 cl_qcom_create_buffer_from_image
在 OpenCL 中,图像对象是一种不透明的数据结构,由 OpenCL API 中定义的函数进行管理。开发人员无法访问图像对象中存储数据的底层细节。与可以使用指针直接访问的缓冲区对象不同,内核中必须使用像 image_readf/image_writef 这样的内置图像读取和写入函数来访问图像数据。
在某些情况下,开发人员可能希望在 OpenCL C 语言中以原始指针的形式访问图像数据,而不是使用内置的图像读写函数。这个扩展可以在以下用例中发挥作用:
- 通过 OpenGL 和 OpenCL 互操作扩展间接地从 EGL 外部图像读取或写入。
- 有经验的开发人员可能希望使用单个内存加载/存储操作读取/写入多个像素。
- 图像对象中的数据可能需要同时输入到一个仅接受缓冲区对象的内核和另一个仅接受图像对象的内核中。
使用这个扩展,可以通过以下函数从现有的图像对象创建一个新的原始缓冲对象:
cl_mem clCreateBufferFromImageQCOM(cl_mem image, cl_mem_flags flags, cl_int *errcode_ret)
其中,图像是具有一些限制的有效图像。对于图像类型、布局以及并发读/写访问,有一些要求:
- 它支持
除以下图像类型之外的所有图像:- 图像类型 CL_MEM_OBJECT_IMAGE1D_BUFFER
- 使用 CL_MEM_USE_HOST_PTR 创建的图像。
- 数据布局:
- 返回的缓冲区引用为图像分配的数据存储,并指向该数据存储中的原点像素。
- 数据布局等同于使用 clEnqueueMapImage 时 origin 为 (0, 0, 0) 且 region 为 (width, height, depth) 时产生的布局。
- 从parent_image 缓冲区中创建的缓冲区的图像。
- 为了正确访问返回缓冲区中的像素数据,客户端必须使用 clGetDeviceImageInfoQCOM 查询父图像的两个参数:
- 行间距,使用 CL_BUFFER_FROM_IMAGE_ROW_PITCH_QCOM。
- 切片间距,使用 CL_BUFFER_FROM_IMAGE_SLICE_PITCH_QCOM。
- 读写并发性
- 未定义:
- 对缓冲区对象及其 parent_image 进行并发读写是未定义的。
- 并发读写从相同 parent_image 创建的缓冲区对象是未定义的。
- 支持:
- 仅支持从缓冲区对象及其 parent_image 对象
并发读取。 - 定义了从同一图像创建的
多个缓冲区对象之间的并发读取。
- 仅支持从缓冲区对象及其 parent_image 对象
- 未定义:
9.1.6 cl_qcom_onchip_global_memory
这个扩展提供了在Adreno GPU的快速访问片上全局内存(以下简称片上全局内存)中创建OpenCL缓冲区和图像的功能。一旦创建了这些对象,它们可以在OpenCL内核中像常规全局内存对象一样使用。
如果存在cl_qcom_other_image,此扩展进一步允许从在片上全局内存中创建的OpenCL缓冲区创建平面图像。
默认情况下,在内核退出后,片上全局内存的内容不会被保留。然而,应用程序可以利用cl_qcom_recordable_queues扩展使片上全局内存在两个或多个内核之间传递数据。片上全局内存的内容将在记录的入队期间始终有效。因此,应用程序可以使用片上全局内存将一个内核的输出链接到下一个内核的输入,只要这些内核是同一记录的一部分。片上全局内存,在同一记录的不同入队之间不会被保留。记录中的第一个内核必须将片上全局内存视为未初始化。
通过在片上全局内存中分配缓冲区和图像,而不是全局分配,应用程序可以实现功耗和性能的改进。一个例子是在内核流水线中使用片上全局内存作为中间缓冲区。
请参考Adreno OpenCL SDK中的扩展文档和演示片上全局内存用法的示例。
9.1.7 cl_qcom_extended_query_image_info
Adreno GPUs支持的两个供应商扩展,cl_qcom_other_image和cl_qcom_compressed_image(都在第9.3节中介绍),允许开发人员创建可在内核中使用的平面和压缩图像。
此扩展,cl_qcom_extended_query_image_info,通过启用应用程序查询图像属性,如图像大小、图像元素大小、行间距、切片间距和基于图像格式和图像描述符的对齐方式,来补充上述扩展。不需要创建图像即可查询这些属性。
该扩展接受传统的RGBA图像和非传统图像,如NV12、TP10、MIPI打包、Bayer模式、平铺和压缩图像。
请参考Adreno OpenCL SDK中的扩展文档和演示cl_qcom_extended_query_image_info用法的示例。
9.2 Subgroup
OpenCL 2.0引入了一个名为cl_khr_subgroups的KHR核心扩展,通过这个扩展,引入了一系列子组函数,以促进子组内工作项之间的数据共享,从而为协作工作项提供了细粒度的协同工作。如果没有这个功能,工作项之间的数据共享必须依赖于本地或全局内存,并且还需要昂贵的工作组屏障同步以确保数据一致性。
在OpenCL 3.0中,这个扩展中的许多子组函数已经被采纳为核心特性,比如sub_group_broadcast、sub_group_reduce_、sub_group_scan_exclusive_、sub_group_scan_inclusive_,其中可以是add、min或max。
Adreno GPU有几个与子组相关的扩展,提供额外的功能,详见以下各节。
9.2.1 Subgroup size (wave size) selection
Adreno GPU通常支持两种不同的子组大小,即半波大小和全波大小。一个内核可以在两种模式下运行,可能导致不同的性能表现。编译器根据预测内核性能的启发式方法选择最佳的子组大小。在某些情况下,应用程序可能通过使用此扩展覆盖编译器的选择来获得更好的结果。该扩展提供了一个内核属性,使应用程序能够指定首选的子组大小。
要使用此扩展,必须在程序中启用#pragma cl_qcom_reqd_sub_group_size,并设置波大小属性。
#pragma OPENCL EXTENSION cl_qcom_reqd_sub_group_size: enable__attribute__((qcom_reqd_sub_group_size("half")))
kernel void half_sub_group_kernel(...){ ... }__attribute__((qcom_reqd_sub_group_size("full")))kernel void full_sub_group_kernel(...){ ... }
以下是一些建议:
- 在不同层次的Adreno GPU上,sub_group_size可能会变化,可能最大为128,最小为16。
- 在使用之前,开发者应该通过OpenCL设备查询API获取sub_group_size的值。
- 为了最大程度提高可移植性,开发者应该编写能够适应不同波大小的代码。
9.2.2 Subgroup shuffle
Adreno GPUs支持多个子组洗牌函数,如cl_qcom_subgroup_shuffle,如表9-2所示。这些洗牌函数的目标是将source_value中的数据从当前工作项传输到目标工作项。关键是确定sub_group_local_id,即子组中的目标工作项。这个变量取决于一些参数,如下所示:
- 操作是向上还是向下:
- 向上:目标 sub_group_local_id = source sub_group_local_id + offset。
- 向下:目标 sub_group_local_id = source sub_group_local_id – offset。
- 当计算得到的 sub_group_local_id 超出范围时的行为:
- 丢弃:不进行传输。
- 旋转:回转。新的 sub_group_local_id 就像对子组操作的宽度取模。
- 宽度模式:
- CLK_SUB_GROUP_SHUFFLE_WIDTH_WAVE_SIZE_QCOM:应用于整个子组。
- CLK_SUB_GROUP_SHUFFLE_WIDTH_W4_QCOM:在子组中的四个工作项中执行洗牌操作。
- CLK_SUB_GROUP_SHUFFLE_WIDTH_W8_QCOM:在子组中的八个工作项中执行洗牌操作。
为了使用洗牌函数,将 pragma 添加到内核中:
#pragma OPENCL EXTENSION cl_qcom_subgroup_shuffle: enable
该扩展支持的数据类型包括 uchar、char、ushort、short、uint、int、ulong、long、float 和 half(如果支持 cl_khr_fp16)。不支持矢量。

一些建议:
- 分支
- 这些 shuffle 内建函数需要由参与 shuffle 操作的子组中的所有工作项一起执行。
- 如果在条件语句中调用 shuffle 函数,并且条件不被所有工作项满足,可能会导致未定义的行为。
- 工作项数量的要求:
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_WAVE_SIZE_QCOM 时,请确保有足够多的工作项可用于执行,数量应大于或等于子组大小。
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_W4_QCOM 时,请确保有四个或更多的工作项。
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_W8_QCOM 时,请确保有八个或更多的工作项
- 对 offset 的要求:
- 它必须是常量。参与洗牌操作的所有工作项应该使用相同的偏移量。工作项之间偏移值的任何分歧都会导致未定义的结果。
- 传递给洗牌操作的偏移值不应超过该洗牌操作指定的宽度。违反此规则将导致未定义的结果。
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_WAVE_SIZE_QCOM 时,偏移应小于最大子组大小,即由 CL_KERNEL_MAX_SUB_GROUP_SIZE_FOR_NDRANGE_KHR 返回。
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_W8_QCOM 时,偏移应小于八。
- 当 width 为 CLK_SUB_GROUP_SHUFFLE_WIDTH_W4_QCOM 时,偏移应小于四。
9.3 图像相关操作
Adreno GPU内置硬件模块,加速常见的滤波操作,包括卷积、 Box filter、SAD(绝对差之和)和SSD(平方差之和)等。使用这些模块可能比使用通用的OpenCL内核语言具有更好的性能或更低的功耗。
9.3.1 卷积
卷积滤波操作将图像样本值的矩阵与滤波权重的矩阵相乘,并将结果求和以生成输出值。有关该扩展的文档和示例,请参考Adreno OpenCL SDK。该扩展要求应用程序创建一个特殊的图像对象,并提供对权重矩阵的详细描述,如以下示例所示:
weight_img_desc.image_desc.image_type =CL_MEM_OBJECT_WEIGHT_IMAGE_QCOM;
weight_img_desc.image_desc.image_width = filter_size_x;
weight_img_desc.image_desc.image_height = filter_size_y
weight_img_desc.image_desc.image_array_size = num_phases;
weight_img_desc.image_desc.image_row_pitch = 0; // must set to zero
weight_img_desc.image_desc.image_slice_pitch = 0; // must set to zero
weight_img_desc.weight_desc.center_coord_x = center_coord_x;
weight_img_desc.weight_desc.center_coord_y = center_coord_y;
// specify separable filter. Default (flags=0) is 2D convolution filter
weight_img_desc.weight_desc.flags = CL_WEIGHT_IMAGE_SEPARABLE_QCOM;
权重矩阵描述符包含进行操作所需的所有信息。除了常规的图像属性,如宽度和高度,还需要权重矩阵的中心坐标以及卷积的类型,即它是否是可分离的。在此扩展中,支持两种类型的卷积滤波器,即2D卷积滤波器和可分离卷积滤波器。
对于 2D 卷积滤波:
- 该滤波器是由一组(filter_size_x * filter_size_y)个权重元素指定的二维矩阵。
- 滤波器的中心点坐标是基于空间区域左上角的原点。
- 图9-1说明了一个大小为 4 x 4 的二维卷积滤波器,其中心点位于坐标(cx = 1,cy = 1)。
- 图像矩阵中位于(3, 2)的像素与权重矩阵中位于(1, 1)的像素相乘。
- 图像中的其他像素与权重矩阵中的相应像素相乘。
- 位于(3, 2)的输出值将是前面步骤的总和。

- 可分离卷积核:
- 该滤波器是一个二维滤波器,可以通过在 x 和 y 方向上指定两个一维滤波器来定义,使它们的乘积产生二维滤波器。
- 可分离的滤波器可以通过使用一维水平滤波器对每一行进行一维卷积,然后通过使用一维垂直滤波器对结果的每一列进行卷积来实现。
- 结果在数学上与直接为每个像素应用二维滤波器相同。
- 对于具有许多阶段的用例,可分离滤波器可以提供性能优势,因为计算数量减少了一个数量级。
- 图 9-2 显示了一个二维滤波器及其相关的可分离滤波器的示例。

第9-3表列出了权重矩阵的关键参数及其描述和限制。
Table 9-2
| Parameters | Description and Requirement |
|---|---|
| image type flags | CL_MEM_READ_ONLY 和 CL_MEM_COPY_HOST_PTR。权重图像只支持从内核进行读访问 |
| image_format | 使用 clGetSupportedImageFormats 进行查询,将图像类型设置为 CL_MEM_OBJECT_WEIGHT_IMAGE_QCOM。 |
| 2D 卷积核; num_phases | num_phases = num_phase_x * num_phase_y。这要求这两个值(num_phase_x 和 num_phase_y)都必须是2的幂。每个滤波阶段的权重值都组织成一个2D切片,大小为 (filter_size_x * filter_size_y)。 |
| 可分离卷积核:num_phases | num_phases = num_phase_x = num_phase_y(必须是2的幂)。每个滤波阶段的1D水平和1D垂直滤波器的权重都组织成一个2D切片,切片高度为2,切片宽度为max(filter_size_x, filter_size_y)。 |
| 如果num_phases大于1,则权重切片。 | 权重切片必须组织成一个2D数组,其切片数量等于num_phases。在内建执行期间,相位值是根据滤波器中心点的坐标相对于像素中心的亚像素偏移来计算的。 |
卷积函数限制:
- image、 weight_image 和 sampler 对于执行 qcom_convolve_imagef 函数的
工作组中的所有工作项必须是一致的。 - 滤波器阶段的数量(number_phases)不得超过平台的最大阶段数,可以使用 clGetDeviceInfo 查询,其中 param_name 设置为 CL_DEVICE_HOF_MAX_NUM_PHASES_QCOM。
- filter_size_x/y 不得超过平台的最大滤波器尺寸,可以使用 clGetDeviceInfo 查询,其中 param_name 设置为 CL_DEVICE_HOF_MAX_FILTER_SIZE_X_QCOM 和 CL_DEVICE_HOF_MAX_FILTER_SIZE_Y_QCOM。
- 内建卷积滤波器不适用于多平面图像(multi-plane planar images)。
9.2.3 Box Filter
Box filter 是一种线性操作,它取源图像上由 box filter 覆盖的空间区域内的像素的平均值。Box filter 由 (box_filter_width, box_filter_height) 和 box filter 中心位置的坐标指定。在数学上,以坐标 (x, y) 为中心的 box filter 产生的像素的线性平均计算如下:
box_filter(x, y) = sum(weight(i, j) * pix(i, j)) / (box_width * box_height)
其中,(i, j) 是由 box filter 覆盖的像素的坐标。重要的是要注意,有些像素可能只被 box filter 部分覆盖。因此,weight(i, j) 根据像素(i, j)被 box filter 覆盖的程度进行调整。例如,如果像素被 50% 覆盖,权重将为 0.5。图 9-3 显示了将 2x2 box filter 应用于 5x6 图像的示例。权重由内置硬件自动计算。
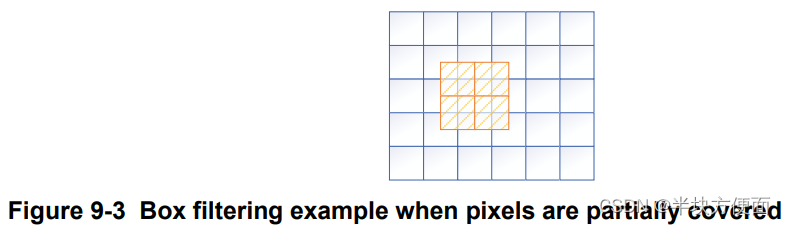
由于Box Filter 的中心坐标为 (2, 2),有九个像素被该滤波器覆盖。根据滤波器覆盖的像素,权重如下调整:
W(0, 0) = 0.25 W(1, 0) = 0.5 W(2, 0) = 0.25
W(0, 1) = 0.5 W(1, 1) = 1 W(2, 1) = 0.5
W(0, 2) = 0.25 W(1, 2) = 0.5 W(2, 1) = 0.25
图9-4展示了一个3x3的滤波器,其中所有来自源图像的像素都被完全覆盖。因此,对于这种滤波,每个像素的权重是相等的。
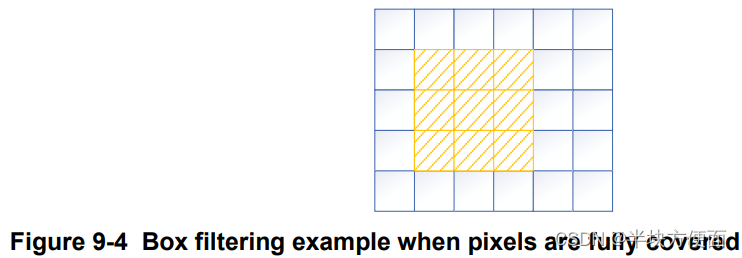
内建的 Box Filter 函数定义如下:
float4 qcom_box_filter_imagef(image2d_t image, sampler_t sampler, float2 coord, const qcom_box_size_t box_size);
- 参数 image 指定一个有效的可读图像,对其应用Box Filter
- 参数 sampler 指定读取 image 时的采样模式
- 参数 coord 指定 Box Filter 中心在源图像平面上的位置坐标。
只能使用浮点坐标,否则内核将在编译时失败。 - 参数 box_size 指定 box_filter_width 和 box_filter_height。box_size 必须作为 OpenCL 内核参数传递,并且在内核运行时必须保持不变。
限制:
-输入 image、box_size 和 sampler 必须对执行 qcom_box_filter_imagef 函数的工作组内的所有工作项保持一致。
- box_size.x/.y 不得超过平台的最大盒式滤波器大小,可以使用 clGetDeviceInfo 查询,参数 param_name 设置为 CL_DEVICE_HOF_MAX_FILTER_SIZE_X_QCOM 和 CL_DEVICE_HOF_MAX_FILTER_SIZE_Y_QCOM。
- box_size 必须作为 OpenCL 内核参数传递,并且在内核运行时必须保持不变。
- built-in box filter 函数不适用于多平面图像。
9.3.3 绝对值差之和(SAD)和平方差之和(SSD)
块匹配(Block matching)操作测量目标图像内的块与参考图像内的参考块之间的相关性(或相似性)。有两个用于测量两个图像块之间相关性的误差度量:绝对差值和平方差值。
假设有两个候选块 A 和 B,我们想知道哪一个与块 R 最匹配。通过计算 A 和 R 之间的绝对差值和 B 和 R 之间的绝对差值,我们可以选择导致最小误差或最小绝对差值的块。这可以推广到在一组 N 个目标块中搜索参考块 R 的最小绝对差值。这两个函数的定义如下:
float4 qcom_block_match_sadf(image2d_t target_image, sampler_t sampler, float2 coord, uint2 region, image2d_t reference_image, uint2 reference_coord);float4 qcom_block_match_ssdf(image2d_t target_image, sampler_t sampler, float2 coord,uint2 region, image2d_t reference_image, uint2 reference_coord);
这两个函数与本节中的卷积和 Box Filter 操作有类似的要求。此外,指定图像上目标块和参考块大小的 region 和 reference_coord 必须是整数。
9.3.4 Bicubic Filter
除了 OpenCL 标准中定义的过滤器模式(例如 CLK_FILTER_LINEAR 或 CLK_FILTER_NEAREST)之外,新的 Adreno GPU 中添加了一种称为 CL_FILTER_BICUBIC_QCOM 的过滤器模式,允许开发人员使用硬件加速的双三次插值。要使用此功能,需要在内核中使用名为 cl_qcom_filter_bicubic_enable 的 pragma。使用 QCOM_CLK_FILTER_BICUBIC 过滤器模式时,图像读取函数 read_imagef 返回图像元素的 4x4 方格的加权平均值。给定 2D 图像的输入坐标 (x, y),可以如下获取 4x4 方格:
x0 = (int) floor(x - 1.5f); y0 = (int) floor(y - 1.5f);
x1 = x0 + 1; y1 = y0 + 1;
x2 = x1 + 1; y2 = y1 + 1;
x3 = x2 + 1; y3 = y2 + 1;a = frac(x - 0.5f);
b = frac(y - 0.5f);
中 frac(x) 表示 x 的小数部分,计算方式为 x - floor(x)。然后,权重计算如下:
w_u0 = - 0.5f * a + 1.0f * (a * a) - 0.5f * (a * a * a);
w_u1 = 1.0f - 2.5f * (a * a) +1.5f * (a * a * a);
w_u2 = 0.5f * a + 2.0f * (a * a) - 1.5f * (a * a * a);
w_u3 = - 0.5f * (a * a) + 0.5f * (a * a * a);w_v0 = - 0.5f * b + 1.0f * (b * b) - 0.5f * (b * b * b);
w_v1 = 1.0f - 2.5f * (b * b) + 1.5f * (b * b * b);
w_v2 = 0.5f * b + 2.0f * (b * b) - 1.5f * (b * b * b);
w_v3 = -0.5f * (b * b) + 0.5f * (b * b * b);
计算得到的图像元素值如下:
refOut = (t00*w_v0 + t01*w_v1+ t02*w_v2 + t03*w_v3) * w_u0 +(t10*w_v0 + t11*w_v1+ t12*w_v2 + t13*w_v3) * w_u1 +(t20*w_v0 + t21*w_v1+ t22*w_v2 + t23*w_v3) * w_u2 +(t30*w_v0 + t31*w_v1+ t32*w_v2 + t33*w_v3) * w_u3;
txy是(x,y)位置的像素值,如果上述方程中选择的任何 txy 引用图像之外的位置,则使用边框颜色作为 txy 的颜色值。
注意,built-in 的双三次硬件加速具有有限的精度。因此,在使用它时,检查您的应用程序的精度要求非常重要。有关更多详细信息,请参阅 Adreno OpenCL SDK 中关于 cl_qcom_filter_bicubic 的文档和示例。
9.3.5 (强大的)图像矢量化操作
在标准的 OpenCL 中,像 read_imagef/write_imagef 等的图像读取/写入函数只能在单个操作中读取或写入一个像素(根据图像格式的不同,可能是一个或多个分量)。cl_qcom_vector_image_ops 扩展引入了一组新的 OpenCL 内建函数,允许以单个操作读取和写入一组 OpenCL 图像元素。它们允许应用程序跨多个图像元素读取或写入单个分量。因此,它们被称为矢量图像操作,可以提供潜在的性能增益以及开发的便利性。
这些内建函数适用于一系列输入图像格式,它们的名称指示了返回值的数据类型以及它们的访问模式。以下是一些矢量图像读取内建函数的示例:
9.3.5.1 2x2 read
qcom_read_imageX_2x2 操作从输入图像中读取形成一个 2x2 矢量的四个元素:
float4 qcom_read_imagef_2x2(image2D_t image, sampler_t sampler, float2 coord, int compid);
half4 qcom_read_imageh_2x2(image2D_t image, sampler_t sampler, float2 coord, int compid);
uint4 qcom_read_imageui_2x2(image2D_t image, sampler_t sampler, float2 coord, int compid);
int4 qcom_read_imagei_2x2(image2D_t image, sampler_t sampler, float2 coord, int compid);
coord 指定的基准点是此向量的左上角。element[0] 是左下角的元素。四个输出元素按逆时针顺序从 2x2 向量的 element[0] 开始排序。具体而言,element[1] 是右下角,element[2] 是右上角,element[3] 是左上角(基准点),如图9-5所示。

9.3.5.2 4x1 read
qcom_read_imageX_4x1 操作从输入图像中以 4x1 向量的形式读取四个元素:
float4 qcom_read_imagef_4x1(image2d_t image, sampler_t sampler, float2 coord, int compid);
half4 qcom_read_imageh_4x1(image2d_t image, sampler_t sampler, float2 coord, int compid);
uint4 qcom_read_imageui_4x1(image2d_t image, sampler_t sampler, float2 coord, int compid);
int4 qcom_read_imagei_4x1(image2d_t image, sampler_t sampler, float2 coord, int compid);
将 element[0] 表示为位于基准点 处的元素。四个输出元素按照从左到右的顺序排列,从 4x1 向量的 element[0] 开始。具体而言,element[0] 是最左侧的元素,然后是 element[1]、element[2] 和 element[3]。

9.3.5.3 image write
Adreno GPU 支持一组新的内建矢量图像写入函数,其命名规范为 qcom_write_image##datatypev_##pattern_suffix##_format_suffix##。函数名称明确指定了它支持的图像格式、矢量格式以及目标图像的格式和平面。这些图像写入函数有许多变种。以下是一些示例:
qcom_write_imagefv_2x1_n8n00(image2d_t image, int2 coord, float color[2])
qcom_write_imagefv_2x1_n8n01(image2d_t image, int2 coord, float2 color[2])
qcom_write_imagefv_2x1_n10p00(image2d_t image, int2 coord, float color[2])
qcom_write_imagehv_3x1_n10t00(image2d_t image, int2 coord, half color[3])
qcom_write_imageuiv_4x1_u10m00(image2d_t image, int2 coord, uint color[4])
某些函数需要特定的图像格式,如 NV12_Y 和 TP10_UV。Y only 和 UV only 图像是 multi-plane planar images 的single-plane衍生物。它们可以通过使用 cl_qcom_extract_image_plane 扩展来创建。(我没读懂,不好解释)
重要的是要理解这些函数必须与支持的图像类型和数据类型一起使用。否则,返回值将是未定义的。例如,用于读取浮点数的 qcom_read_imagef_2x2 和 qcom_read_imagef_4x1 函数仅支持使用格式如 CL_FLOAT、CL_HALF_FLOAT、CL_UNORM_XX 和 CL_QCOM_UNORM_INT10 创建的图像。在 YUV 格式的图像中,矢量读取和写入图像有一些特殊规则:
- 对 U 或 V 值进行的 4x1 读取将返回与所选 Y 像素相对应的 U 或 V 值。
- 在以 Y00 为中心的 U 平面进行的 4x1 读取将返回 (U00, U00, U01, U01),这四个 U 值对应于四个 Y 值。
- Y00,Y01 共用U00,Y02,Y03共用U01
- 在 U 或 V 平面进行的 2x2 读取将返回四个不同的 U 或 V 值。例如,参考以下的 4x4 图像:
- 以某点为中心,进行 2x2 读取将返回 (U10, U11, U01, U00)。
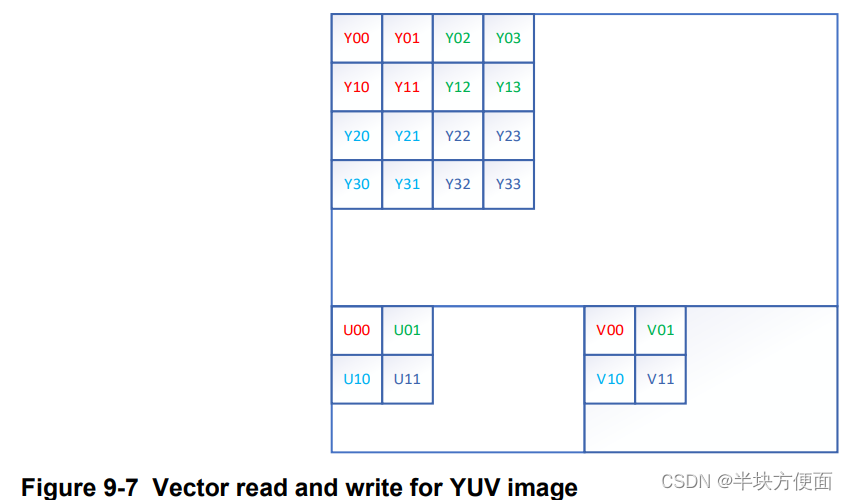
更多信息参考 OpenCL SDK 开发文档 cl_qcom_vector_image_ops.
- 以某点为中心,进行 2x2 读取将返回 (U10, U11, U01, U00)。
Note:
YUV 颜色编码采用的是 明亮度 和 色度 来指定像素的颜色。其中,Y 表示明亮度(Luminance、Luma),而 U 和 V 表示色度(Chrominance、Chroma)。而色度又定义了颜色的两个方面:色调和饱和度。
使用 YUV 颜色编码表示一幅图像,它应该下面这样的:
和 RGB 表示图像类似,每个像素点都包含 Y、U、V 分量。但是它的 Y 和 UV 分量是可以分离的,如果没有 UV 分量一样可以显示完整的图像,只不过是黑白的。
对于 YUV 图像来说,并不是每个像素点都需要包含了 Y、U、V 三个分量,根据不同的采样格式,可以每个 Y 分量都对应自己的 UV 分量,也可以几个 Y 分量共用 UV 分量。
9.3.6 压缩图片
一个名为cl_qcom_compressed_image的扩展在Adreno GPU中得到支持,该扩展允许以Qualcomm设计的专有压缩格式读取和写入图像。除了节省内存带宽外,它还可能降低功耗和能耗,这对许多相机和视频用例特别有用,因为它们通常对数据需求很高。要使用该扩展,主机必须使用表9-4中的函数查询格式的可用性,以及通道和数据类型的支持信息,因为它们在不同的Adreno GPU上可能会有所不同。使用压缩图像格式的方法与常规图像格式类似:
- 它支持两种滤波模式,CLK_FILTER_LINEAR和CLK_FILTER_NEAREST。
- 它支持多种不同的图像通道,例如CL_RGBA。
- 它支持数据类型,如CL_UNORM_INT8。
使用压缩格式的典型用例和工作流程是让GPU读取SOC中其他模块(例如相机模块)生成的压缩数据。这通常与零拷贝技术相结合(即使用ION内存或Android本地缓冲区技术)。表9-4显示了这两种方法的步骤,它们非常相似,只是一些标志和枚举类型有所不同。
Table 9-4 Steps to use compressed image
ION
// 查询支持的格式
errcode = clGetSupportedImageFormats(context, CL_MEM_READ_ONLY | CL_MEM_COMPRESSED_IMAGE_QCOM, CL_MEM_OBJECT_IMAGE2D,
num_format_list_entries, format_list, &num_reported_image_formats);// 创建一个缓冲区来保存图像数据
cl_mem_ion_host_ptrcompressed_ionmem = {0}; // Initialize ION buffer attributes
compressed_ionmem.ext_host_ptr.allocation_type = CL_MEM_ION_HOST_PTR_QCOM;
compressed_ionmem.ext_host_ptr.host_cache_policy = CL_MEM_HOST_UNCACHED_QCOM;
compressed_ionmem.ion_filedesc = ion_info_fd.file_descriptor; // file descriptor for ION
compressed_ionmem.ion_hostptr = ion_info.host_virtual_address; // hostptr returned by ION// 创建一个可供应用程序使用的图像对象
cl_image_format image_format = {0};
cl_image_desc image_desc = {0};
cl_int errcode = 0;
// Set image format
image_format->image_channel_order = CL_QCOM_COMPRESSED_RGBA;
image_format- >image_channel_data_type = CL_UNORM_INT8;
// Set image parameters
image_desc->image_width = 128;
image_desc->image_height = 256;
image_desc->image_row_pitch = 0;
// must be 0 for compressed images
image_desc->image_slice_pitch = 0;
// Create a compressed image
compressed_rbga_image = clCreateImage (context, CL_MEM_EXT_HOST_PTR_QCOM CL_MEM_READ_ONLY, image_format, image_desc, (void*)compressed_ionmem, &errcode);
Android Native buffer
// 查询支持的格式
errcode = clGetSupportedImageFormats(context, CL_MEM_READ_ONLY | CL_MEM_COMPRESSED_IMAGE_QCOM, CL_MEM_OBJECT_IMAGE2D,
num_format_list_entries, format_list, &num_reported_image_formats);// 创建一个缓冲区来保存图像数据
cl_mem_android_native_buffer_host_ptr compressed_ANBmem = {0};
GraphicBuffer *gb; // previously created the hostptr to a native buffer and gb is an Android GraphicBuffer
compressed_ANBmem.ext_host_ptr.allocation_type = CL_MEM_ANDROID_NATIVE_BUFFER_HOST_PTR_QCOM;
compressed_ANBmem.ext_host_ptr.host_cache_policy = CL_MEM_HOST_WRITEBACK_QCOM;
compressed_ANBmem.anb_ptr = gb->getNativeBuffer();// 创建一个可供应用程序使用的图像对象
cl_image_format image_format = {0};
cl_image_desc image_desc = {0};
cl_int errcode = 0;
// Set image format
image_format->image_channel_order = CL_QCOM_COMPRESSED_RGBA;
image_format->image_channel_data_type = CL_UNORM_INT8;
// Set image parameters
image_desc->image_width = 128;
image_desc->image_height = 256;
image_desc->image_row_pitch = 0;
// always 0 for compressed
images image_desc->image_slice_pitch = 0;
// Create a compressed image
images compressed_rbga_image = clCreateImage(context, CL_MEM_EXT_HOST_PTR_QCOM | CL_MEM_READ_ONLY, image_format,
image_desc, (void*)compressed_ANBmem &errcode);
Adreno GPU上的OpenCL可以解码和读取压缩图像,并将其写入另一个具有相同压缩格式的图像。然而,压缩图像只能在内核内部进行读取或写入。不支持压缩图像的原地读/写功能,即CL_MEM_KERNEL_READ_AND_WRITE。
9.4 机器学习
9.4.1 SNPE/QNN(神经网络处理引擎)
Qualcomm神经处理软件开发工具包(SNPE/QNN)是边缘计算中机器学习工作负载的成熟解决方案。这个专有的、闭源的软件开发工具包取得了巨大的成功。它为客户提供了一套庞大的工具和软件开发工具包,通过使用Snapdragon上的所有可用计算设备,包括CPU、GPU和DSP,来加速神经网络。由于其高商业质量,制造商和开发人员已经采用了神经处理SDK。
一些高级开发人员仍然更喜欢专门在Adreno GPU上运行其机器学习工作负载。他们可以利用最近发布的高通Adreno OpenCL ML SDK,以实现在Adreno GPU上的定制、灵活性和加速。(自夸哈,不用读)
9.4.2 OpenCL ML SDK for Adreno GPU
开发人员可以通过cl_qcom_ml_ops扩展加速许多常见的机器学习操作。高通优化的操作可以提供显著的性能优势。它们支持推理和训练。请参考Adreno OpenCL MK SDK获取文档和示例。有关更多详细信息,请查看博客:《在Adreno GPU上使用OpenCL进行机器学习加速 - 高通开发者网络》。以下是SDK的一些要素:
- 一个名为cl_qcom_ml_ops的OpenCL扩展是该SDK的核心部分。该扩展在一些Adreno A6x GPU和所有A7x GPU中可用,提供了一套全面的API函数,以启用许多关键的机器学习操作。
- 这些函数包含了经过高度优化的内核,充分利用了Adreno GPU的硬件能力。
- 除了API函数之外,该扩展还定义了必要的数据结构、tokens, tensor objects 和内存管理机制,以便更容易地使用API函数。
- 该SDK提供文档和示例,以帮助开发人员充分利用这一功能。它还包含一个模型转换工具,用于将使用标准ML网络(如TensorFlow和PyTorch)的模型文件转换为API可以直接使用的ML扩展中的模型。
- 利用该SDK,开发人员可以轻松地将其ML应用程序移植和调整为使用ML Ops,而无需编写自己的OpenCL内核,这可能会带来性能提升。请参考SDK文档和代码示例以获取更多详细信息。
9.4.3 Tensor virtual machine (TVM) and the cl_qcom_ml_ops extension
最近,TVM,一个为深度学习工作负载提供支持的知名且非常活跃的开源编译器框架,已经添加了对Adreno的cl_qcom_ml_ops扩展的支持。这降低了开发人员使用该SDK的门槛,并有助于在Adreno GPU上快速生成和原型化运行的ML网络。
9.4.3.1 TVM
TVM能够自动生成针对给定的机器学习操作的多个OpenCL内核实现。它可以使用基于机器学习的调整方法,从庞大的搜索空间中找到性能最佳的OpenCL内核。TVM可以在机器学习模型上进行操作级别和图级别的优化,生成适用于各种硬件模块的高性能OpenCL内核实现。而且,由于TVM是开源的,它得到了一个庞大而活跃的社区的支持,该社区的成员来自工业界和学术界。
9.4.3.2 How TVM works with the cl_qcom_ml_ops extension
TVM社区引入了BYOC(Bring Your Own Code)作为一种将供应商加速库(如Adreno)中的高性能内核嵌入到TVM生成的主要代码中的方法。因此,我们正在利用BYOC来集成cl_qcom_ml_ops扩展到TVM,以实现端到端的解决方案。
尽管cl_qcom_ml_ops扩展功能强大,但其专有的API带有一定的学习曲线。与单独使用SDK相比,TVM和cl_qcom_ml_ops的集成更为简单。通过这种集成,开发人员无需理解规范、头文件或调用哪些API,就可以在第一天开始使用OpenCL ML,而无需学习API定义。
9.4.3.3 How to use TVM with the cl_qcom_ml_ops extension
Adreno OpenCL ML与TVM的集成已经开源并上游。这种集成使开发人员能够轻松导入来自TVM支持的框架(如TensorFlow、PyTorch、Keras、CoreML、MXnet和ONNX)的深度学习模型。它尽可能地利用了TVM的图级优化和Adreno OpenCL ML库内核。对于cl_qcom_ml_ops扩展不支持的任何内核或操作符,BYOC提供了一个回退选项,可以使用TVM支持的任何后端。
请查看带有OpenCL ML SDK的TVM存储库和位于高通开发者网络的博客:“ 使用TVM和Adreno GPU上的Adreno OpenCL ML API加速您的机器学习网络” 以获取更多详细信息。
9.4.4 Other features for ML
9.4.4.1 Support of bfloat16 data
bfloat16(brain floating point)浮点格式使用16位来表示32位浮点数的近似动态范围,通过保留八个指数位。然而,它仅支持8位精度,而不是24位的FP32格式。bfloat16可用于减少数据存储需求,同时加速一些机器学习算法。有关更多信息,请参考Adreno OpenCL SDK。
9.5 Other enhancements
9.5.1 8-bit 操作
cl_qcom_dot_product8 扩展引入了一组新的OpenCL内建函数,用于计算具有一对四个8位分量的点积,然后将点积结果与32位累加器饱和相加。对于此功能,必须启用以下编译器 #pragma:
#pragma OPNCL EXTENSION cl_qcom_dot_product8 : <behavior>
定义了两个函数,一个用于无符号8位整数,另一个用于有符号整数。
| Function | 描述 | 例子 |
|---|---|---|
int qcom_udot8_acc(uint p0, uint p1,int acc); | 假设p0和p1分别可以解释为四个无符号8位分量,而acc被解释为有符号32位累加器。qcom_udot8_acc对这些分量的乘积求和,并将累加器加到结果中,得到一个带有有符号饱和的32位结果。 | 计算向量 (11, 22, 33, 44) 和 (55, 66, 77, 88) 的无符号点积,并使用累加器为 9, 示例1 |
int qcom_dot8_acc(uint p0, uint p1, int acc); | 假设 p0 和 p1 分别可以解释为四个有符号8位分量和四个无符号8位分量,并且 acc 被解释为有符号32位累加器。qcom_dot8_acc 对这些分量的乘积求和,并将累加器加到结果中,得到一个带有有符号饱和的32位结果。 | 计算向量 f(-11, 22, -33, 44) 和(55, 66, 77, 88) 的无符号点积,并使用累加器为 9 , 示例2 |
示例 1
uchar p0a = 11; uchar p0b = 22;
uchar p0c = 33; uchar p0d = 44;
uchar p1a = 55; uchar p1b = 66;
uchar p1c = 77; uchar p1d = 88;
uint p0 = (p0a << 24) | (p0b << 16) | (p0c << 8) | p0d;
uint p1 = (p1a << 24) | (p1b << 16) | (p1c << 8) | p1d;
int acc = 9;
int result = qcom_udot8_acc(p0, p1, acc);
示例 2
uchar p0a = -11; uchar p0b = 22;
uchar p0c = -33; uchar p0d = 44;
uchar p1a = 55; uchar p1b = 66;
uchar p1c = 77; uchar p1d = 88;
uint p0 = (p0a << 24) | (p0b << 16) | (p0c << 8) | p0d;
uint p1 = (p1a << 24) | (p1b << 16) | (p1c << 8) | p1d;
int acc = 9;
int result = qcom_dot8_acc(p0, p1, acc);
Khronos 扩展 cl_khr_integer_dot_product 也提供了类似的功能。
9.5.2 cl_qcom_bitreverse
该扩展引入了一种加速无符号整数位反转的新的OpenCL内建函数。使用此内建函数的应用程序相对于使用其他方法反转位的应用程序可能会获得性能优势。对于此功能,必须启用 #pragma cl_qcom_bitreverse。
#pragma OPNCL EXTENSION cl_qcom_bitreverse : enable //disable
一旦启用,函数 qcom_bitreverse 就可以用于颠倒位的顺序。以下是一个示例:
uint input = 0x1248edbf;uint output = qcom_bitreverse (input); //output = 0xfdb71248
更多操作请阅读 OpenCL SDK 开发文档关于 cl_qcom_bitreverse 的描述
这篇关于Chart 9 Adreno GPU的 OpenCL 扩展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





