本文主要是介绍Watch,Try, Learn: Meta-Learning from Demonstrations and Rewards读书笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
\quad Imitation learning 允许 agent 从 demonstrations 中学习 复杂的行为。然而学习一个复杂的视觉任务需要很大的 demonstrations。Meta-imitation learning 可以通过学习类似任务的经验,使 agent 从一个或几个 demonstrations 中学习新任务。在 t a s k a m b i g u i t y task\ ambiguity task ambiguity 或是 u n o b s e r v e d d y n a m i c s unobserved\ dynamics unobserved dynamics 时,仅依靠 demonstrations 无法获取足够的信息; agent必须在新任务上实践,才能学到一个好的 policy。
本文提出一种同时从 d e m o n s t r a t i o n s \boldsymbol{demonstrations} demonstrations 和 t r i a l − a n d − e r r o r e x p e r i e n c e w i t h s p a r s e r e w a r d f e e d b a c k \boldsymbol{trial-and-error\ experience\ with\ sparse\ reward\ feedback} trial−and−error experience with sparse reward feedback 中学习的方法。
与 meta-imitation 相比,该方法能够再没见过的 demonstrations 上表现更好
Imitation learning需要的样本较多,Meta-imitation learning 是一种解决小样本问题的有效方法。但有时候仅靠demonstration不能提供完整的信息,还需要agent与环境进行一定的交互来消除某些不确定性。本文提出一种同时利用demonstration和interaction的meta-learning方法,帮助agent更快地adapt到新的并且更加广泛的任务上。
1、INTRODUCTION


3、META-LEARNING FROM DEMONSTRATIONS AND REWARDS
\quad
3.1 PRELIMINARIES
\quad Meta-learning(也叫 learning to learn),旨在利用非常少的 data 学习新的 task。分为两步:
1)meta-train tasks:首先在任务集合 { T i } \{\mathcal{T}_i\} {Ti} meta-train
2)meta-test tasks:评价 the meta-learner 可以多快的学习 an unseen meta-test task T j \mathcal{T}_j Tj
\quad 通常,我们假设 meta-train and meta-test tasks 来自于一些 unknow task distribution p ( T ) p(\mathcal{T}) p(T),通过 meta-training ,一个 meta-learner 可以学习到 p ( T ) p(\mathcal{T}) p(T) 分布中任务的 some common structure,它可以用来更快地学习 a new meta-test task。
3.2 PROBLEM STATEMENT
\quad 我们的目标是 meta-train 一个 agent,通过两个 Phase 可以快速的学习一个新的 test task T j \mathcal{T}_j Tj:
\quad Phase I: agent 从 task demonstrations D j ∗ : = { d j , k } \mathcal{D}_j^*:=\{d_{j,k}\} Dj∗:={dj,k} ( k = 1 , . . . , K k=1,...,K k=1,...,K)中 观察、学习。然后 agent 就可以尝试 trial episodes τ j , l \tau_{j,l} τj,l ( l = 1 , . . . , L l=1,...,L l=1,...,L),从中 agent 可以得到 reward labels (就是,首先需要得到一个trial policy, 用于与环境交互得到新的数据)。
\quad Phase II: agent 利用 trial episodes 和 the original demos 来完成 T j \mathcal{T}_j Tj (就是,结合demonstration和交互数据学习一个retrial policy,作为解决新任务的policy)。
\quad 一个 demonstration 是 T 个在任务中成功的 state-action tuples d = { ( s t , a t ) } d=\{(s_t,a_t)\} d={(st,at)} 的轨迹。
\quad a trial episode 是 一个包含reward信息的轨迹 τ = { ( s t , a t , r i ( s t , a t ) ) } \tau = \{(s_t,a_t,r_i(s_t,a_t))\} τ={(st,at,ri(st,at))}。
3.3 LEARNING TO IMITATE AND TRY AGAIN
\quad 我们的目标是提出一个方法,可以从 demonstration 和 trial-and-error experience 中学习。我们希望在(1)中 meta-learn 一个 Phase I policy ,该 policy 适用于收集一个给定 demonstrations 的任务的 information。 在(2) 中 meta-learn 一个 Phase II policy 可以同时从 demonstrations 和 Phase I policy 中给出的 trials 中学习。
\quad Phase I policy 记为 π θ I ( a ∣ s , { d i , k } ) \pi_{\theta}^I(a|s,\{d_{i,k}\}) πθI(a∣s,{di,k}),其中 θ \theta θ 表示所有的可学习参数。 π I \pi^I πI 用来在获取交互数据之前,先推断 unknow task 是啥。
\quad Phase II policy 记为 π ϕ I I ( a ∣ s , { d i , k } , { τ i , l } ) \pi_{\phi}^{II}(a|s,\{d_{i,k}\},\{\tau_{i,l}\}) πϕII(a∣s,{di,k},{τi,l}), 包含参数 ϕ \phi ϕ。
\quad trial policy的训练 方法为模仿demonstration(文章中说这是Thompson sampling的策略),采用meta-imitation learning的方法,即优化下面的目标函数:
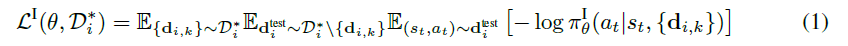
\quad 通过在 meta-train tasks 集合 { T i } \{\mathcal{T}_i\} {Ti} 上最小化公式(1)来 meta-train π θ I \pi_{\theta}^I πθI:
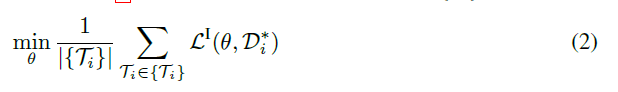
\quad 这个式子的直观意思是,优化 θ \theta θ ,使得给定一部分demonstration { d i , k } \{d_{i,k}\} {di,k} 后得到的 policy 能够模仿另一部分 demonstration D i t e s t \mathcal{D_i^{test}} Ditest。
\quad retrial policy 的训练 采用类似的训练方法,但此时比demonstration更多的是通过trial policy采样得到的样本数据 D i = { ( { d i , k } , { τ i , l } ) } \mathcal{D}_i=\{(\{d_{i,k}\},\{\tau_{i,l}\})\} Di={({di,k},{τi,l})},因此目标函数是:
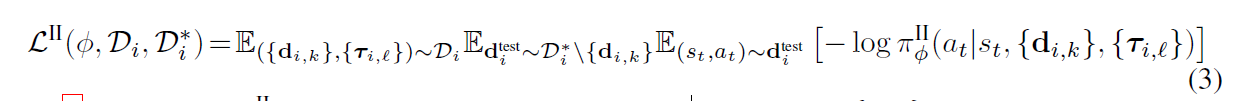
\quad 公式(3)鼓励 π I I \pi^{II} πII 根据 trial experience { τ i , l } \{\tau_{i,l}\} {τi,l} 进行更新,其中包含 reward information。如果一个 trail
有 high reward,那么 π I \pi^{I} πI 可能仅凭 demonstration 就成功推测出任务,并且 π I I \pi^{II} πII 可以 reinforce that high reward trial behavior。
\quad 同样最小化公式(3)来 meta-train π ϕ I I \pi_{\phi}^{II} πϕII 。
\quad 我们称我们的算法为 Watch-Try-Learn (WTL) ,并在附录 Alg.1 和 Alg.2 中详细描述了 meta-training 和 meta-test 的过程。我们在 Fig.2展示了 meta-training 的流程。

\quad Eqs.2和4的优化方式采用 随机梯度下降或其变种。我们迭代的采样任务 T i \mathcal{T}_i Ti 来完成 θ \theta θ 或 ϕ \phi ϕ 的梯度更新。
\quad 在meta-training阶段,首先采样tasks以及相应的demonstrations来训练trial policy,之后固定其参数 θ θ \thetaθ θθ,用trial policy 结合demonstrations生成部分trial trajectories,然后训练retrial policy。
\quad 在meta-test阶段,首先根据demonstrations得到trial policy并交互得到trial trajectories,然后利用retrial policy得到最终policy。
3.4 WATCH-TRY-LEARN IMPLEMENTATION
\quad WTL 和 Alg.1 规定了 the Phase I policy π θ I ( a ∣ s , { d i , k } ) \pi_{\theta}^I(a|s,\{d_{i,k}\}) πθI(a∣s,{di,k}) 的 一般化表示,需要以 task demonstration { d i , k } \{d_{i,k}\} {di,k} 为条件。 相似的, the Phase II policy π ϕ I I ( a ∣ s , { d i , k } , { τ i , l } ) \pi_{\phi}^{II}(a|s,\{d_{i,k}\},\{\tau_{i,l}\}) πϕII(a∣s,{di,k},{τi,l}) 需要以 { d i , k } \{d_{i,k}\} {di,k} 和 { τ i , l } \{\tau_{i,l}\} {τi,l} 为条件。这样,各种 mechanisms 才可以应用。
\quad 我们使用 神经网络 将 demonstration data 和 trial data 表示为 context vectors。
\quad Fig.3 展示了 只有一个 demonstration 和 trial 的情况下的 π ϕ I I \pi_{\phi}^{II} πϕII 结构。
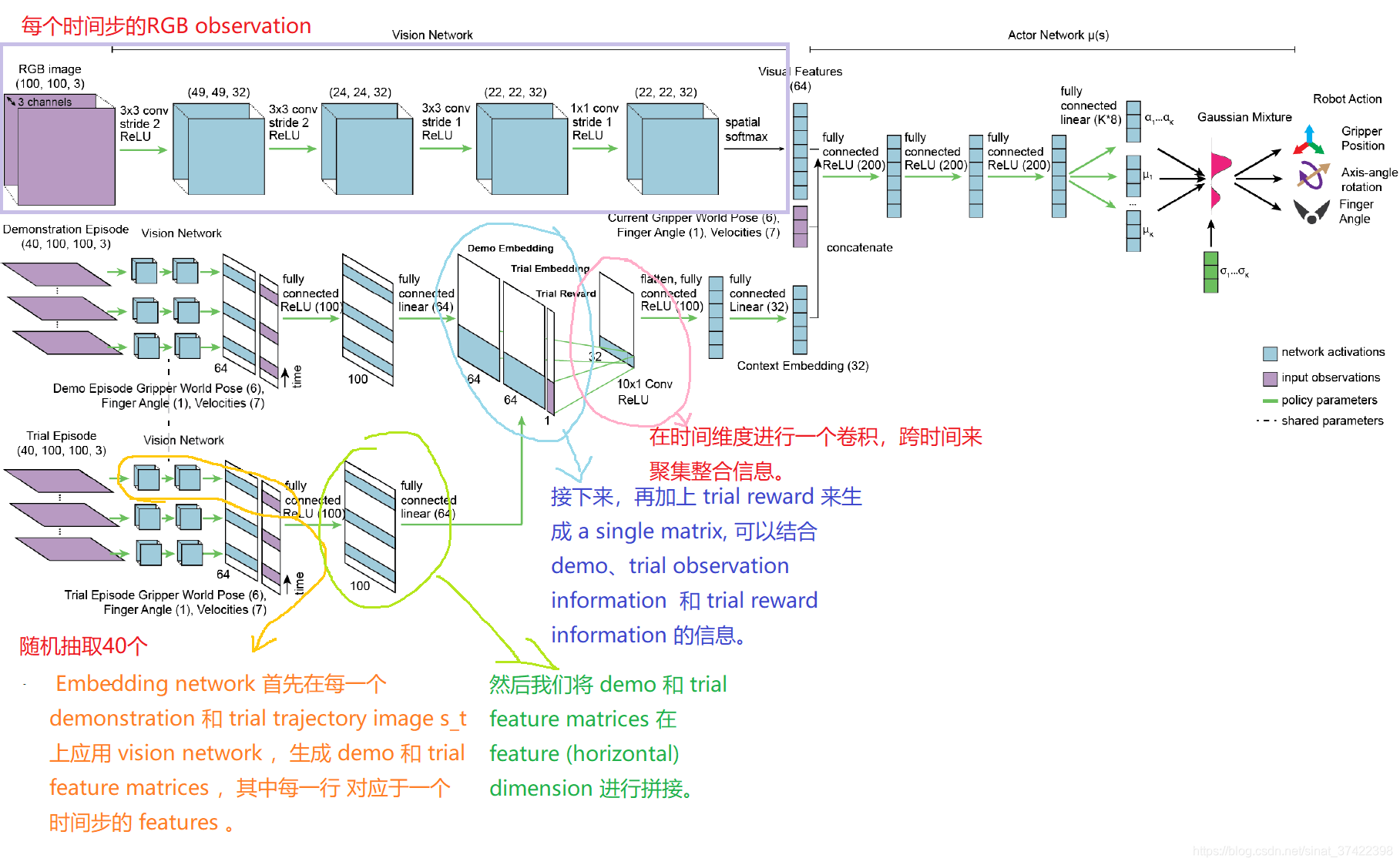
\quad 在 Embedding network 中,我们最后得到了一个 Context Embedding vector,包含了demos { d i , k } \{d_{i,k}\} {di,k} 和 trials
{ τ i , l } \{\tau_{i,l}\} {τi,l} 的信息。
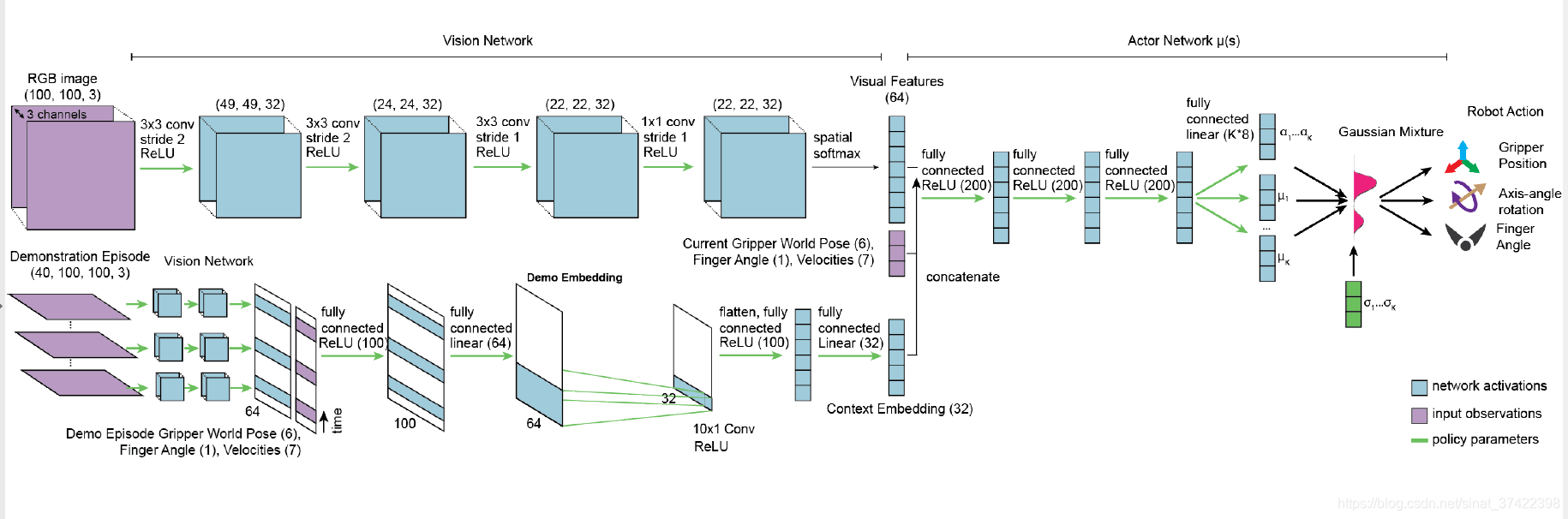
\quad Phase I policy π θ I \pi^I_\theta πθI 如上图所示,也生成了一个相似的 context embedding ,只不过只用了 demonstration data。
\quad 这个结构类似于之前的 contextual meta-learning works , 他们考虑了如何从单一源中进行meta-learn,但是没有考虑如何集成多个源的数据(包括 off-policy trial data)。
\quad π ϕ I I \pi^{II}_\phi πϕII 和 π θ I \pi^I_\theta πθI 的训练方式都是 end-to-end using backpropagation。注意,由于每个神经网络体系结构都是固定的,并且在任务之间共享,所以我们希望各个任务的输入状态维度是相同的,尽管 content (for example, the objects in the scene) 可能会有所不同。
4 EXPERIMENTS
\quad 我们的目标是实现 多任务的 few-shot learning,其中 agent 必须同时利用 demonstrations 和 trial-and-error 来有效的得到一个任务的 policy。相比与之前的类似的任务,他们有如下不足:
1)(Duan et al., 2017; Finn et al., 2017b) 只包含很少的任务,并且通过给定 a single demonstration 就可以很容易的消除这些任务之间的歧义。
2)(Duan et al., 2016; Finn et al., 2017a) 的任务之间很相似,meta-learner 几乎不需要 exploration 或者是 demonstration 就可以解决这些任务。
\quad 基于这些不足,我们设计了两个新问题,让 meta-learner 可以同时利用 exploration 和 demonstration:
1)a toy reaching problem 玩具抓取问题
2)a challenging multitask gripper control problem 多任务夹持控制问题
对比:
BC、MIL、WTL、BC+SAC
4.1 REACHING ENVIRONMENT EXPERIMENTS

\quad 在 reaching environment 中,经过一次论证和一次试验后,每种方法对元测试任务的平均回报。我们的Watch-Try-Learn (WTL)方法能够快速学习模仿演示器。每一行显示了平均超过5个独立的训练运行与相同的超参数,评估了50个随机抽样的元测试任务。阴影区域表示95%的置信区间。
\quad Fig.4 显示 WTL 可以很快的学会模仿专家,而不利用 trial information 的方法由于任务动态中的不确定性而 struggle。
5 DISCUSSION AND FUTURE WORK
1、该算法允许agent从 a single demonstration followed by trial experience and associated (possibly sparse) rewards 中快速的学习新的行为。
2、demonstration 使得agent 可以推断要执行的任务的类型;trials 可以提高 agent 的性能,通过 resolving ambiguities in new test time situations(通过在test阶段的试探,可以解决歧义问题,来提高agent的性能)。
这篇关于Watch,Try, Learn: Meta-Learning from Demonstrations and Rewards读书笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





