本文主要是介绍使用【OpenI启智平台】进行模型训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
启智平台OpenI是一个人工智能开源开放平台,提供免费GPU算力可以进行模型训练。模式是git进行项目管理,可以创建调试任务调试代码以及保存镜像,创建训练任务训练模型,也提供推理和评测,我没用过就不讲述了。后来我才明白这是好多人工智能开放平台的运行模式,不同的是,这里训练任务修改的项目代码并不会保存到项目中,关掉任务就又回到原来的样子,所以我都用它debug找到问题点和创建镜像。
下面详细介绍使用。
项目创建
首先注册平台账号与登录,平台地址如下:https://openi.org.cn/。
登录成功后就进入个人中心界面,点击右上角的+创建项目。

也可以从Github上迁移过来,我大多通过“创建项目”创建。一般写上项目名称即可,创建成功后会有一个git链接。
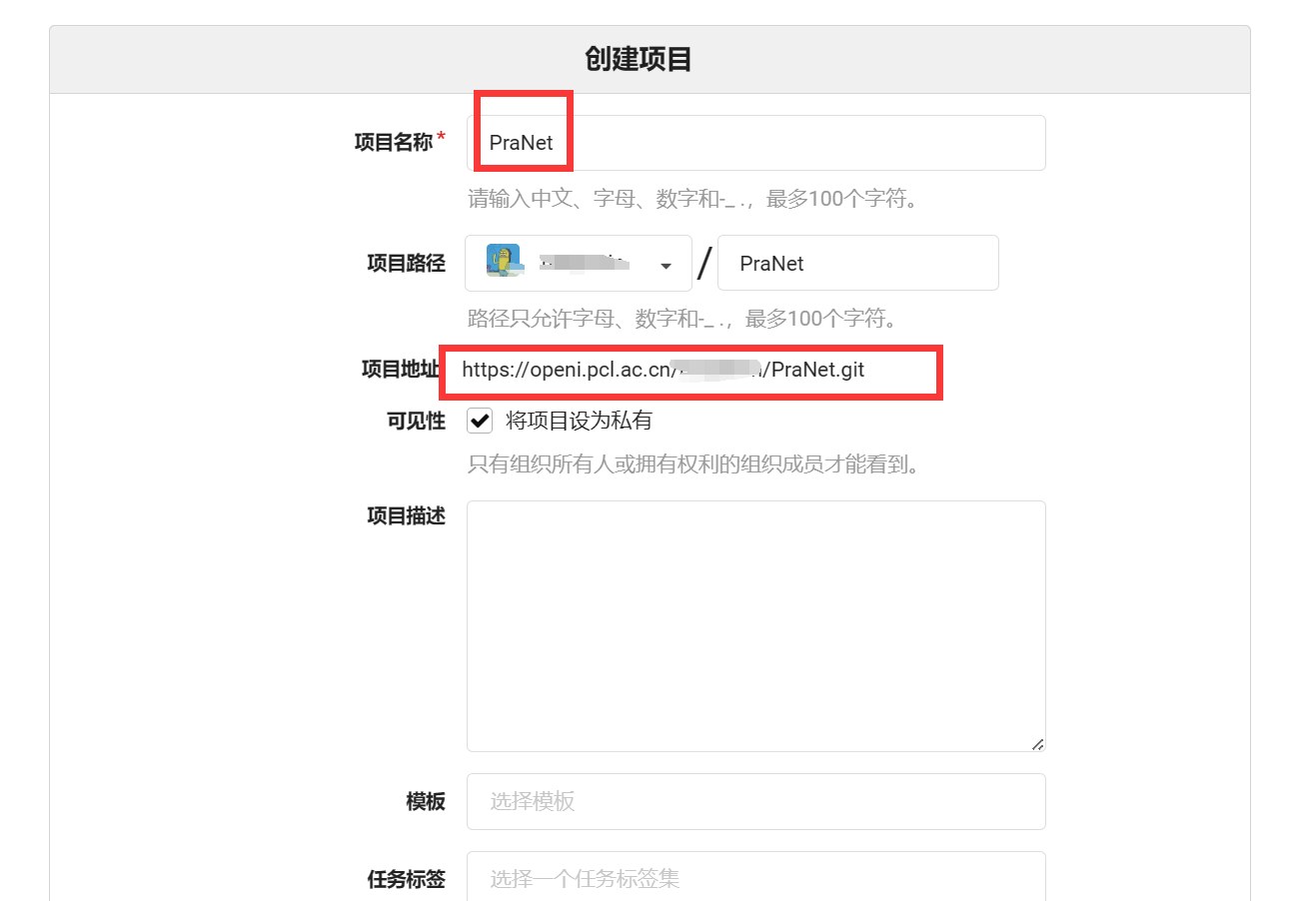
通过此git链接上传项目code和修改code。
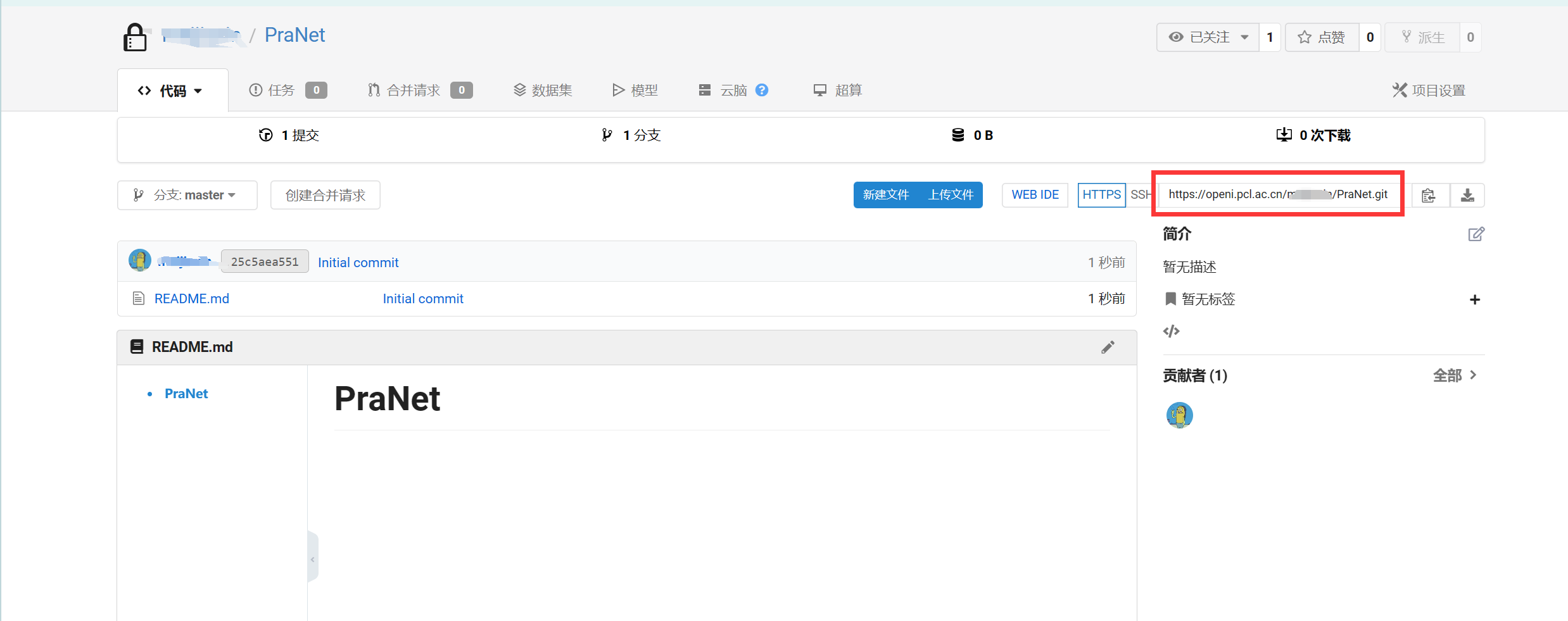
特别说明
训练脚本存储在 /code 中,数据集存储在 /dataset 中,预训练模型存放在运行参数 ckpt_url 中,训练输出请存储在 /model 中以供后续下载。
启智平台的训练脚本、数据集以及训练model输出存放在不同路径中,整个平台的目录如下:
root
|-- dataset
|-- code
|-- model
|-- ckpt_url
|-- ......
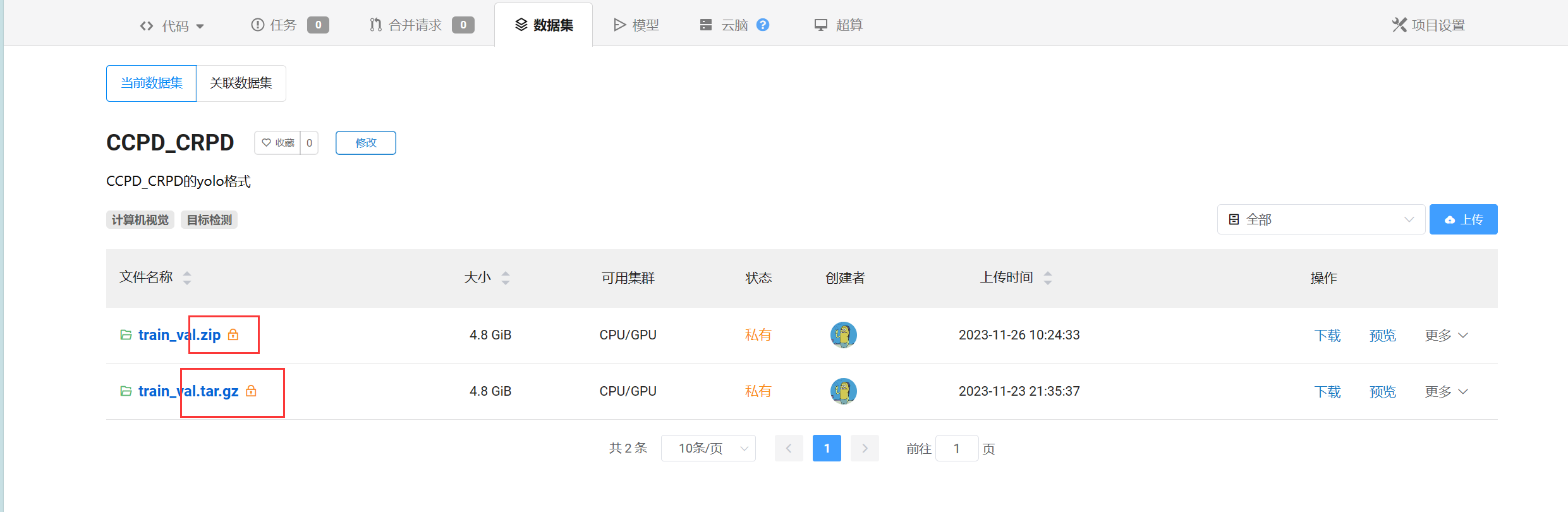
数据集
在数据集界面上传数据集,必须为zip或tar.gz格式的,在创建调试和训练任务时挂载上。
也可以使用公开数据集,输入数据集名称搜索,经典数据集大概率会有。
调试任务
通过调试任务可以定制你的镜像,找到bug点。
点开云脑,新建调试任务,选择需要的配置,

选择对应的镜像,第一次可以选一个适配的深度学习库(pytorch or tensorflow);挂载上数据集(不然就没有./data路径)。
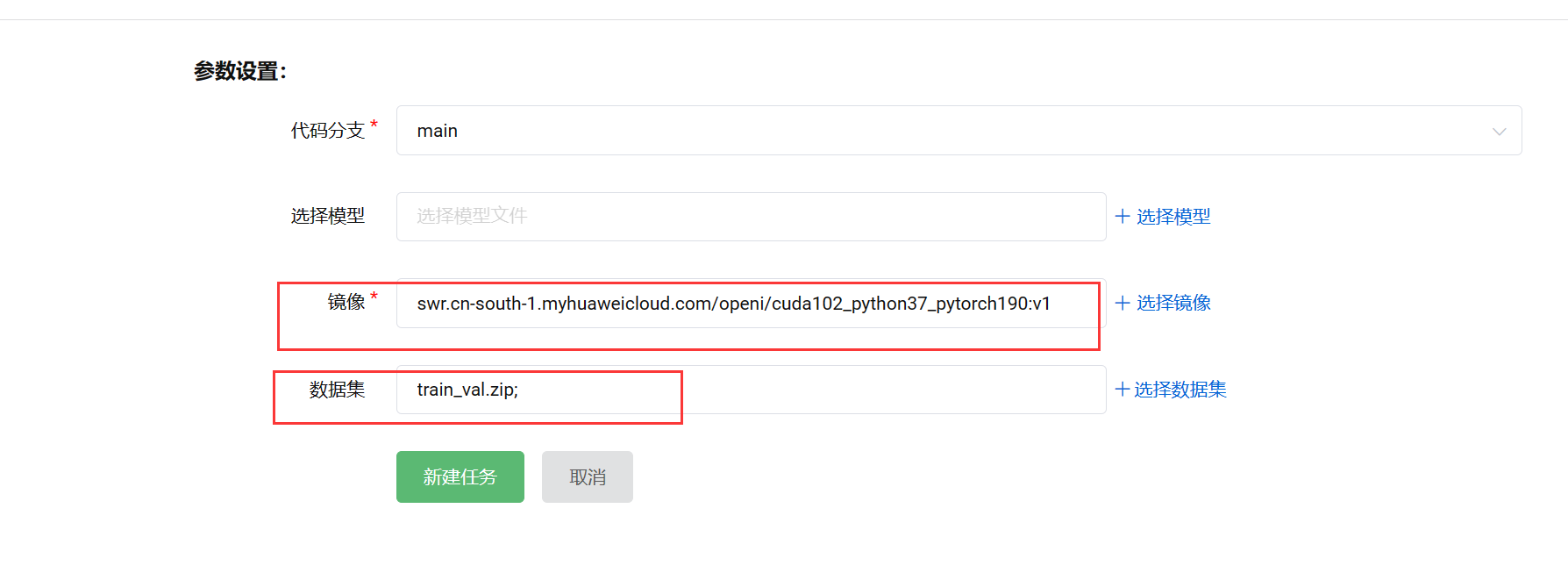
数据集读取路径: / d a t a s e t . . . . . /dataset..... /dataset.....

模型保存路径: / m o d e l . . . . . . /model...... /model......

(现在资源好紧张根本获取不到所以我就不配图了)调试的时候选择Jupyter即可。
运行train:
!python train.py
下载安装库:
!pip install ……
查看文件组织:
cd root
ls
训练任务
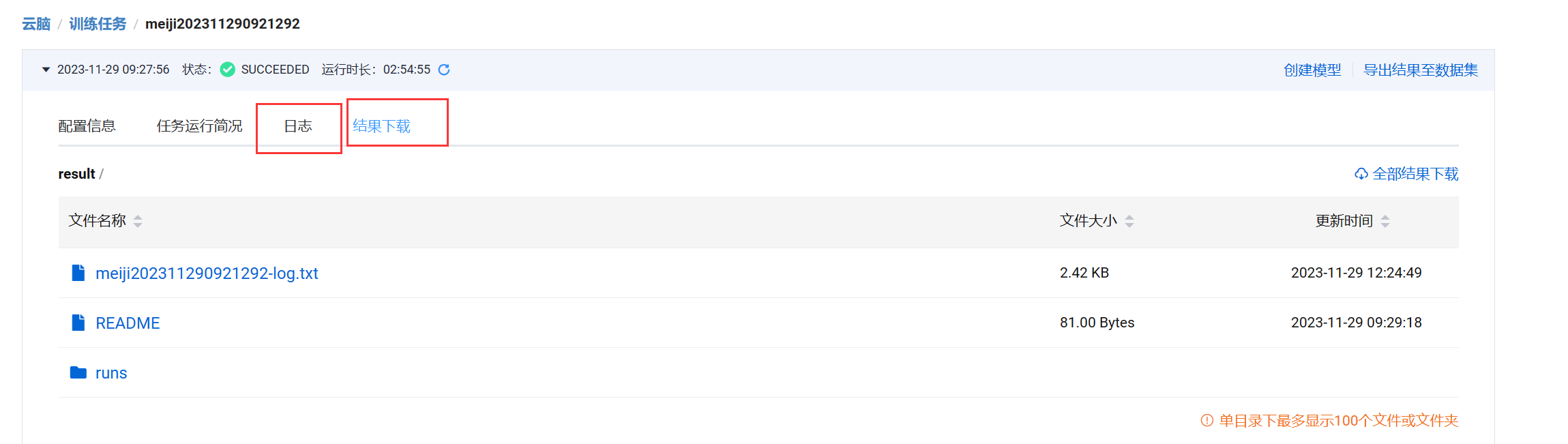
创建同调试任务,如果在调试任务界面能训练成功,就可以直接在训练任务中运行。
“日志”项可以查看运行日志;“结果下载”提供 / r e s u l t /result /result路径下的所有文件的下载。
这篇关于使用【OpenI启智平台】进行模型训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





