本文主要是介绍python中设置Dataframe数据的自定义字体颜色与xlwt库操作excel单元格得到自己想要的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 Dataframe数据设置字体
- 2 xlwt灵活操作excel
- xlwt 缺点
- 3 openyxl学习
- 总结
1 Dataframe数据设置字体
操作步骤如下
1 我们先看看自己想设置颜色的16进制是什么
2 然后选择其他颜色,进到下面的窗口
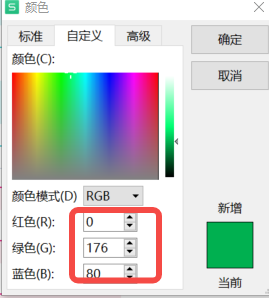
3 进入下面的链接进行转换
RGB颜色格式与16进制颜色转换的在线网站链接
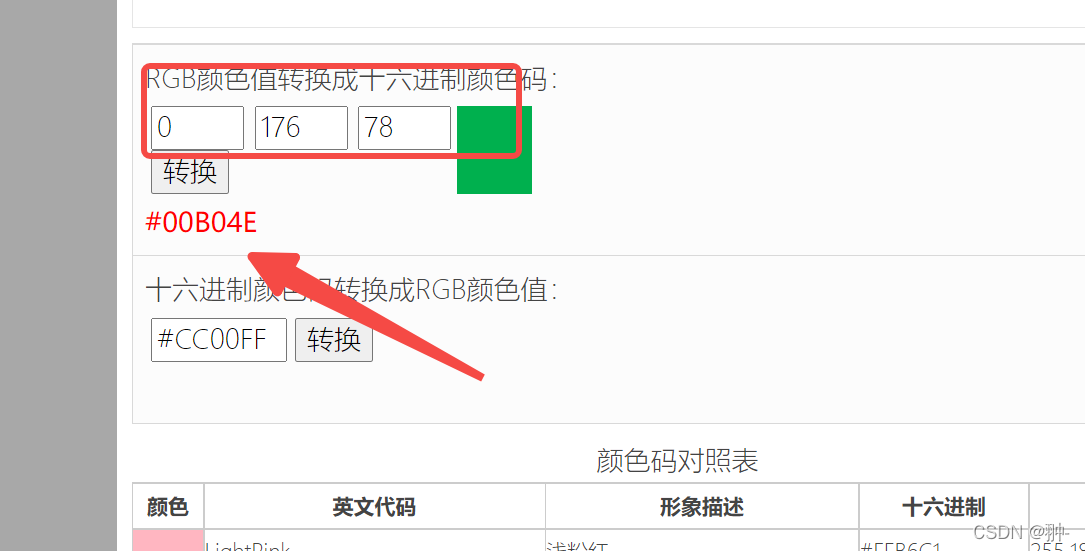
拿到十六进制的格式颜色了
4 接下来去python中进行设置
data_1.style.set_properties(**{'background-color': '#FFFFFF', 'color': '#00B04E'})

但是还是发现很多缺陷,像我想设置背景颜色是各行依据索引行设置,还有字体我想设置为微软雅黑
等等
了解到有StyleFrame,但是安装兼容包这些都太麻烦了,而且了解到好像也是对列行进行操作, 一定程度说是便利,也是缺陷(个人感觉) StyleFrame的一些使用
了解到有Openpyxl可以满足我的需求,我去研究一下下,
有需要会续更上下~
2 xlwt灵活操作excel
参考文章 :
python3-xlwt-Excel设置(字体大小、颜色、对齐方式、换行、合并单元格、边框、背景、下划线、斜体、加粗)
python的xlwt模块 菜鸟
注意事项,xlwt新版本只能操作xls,不能弄xlsx格式
示例:
import patterns as patterns
import xlwt
import time
i = 0
# 创建一个工作簿
book = xlwt.Workbook(encoding='utf-8')
# 创建一个sheet对象,第二个参数是指单元格是否允许重设置,默认为False
sheet = book.add_sheet('sheet1', cell_overwrite_ok=True)
# 初始化样式
style = xlwt.XFStyle()
# 为样式创建字体
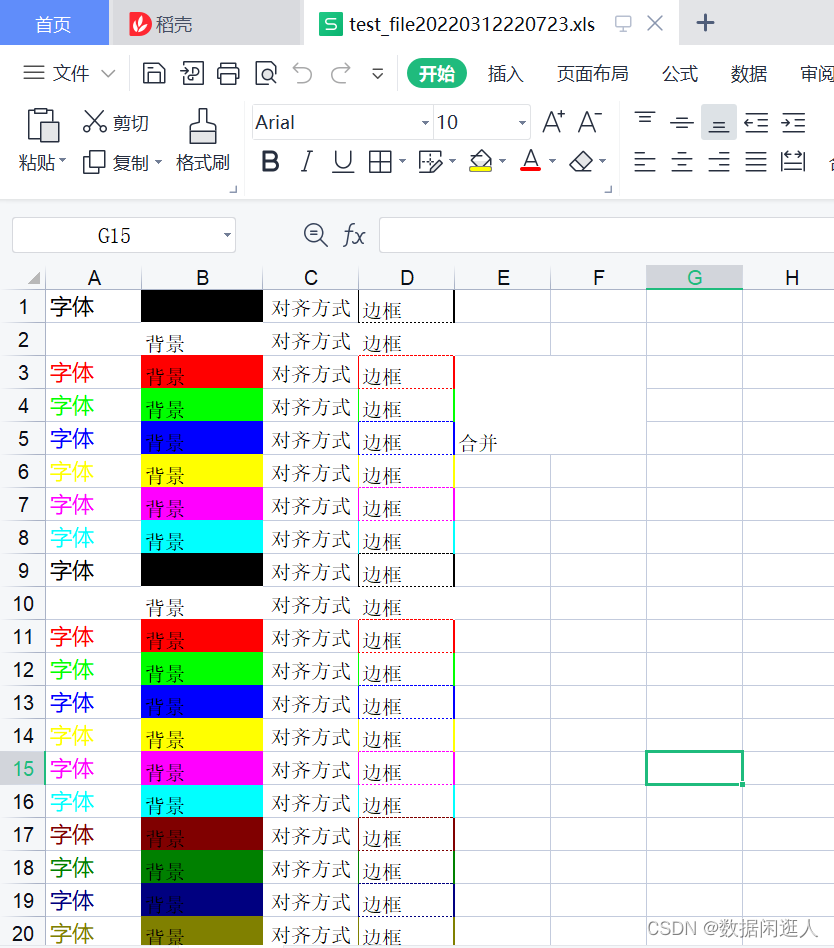
while i < 64:font = xlwt.Font()# 字体类型font.name = '微软雅黑'# 字体颜色font.colour_index = i# 字体大小,11为字号,20为衡量单位font.height = 20*11# 黑体font.bold = False # 下划线font.underline = False # 斜体字 font.italic = False# 设定样式style.font = font# 设置单元格对齐方式alignment = xlwt.Alignment()# 0x01(左端对齐)、0x02(水平方向上居中对齐)、0x03(右端对齐)alignment.horz = 0x02# 0x00(上端对齐)、 0x01(垂直方向上居中对齐)、0x02(底端对齐)alignment.vert = 0x01# 设置自动换行 alignment.wrap = 1 # 设置边框 borders = xlwt.Borders()# 细实线:1,小粗实线:2,细虚线:3,中细虚线:4,大粗实线:5,双线:6,细点虚线:7# 大粗虚线:8,细点划线:9,粗点划线:10,细双点划线:11,粗双点划线:12,斜点划线:13borders.left = 1borders.right = 2 borders.top = 3borders.bottom = 4borders.left_colour = i borders.right_colour = i borders.top_colour = i borders.bottom_colour = i # 设置列宽,一个中文等于两个英文等于两个字符,11为字符数,256为衡量单位sheet.col(1).width = 11*256# 设置背景颜色 pattern = xlwt.Pattern()# 设置背景颜色的模式pattern.pattern = xlwt.Pattern.SOLID_PATTERN # 背景颜色pattern.pattern_fore_colour = i # 初始化样式style0 = xlwt.XFStyle()style0.font = fontstyle1 = xlwt.XFStyle()style1.pattern = patternstyle2 = xlwt.XFStyle()style2.alignment = alignmentstyle3 = xlwt.XFStyle()style3.borders = borders# 第一个参数:行,第二个参数:列,第三个参数:内容,第四个参数是格式sheet.write(i,0,u'字体',style0)sheet.write(i,1,u'背景',style1)sheet.write(i,2,u'对齐方式',style2)sheet.write(i,3,u'边框',style3)# 合并单元格,合并第2行到第4行的第4列到第5列sheet.write_merge(2,4,4,5,u'合并')i = i + 1
效果:
xlwt 缺点
我查了很多相关资料,xlwt有个比较致命的缺点是无自定义单元格颜色,像上面的话,字体与填充颜色只有64种,这样对应的颜色都是一些RGB,(255,255,255),(255,255,0)这样,无法自我定义颜色
3 openyxl学习
这个openyxl可以解决xlwt无法自定义颜色的问题!!!
import openpyxl
from openpyxl.styles import Alignment
from openpyxl.styles import Font # 导入字体模块
from openpyxl.styles import PatternFill # 导入填充模块wk = openpyxl.load_workbook('./output/test02.xlsx') # 加载已经存在的excelsheet1 = wk['Sheet1']
Color = ['ffc7ce', '00B04E'] #红
font = Font(u'微软雅黑', size=11, bold=False, italic=False, strike=False, color=Color[1]) # 设置字体样式
sheet1.cell(row= 2, column=8, value="哈哈").font =font # 序列
sheet1.cell(row= 2, column=8).alignment = Alignment(horizontal='center', vertical='center')
wk.save('./output/test02.xlsx') # 保存excel
上面的比较单一地解决应用某个单元格,一般我们是会批量处理5*10表格或其他,这时候就是需要结合循环,因为现在你要知道你可以操作单个单元格,那么一个个处理,像修复艺术品一样,慢慢最终呈现出一幅艺术品出来
import openpyxl
from openpyxl.styles import Alignment
from openpyxl.styles import Font # 导入字体模块
from openpyxl.styles import PatternFill # 导入填充模块excel = pd.ExcelFile('./output/妮维雅_really上报告.xlsx')
sheet_names = excel.sheet_nameswk = openpyxl.load_workbook('./output/妮维雅_really上报告.xlsx') # 加载已经存在的excelfor i in tqdm(range(len(sheet_names))):sheet = wk[sheet_names[i]]colors = ['00B04E', 'E24E49'] #绿与红color = 1if '好评' in sheet_names[i]:color = 0font = Font(u'微软雅黑', size=11, bold=False, italic=False, strike=False, color=Color[color]) # 设置字体样式temp_data = pd.read_excel('./output/妮维雅_really上报告.xlsx',sheet_name=sheet_names[i])for i in range(len(temp_data)):for j in range(len(temp_data.loc[0])):sheet.cell(row= i+2, column=j+1, value=temp_data.loc[i][j]).font =font # 序列sheet.cell(row= i+2, column=j+1).alignment = Alignment(horizontal='center', vertical='center') # 左右与上下居中wk.save('./output/妮维雅_really上报告.xlsx') # 保存excel
总结
上面可以看成是python操作excel,python还可以操作word,与PPT,俗称python办公自动化,对于一些机器的,重复性的,批量的,枯燥的人工操作,可以用代码来进行解决。解放自己脑动力,下面我会认真研究研究一声python办公自动化中的PPT
这篇关于python中设置Dataframe数据的自定义字体颜色与xlwt库操作excel单元格得到自己想要的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



