近一个月一直在Udacity学习数据分析课程,因此很久没有更新博客。我根据自己的学习安排,已经完成提交了项目一——对Stroop现象用数理统计方法进行假设检验并得出结论。这次来分析一下链家网公开的部分城市新楼盘数据(2017.07获取的数据),主要对城市楼盘数量、价格进行分析。
数据读取
为了操作方便,我从网上爬取的数据保存为csv格式,因此直接用pandas库的read_csv方法可以直接读取并赋值给DataFrame数据类型的变量。
data = pd.read_csv('C:/Users/Nekyo/HJQ/document/pyfile/lianjiaData1.csv') 数据预处理
将爬取的数据我用excel打开,主要信息如下图。由于数据源的原因,获取的数据比较乱,处理起来需要兼顾很多东西。例如:建筑面积这一栏,有的是空数据,有的是固定一个值,有的是一个范围,有的城市是按照建筑面积算,有的城市是按照套内面积算;还有如均价一栏,大多是按照“元/平”来算,部分也按照“万/套”来算,另外也有空数据;地址这一栏数据比较统一,“-”符号将地址分割为城市下面的区县和楼盘具体的地址;居室这一栏由于数据太散乱意义不大,没有使用。因此我主要给出各城市,以及城市下面的区县新楼盘面积和均价的分析情况。
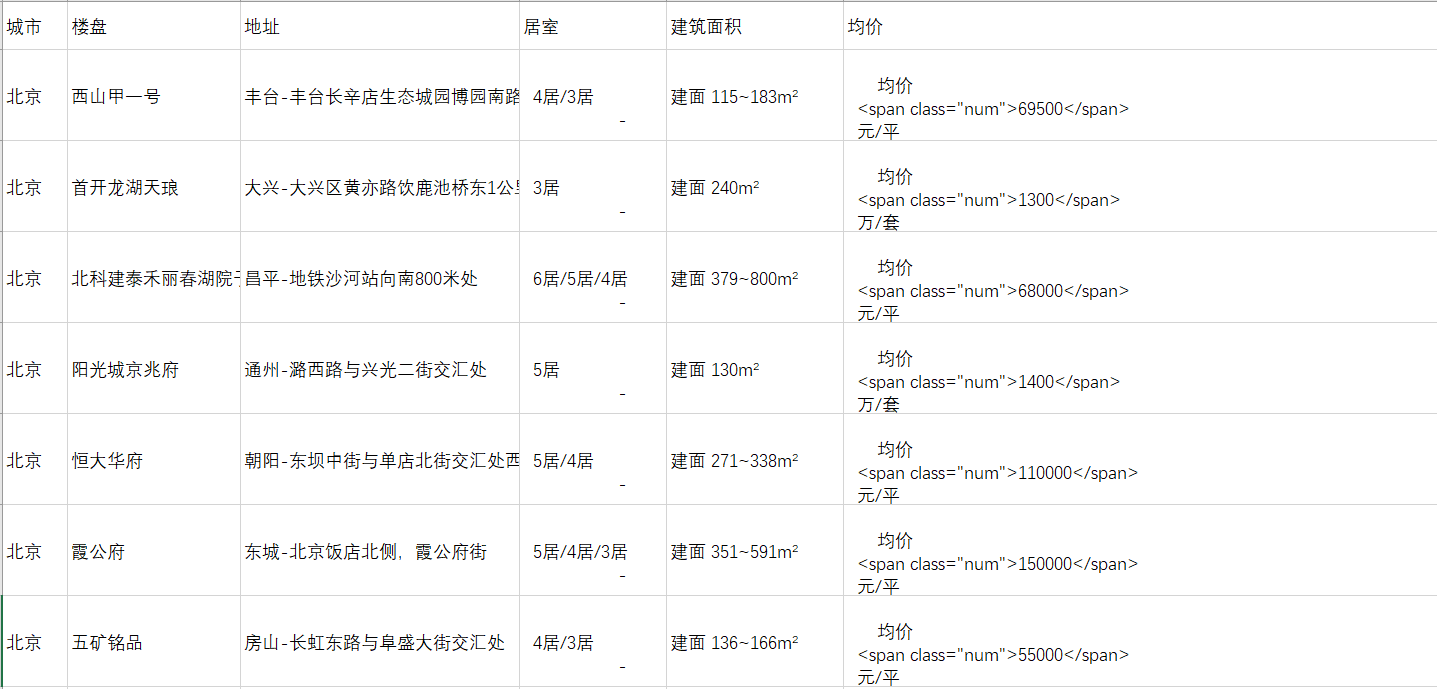
在分析过程中,为了统一我都把建筑面积按照套内面积来算;将特殊数据,如空值、价格待定等数据去除。
data = data.drop_duplicates(keep='first') #去除重复数据,保留重复数据的第一行数据 data = data.reset_index()[['城市','地址','居室','建筑面积','均价']] #由于删去了部分数据,重置索引 data['居室'] = data['居室'].str.split('-',1) data['建筑面积'] = data['建筑面积'].str.replace('建面','').str.replace('套内','').str.strip().fillna('0') #全部统一为同一单位的面积 data['均价'] = data['均价'].str.strip().str.replace('价格待定','').str.strip().fillna('0') #去除均价垃圾数据
数据处理
经过以上步骤,我们将数据稍微规整了一下,但是数据格式仍然不统一,因此需要细化处理:1、地址一栏只保留“-”符号前面的区县;2、建筑面积一栏,去除空数据后,如果是一个面积范围则取平均值;3、均价一栏由于是两种维度的数据,因此通过正则匹配方式查找并只筛选出单位为“元/平”的数据。
addr=[] area=[] roomnum=[] price=[] pattern0=re.compile('万/套') pattern=re.compile('<span class="num">(.*?)</span>') #通过正则匹配均价的数值,需引入re库 llen = len(data) for i in range(llen):addpos = data['地址'][i].find('-')addr.append(data['地址'][i][:addpos])areapos1 = data['建筑面积'][i].find('~') #"~"所在的位置,如果找不到则返回-1 areapos2 = data['建筑面积'][i].find('m') #"m"所在的位置,如果找不到则返回-1 if areapos2!=-1:if areapos1!=-1:area1=data['建筑面积'][i][:areapos1]area2=data['建筑面积'][i][areapos1+1:areapos2]areaavg = (float(area1)+float(area2))/2area.append(areaavg)else:area1=data['建筑面积'][i][:areapos2]areaavg=float(area1)area.append(areaavg)else:area.append(0.0) roomnum.append(data['居室'][i][0].strip())prices0 = re.findall(pattern0, data['均价'][i])prices = re.findall(pattern,data['均价'][i])if prices:if prices0:price.append(0.0) # 因为有部分是按照 万/套来计算房价的,因此之后会清理掉 else:price.append(float(prices[0]))else:price.append(0.0)
将处理后的数据和原数据框拼接,这样就得到了比较统一规整的数据。
data['区县']=Series(addr)
data['房屋面积']=Series(area)
data['房间数']=Series(roomnum)
data['房价']=Series(price)
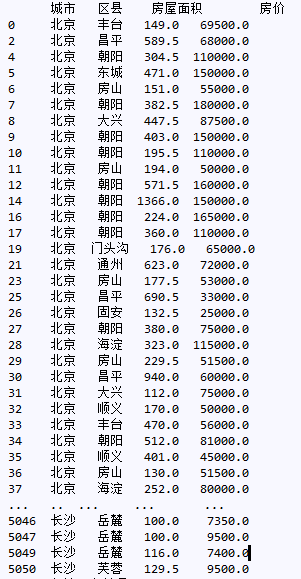
newdata = data[data['房价']>0][['城市','区县','房屋面积','房价']]
newdata = newdata[newdata['房屋面积']>0][['城市','区县','房屋面积','房价']] 结果如下
数据分析过程
先来看看简单的统计描述,只截取了北京大连两个城市的数据供参考。
newdata.groupby('城市').describe() 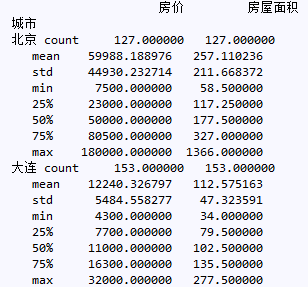
各城市的新开楼盘信息(平均值),用条形图来展示
newdata.groupby('城市')[['房屋面积','房价']].mean() 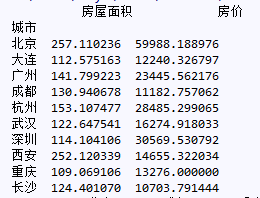
data1=newdata.groupby('城市')[['房屋面积','房价']].mean() mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"] mpl.rcParams['axes.unicode_minus'] = False fig = plt.figure(figsize=(10,5)) # 设置绘图区域大小及子图 ax1 = fig.add_subplot(121) ax1.set_xlabel('城市') ax1.set_ylabel('房屋面积(㎡)') ax1.set_title("城市新楼盘平均面积比较") data1['房屋面积'].plot(kind='bar') ax2 = fig.add_subplot(122) ax2.set_xlabel('城市') ax2.set_ylabel('房价(元/平)') ax2.set_title("城市新楼盘平均房价比较") data1['房价'].plot(kind='bar') plt.rcParams['font.sans-serif'] = ['SimHei'] # matplotlib画图坐标轴中文字体设置 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.show()
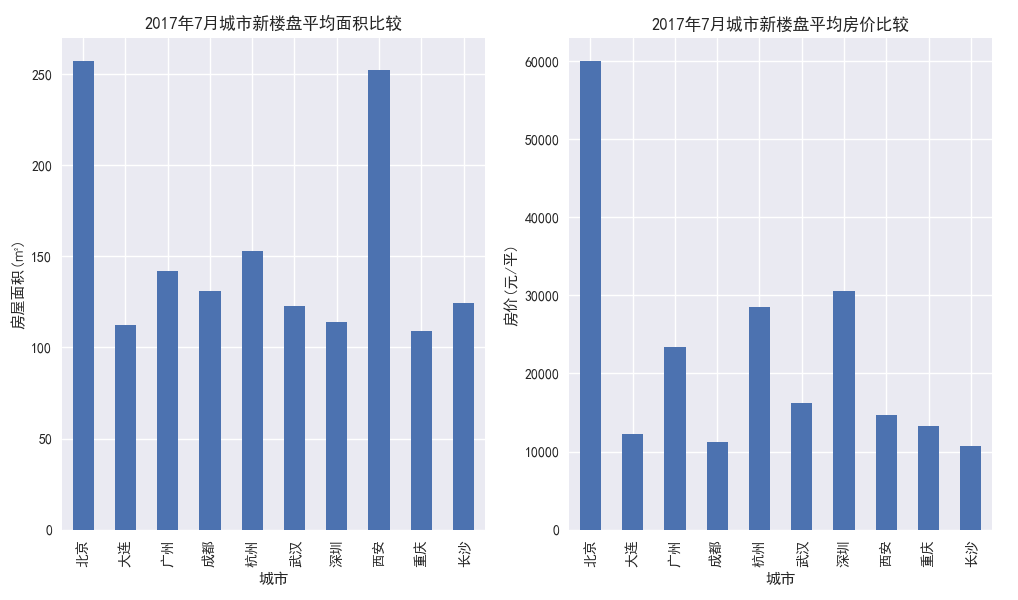
从房价均价图可以看出,各城市的房价水平会比真实情况略高,这可能是楼盘信息挂在网络平台导致的虚高,但是各城市的分布对比是能够和现实情况对上的。
下面再从每个城市下辖的区县维度展示云图效果,需要安装使用wordcloud库。
toawnavgarea={} #按区县楼盘面积 toawnavgprice={} #按区县楼盘均价 toawncounts={} #按区县楼盘数量toawn_avg = newdata.groupby('区县').apply(lambda x:x.mean()).reset_index() # 使用匿名函数计算平均值 toawn_counts = newdata.groupby('区县')['城市'].apply(lambda x:x.count()).reset_index() for i in range(len(toawn_avg)):toawnavgarea[toawn_avg.ix[i]['区县'].decode('utf-8')] = float(toawn_avg.ix[i]['房屋面积'])toawnavgprice[toawn_avg.ix[i]['区县'].decode('utf-8')] = float(toawn_avg.ix[i]['房价']) for j in range(len(toawn_counts)):toawncounts[toawn_counts.ix[j]['区县'].decode('utf-8')] = float(toawn_counts.ix[j]['城市']) wordcloud=WordCloud(font_path='C:/Users/Nekyo/tools/SOFTWARE/Anaconda2/Library/lib/fonts/songti.ttf', width=1000,height=600,background_color='white') # 云图使用的汉字字体,自带的字体库没有需要下载 f=plt.figure(figsize=(10,5)) ax1 = f.add_subplot(121) wordcloud.fit_words(toawncounts) axs1=plt.imshow(wordcloud) ax1.set_title("2017年7月区县新楼盘数量云图") plt.axis('off') # 不显示坐标轴 ax2 = f.add_subplot(122) wordcloud.fit_words(toawnavgprice) axs2=plt.imshow(wordcloud) ax2.set_title("2017年7月区县新楼盘均价云图") plt.axis('off') plt.show()

可以看到,成都高新区、大连甘井子区、广州顺德等地新开楼盘数量居前列;平均房价较高的几个地区:东城、西城、朝阳、海淀等,都在北京!!再仔细看一下我们才会看到位于深圳的福田、南山和罗湖区房价也紧随其后,由此我们有理由感慨:北京的房价是真高啊!!深圳也不差!
最后将数据大幅度调整一下,把每个城市的房价数据拿出来构造一个新的DataFrame,由于每个城市数据量不一样,因此数据量较少的城市在构造过程中会产生空值(NaN表示),不过对分析过程无影响。
newdata_bj = newdata[['房价','城市']][newdata['城市']=='北京'].reset_index() newdata_cq = newdata[['房价','城市']][newdata['城市']=='重庆'].reset_index() newdata_cd = newdata[['房价','城市']][newdata['城市']=='成都'].reset_index() newdata_sh = newdata[['房价','城市']][newdata['城市']=='上海'].reset_index() newdata_hz = newdata[['房价','城市']][newdata['城市']=='杭州'].reset_index() newdata_gz = newdata[['房价','城市']][newdata['城市']=='广州'].reset_index() newdata_sz = newdata[['房价','城市']][newdata['城市']=='深圳'].reset_index() newdata_dl = newdata[['房价','城市']][newdata['城市']=='大连'].reset_index() newdata_wh = newdata[['房价','城市']][newdata['城市']=='武汉'].reset_index() newdata_xa = newdata[['房价','城市']][newdata['城市']=='西安'].reset_index() newdata_cs = newdata[['房价','城市']][newdata['城市']=='长沙'].reset_index() data_bycity = pd.concat([newdata_bj,newdata_cd,newdata_cq,newdata_hz,newdata_gz,newdata_sz,newdata_dl,newdata_wh,newdata_xa,newdata_cs],axis=1) # concat拼接函数 data_bycity = data_bycity.drop(['index','城市'],axis=1) # 去掉索引 data_bycity.columns=['北京','成都','重庆','杭州','广州','深圳','大连','武汉','西安','长沙'] # 设置列名
新构造的数据集
用箱线图对比展示各城市的房价
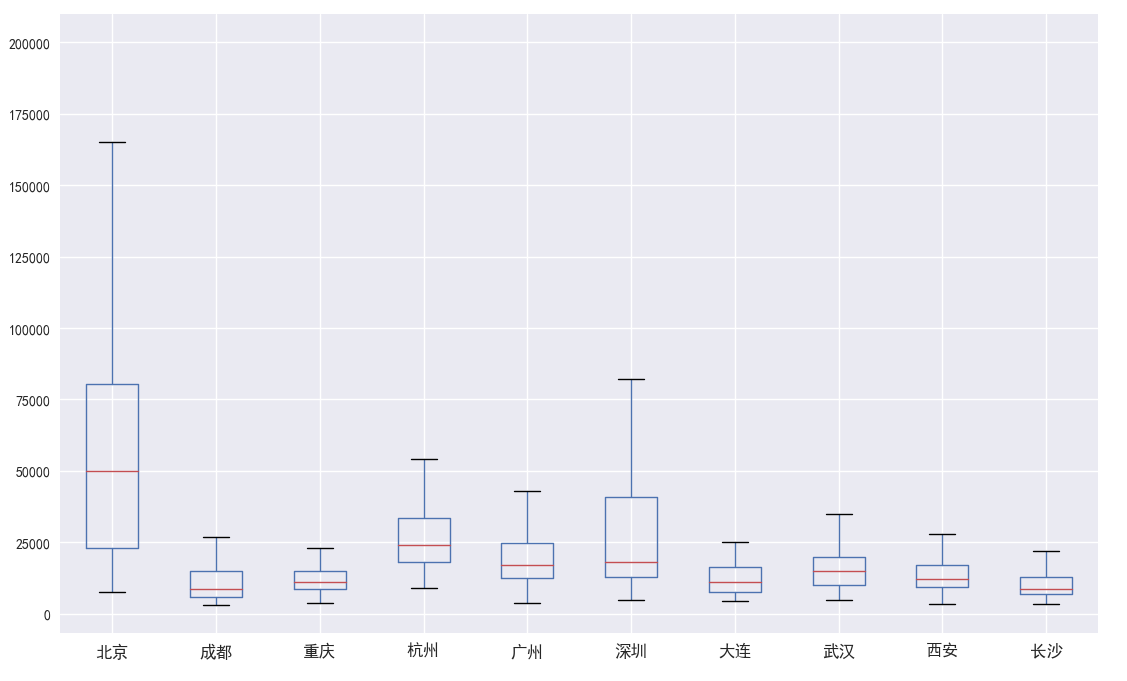
很明显,无论是从中位数还是最大值来看,北京的房价一骑绝尘,深圳紧随其后;再根据四分位距的对比情况,北京深圳也令其它城市难以望其项背,两个城市的房价分布比较分散,会大概率出现某一楼盘开出特别高的房价,也会大概率出现某一楼盘开出相对城市均价来说比较低的房价。
再找一个城市分析其下辖区域的情况,以成都市为例
datacd=newdata[newdata['城市']=='成都'] datacd=datacd.groupby('区县')[['房屋面积','房价']].mean() fig = plt.figure(figsize=(10,5)) # 设置绘图区域大小及子图 ax1 = fig.add_subplot(121) ax1.set_xlabel('成都市各区县') ax1.set_ylabel('房屋面积(㎡)') ax1.set_title("2017年7月成都市各区县新楼盘平均面积比较") datacd['房屋面积'].plot(kind='bar') ax2 = fig.add_subplot(122) ax2.set_xlabel('城市') ax2.set_ylabel('房价(元/平)') ax2.set_title("2017年7月成都市各区县新楼盘平均房价比较") datacd['房价'].plot(kind='bar') plt.show()
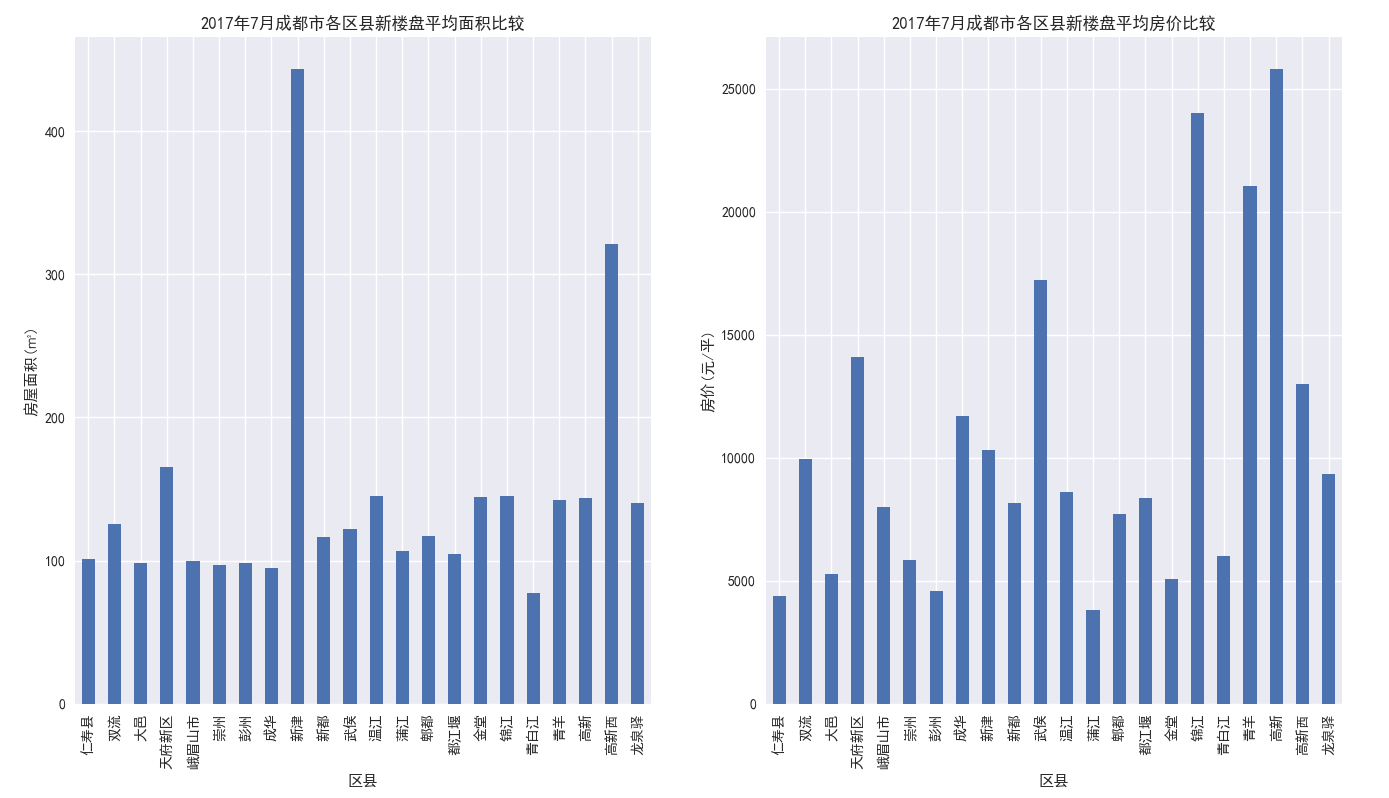
可以看到,新津、高新西区、天府三个区域新建楼盘面积居前列;房价比较高的区域都在诸如高新、青羊、锦江这样的热门市区,而且均价居然都达到了2w,而像蒲江、仁寿、彭州这样离市区稍远的县连5k都不到,跟省内一个地级市房价差不多,放在全国来看,甚至不如一个发达地区的县城的房价。
总结
由于数据源的因素,本次分析可能会与现实情况略有出入,但是大致方向,大致比较分布是没有问题的,也通过这些数据和图形展示对自己感兴趣的城市房价有了一个直观印象。由于是第一次通过博文展示,因此为了加深自己的理解,尽可能的描述了很多细节,显得比较啰嗦,之后的分析案例会尽量简洁,不会每个步骤每段代码都进行说明。





