本文主要是介绍SPP Net 空间金字塔池化原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先对比一下RCNN和SPPNet的流程:
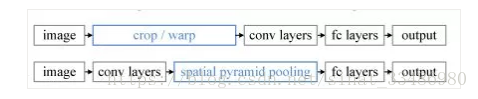
上面是RCNN流程,下面是SPPNet流程。
两者的共同点:都要先使用selective search选取可能的区域。
两者的不同点:RCNN对选择出来的每个图像区域进行卷积,提取特征,而SPPnet使用共享卷积,对输入图像进行一次卷积即可,然后将选择出来的每个图像区域通过坐标映射,对应到特征图上。
这是SPPnet的改进之处了,原来RCNN是对每一个候选框都进行卷积,提特征,SPPnet通过一次卷积的方式避免了重复计算问题。要一次卷积的话,就需要解决点与点之间的匹配,也就是说原图像的坐标经过映射之后到特征图上的坐标。这个其实是很容易想到的,对于卷积网络而言,只有stride才会改变网络的尺寸,所以对于左上角和右下角的坐标计算的方法如下:

这里的s是所有stride的乘积。
这样一幅图片经过卷积之后,对应的特征位置就能够找到,但是由于各个框的大小不一致,而神经网络则是要求输入的大小要相同,为了解决这个问题RCNN通过裁剪缩放的办法来解决这个问题,但是这样会带来精度的损失,你看,好好一幅图,左右两边明显看着就不一样。于是作者就提出了空间池化层来改善这个问题。

这个空间池化层其实思想也分简单,把每一个边框,分成3个层次去池化,也就是说将图片划分为4*4的小格,每个小格取一个数,2*2的小格每个小格进行池化和对整张图像进行全局池化,然后在合并起来,这样得到的输出就是固定的,具体见下图
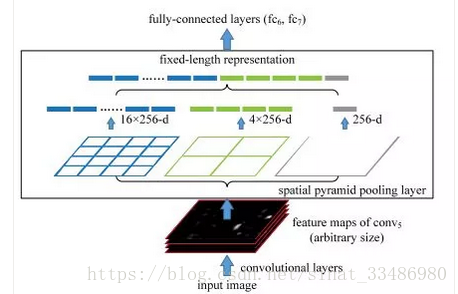
为了有助于理解,我重新画了一下spp的处理过程:
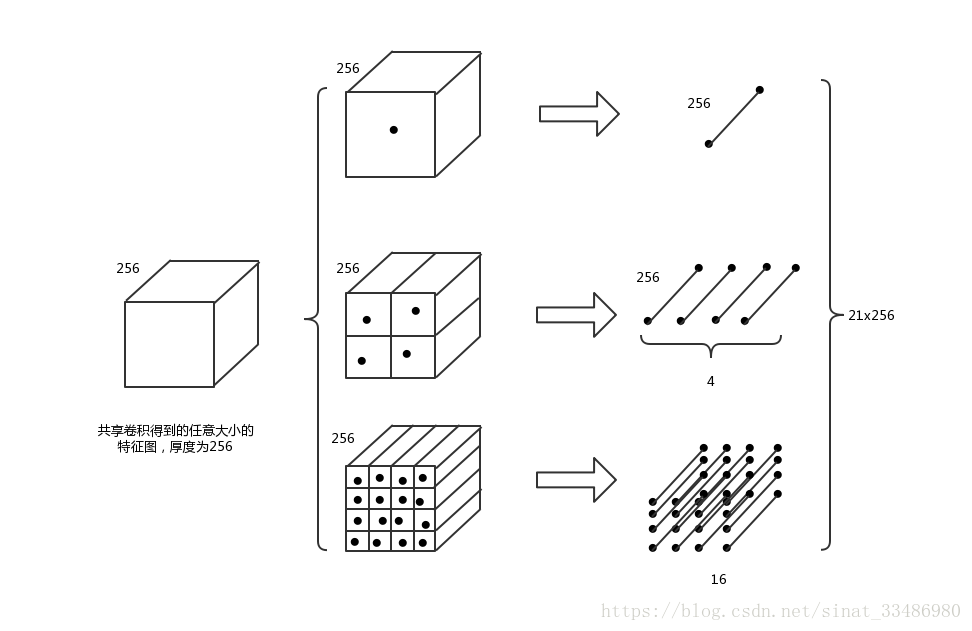
如图所示,对于选择的不同大小的区域对应到卷积之后的特征图上,得到的也是大小不一致的特征图区域,厚度为256,对于每个区域(厚度为256),通过三种划分方式进行池化:
(1)直接对整个区域池化,每层得到一个点,共256个点,构成一个1x256的向量
(2)将区域划分成2x2的格子,每个格子池化,得到一个1x256的向量,共2x2=4个格子,最终得到4个1x256的向量
(3)将区域划分成4x4的格子,每个格子池化,得到一个1x256的向量,共4x4=16个格子,最终得到16个1x256的向量
将三种划分方式池化得到的结果进行拼接,得到(1+4+16)*256=21*256的特征。
由图中可以看出,整个过程对于输入的尺寸大小完全无关,因此可以处理任意尺寸的候选框。
空间池化层实际就是一种自适应的层,这样无论你的输入是什么尺寸,输出都是固定的(21xchannel)。SPPNet改变了卷积的顺序,提出了自适应的池化层,避免了预测框大小不一致所带来的问题。从这个结构设计上来看,整体也非常巧妙,不像RCNN那样蛮力求解。
这篇关于SPP Net 空间金字塔池化原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






