本文主要是介绍Basal Glucose Control in Type 1 Diabetes using Deep Reinforcement Learning: An In Silico Validation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
\quad 一型糖尿病(T1D)患者需要定期输注外源性胰岛素,以维持其血液中葡萄糖浓度在治疗上足够的范围内。尽管人工胰腺和持续的葡萄糖监测已被证明对实现闭环控制是有效的,但由于葡萄糖动态的高度复杂性和技术的局限性,重大的挑战仍然存在。在这项工作中,我们为单激素(胰岛素)和双激素(胰岛素和胰高血糖素)的输送提出了一个新的深度强化学习模型。特别是,通过双Q-学习与扩张的递归神经网络来开发脱药策略。为了设计和测试的目的,我们采用了FDA认可的UVA/Padova 1型模拟器。首先,我们进行了长期的泛化训练以获得一个群体模型。然后,这个模型被个性化了,有一个小型的受试者特定数据集。仿真结果显示,与标准的低血糖胰岛素悬液基础治疗相比,单激素和双激素给药策略能实现良好的血糖控制。具体来说,在成人队列中(10人),使用单激素控制时,目标范围[70, 180]mg/dL的百分比时间从77.6%提高到80.9%,而使用双激素控制时则提高到85.6%。在青少年队列中(n=10),单激素控制下,目标范围内的百分比时间从55.5%提高到65.9%,双激素控制下提高到78.8%。在所有情况下,都观察到低血糖的显著减少。这些结果表明,使用深度强化学习是一种可行的方法,用于T1D的闭环葡萄糖控制。
1 Introduction
\quad 糖尿病是一种影响全世界数百万人的慢性疾病。它的特点是血糖(BG)升高,从长远来看会导致心血管疾病、视网膜病变和肾病等并发症。它的全球流行率已达到流行病的比例,在过去20年里翻了一番[1]。糖尿病主要有两种类型,1型和2型。2型糖尿病的特点是身体不能有效地使用胰岛素,通常可以通过生活方式干预和口服药物治疗。然而,1型糖尿病(T1D)的特点是胰岛β细胞产生的胰岛素不足,因此需要使用外源性胰岛素。T1D的标准胰岛素替代疗法包括一剂快速作用的胰岛素,以补偿进食后快速增加的葡萄糖,以及通过注射慢作用的胰岛素来提供基础胰岛素,以保持空腹情况下葡萄糖水平在目标范围内。另外,基础胰岛素可以通过使用胰岛素泵和速效胰岛素连续输注来提供。虽然有一些软件工具,如胰岛素注射计算器,可以帮助T1D患者自我管理胰岛素,但它们仍然无法实现最佳的血糖控制[2]。因此,实现自动化系统来提供最佳的胰岛素剂量是过去几十年来血糖管理的长期挑战之一[3]。
\quad 最近,连续血糖监测(CGM)系统 在准确性和可靠性方面的改进使得闭环胰岛素输送系统的开发成为可能,该系统也被称为人工胰腺(AP),可以自动控制T1D患者的血糖水平[4]。一个人工胰腺至少包括一个 CGM传感器 、一个 控制算法 和一个 胰岛素泵 。此外,一些AP系统可能还包括一个 胰高血糖素泵 来对抗胰岛素的作用[5],以及一个 活动监测器来量化体育锻炼 [6] 。葡萄糖测量值由CGM设备每5分钟采集一次,并发送给控制算法,该算法计算出相应的胰岛素剂量,旨在将葡萄糖水平保持在目标范围内,然后由输液设备输送。到目前为止,大多数在临床上被评估的现有AP方法都采用了控制工程的方法[7],还有一种采用了人工智能(模糊逻辑)[8]。特别是其中的两个,美敦力670G和Tandem Control-IQ 已经进入商业化阶段。然而,尽管这些系统已被证明可以改善血糖控制[9,10],但挑战依然存在,需要进一步努力以实现最佳治疗目标。
\quad 近年来,在大规模的可用医疗数据和计算能力快速发展的推动下,机器学习,特别是深度学习,已经越来越多地被用于许多过去无法实现的医疗应用中[11],特别是在诊断和医学成像方面[12, 13]。
\quad 在糖尿病领域,机器精益化的使用也引起了极大的关注[14]。尤其是神经网络(NN)在葡萄糖预测方面取得了成功[15](全连接神经网络),[16,17](卷积神经网络),[18-20](循环神经网络(RNN)),以及[21](基于生理学的网络)。值得注意的是,扩张的RNN(DRNN)在处理长期依赖关系和未来葡萄糖预测方面表现特别好[18, 20, 22]。最近,另一项在自动胰岛素输送领域受到关注的技术是 强化学习(RL) [23]。RL是一个机器学习框架,用于学习连续的决策任务。许多医疗问题,如药物输送,可以被看作是闭环的顺序行动选择问题,这正是RL所关注的[24]。不幸的是,深度RL在医疗领域的应用受到了一些实际问题的限制。与虚拟世界中成功的深度RL应用不同,如Atari视频游戏或棋盘游戏[24, 25],其中代理动态地与虚拟环境互动,在没有适当安全约束的情况下,对人类主体进行这种探索可能是危险的。另外,深度RL算法可以使用经验重放从现有的收集的数据中学习。这个过程被称为非政策性学习,在实际的RL算法中起着重要的作用。然而,收集所需的训练数据是昂贵和耗时的[26]。幸运的是,美国食品和药物管理局(FDA)认可的T1D模拟试验已经成功。
\quad 在本文中,我们, in silico, 探讨了使用深度RL对T1D的BG水平进行闭环控制的问题。本文的组织结构如下。第2节描述了所提出的用于葡萄糖控制的深度RL框架的结构和算法。第3节对所提方法的性能进行了评估。第4节将结果与现有工作进行了比较,并讨论了未来的工作。最后,我们在第5节中总结了这项工作。
2 Methodology
\quad 在本节中,我们从深度RL的角度阐述了基础血糖封闭控制的问题。然后,我们介绍了一个两步框架,该框架适应于迁移学习,在硅学中开发可能用于临床实践的单激素和双激素葡萄糖控制器。
\quad 特别是,一个深度Q-learning模型[24]被用来优化胰岛素和胰高血糖素的输送。胰岛素和胰高血糖素的输送被视为随机策略所采取的行动(a),血糖结果(如葡萄糖目标的百分比时间)被视为奖励(r),而生理变量被视为状态(s)。深度神经网络(DNN)被用作非线性函数近似器来估计行动值,也被称为深度Q网络(DQN)。与以前使用传统RL控制AP系统的方法不同,不需要关于葡萄糖-胰岛素-胰高血糖素代谢的先验知识。相反,一堆扩张的递归层被用来处理多维的时间序列数据。由于其扩大的感受野,它能够捕捉葡萄糖-胰岛素-胰高血糖素动态的复杂性,正如我们以前的研究[18,20]所示。附录中的7.1节说明了如何选择DRNN模型而不是其他神经网络结构。
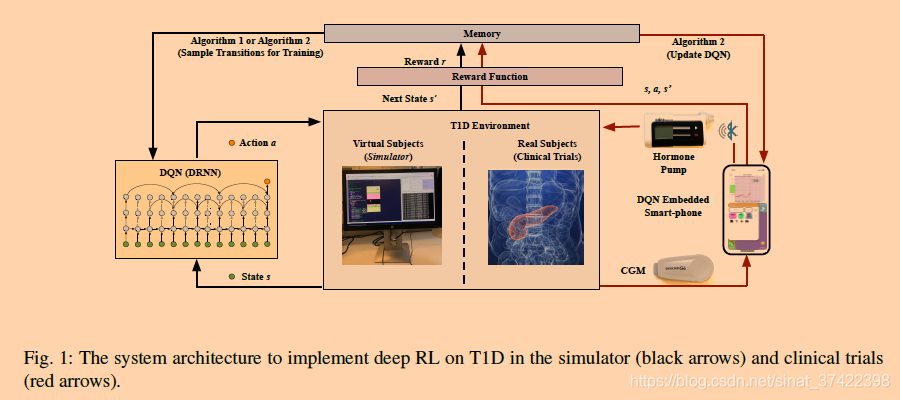
\quad 图1描述了用于开发DQN控制器的系统结构概述,该控制器在T1D的硅基环境中进行了评估,并可能用于临床试验。算法1和算法2对应于第2.2节中的两步学习框架。
2.1 Problem Formulation
\quad
这篇关于Basal Glucose Control in Type 1 Diabetes using Deep Reinforcement Learning: An In Silico Validation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








