本文主要是介绍大模型要占你多少内存?这个神器一键测量,误差低至0.5MB,免费可用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
大模型训练推理要用多少内存?
打开这个网页一测便知,测量误差小至0.5MB。
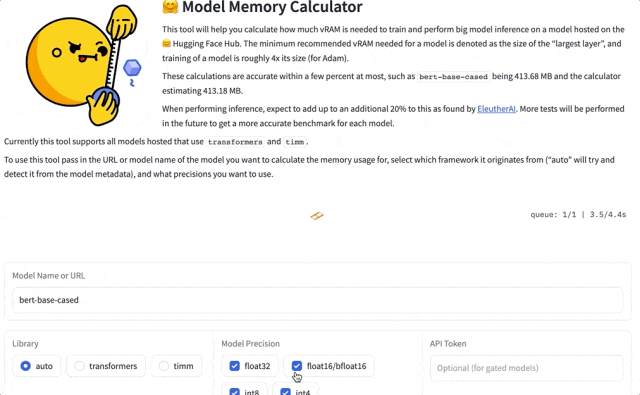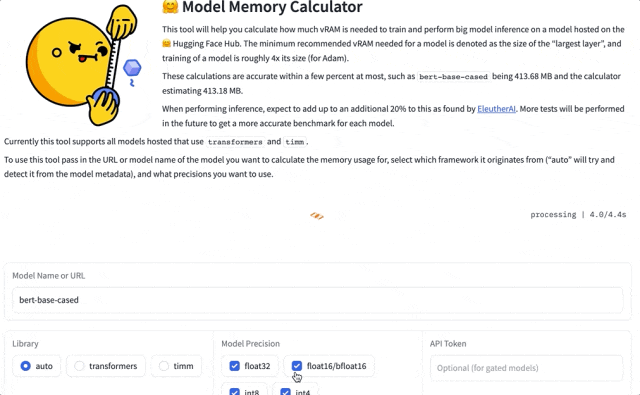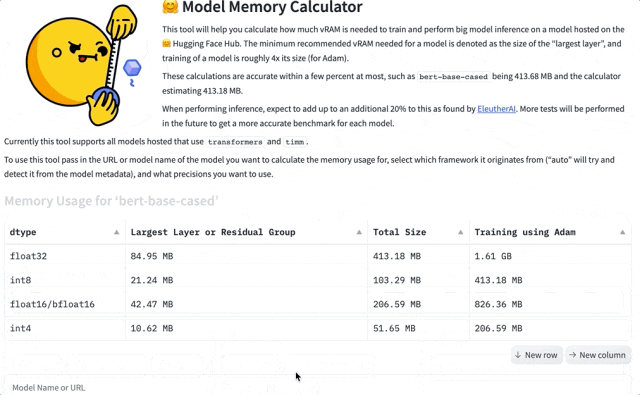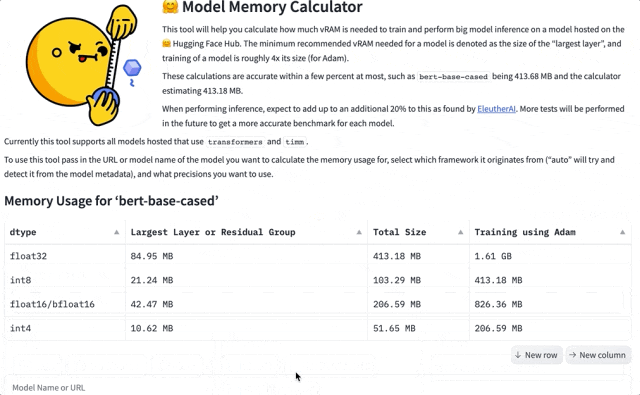
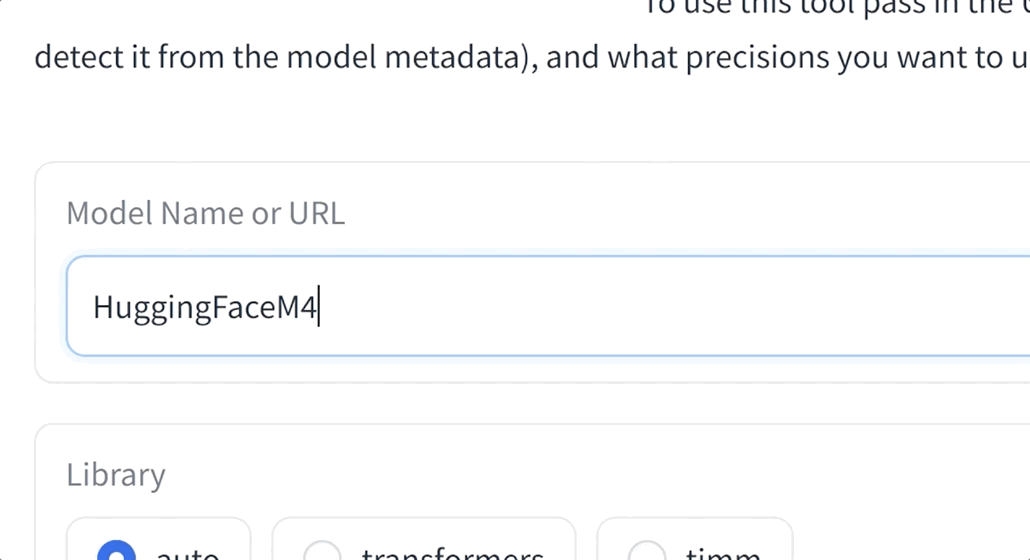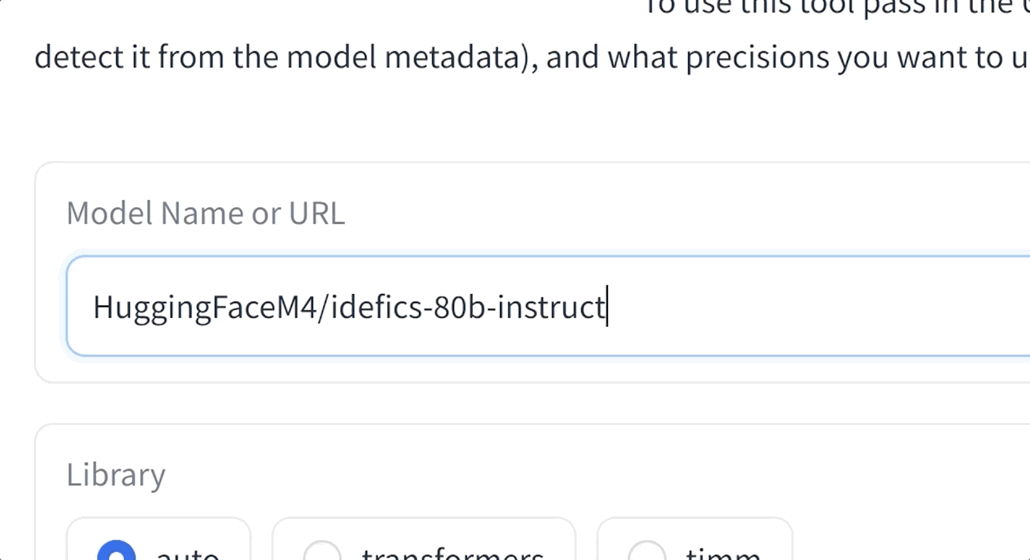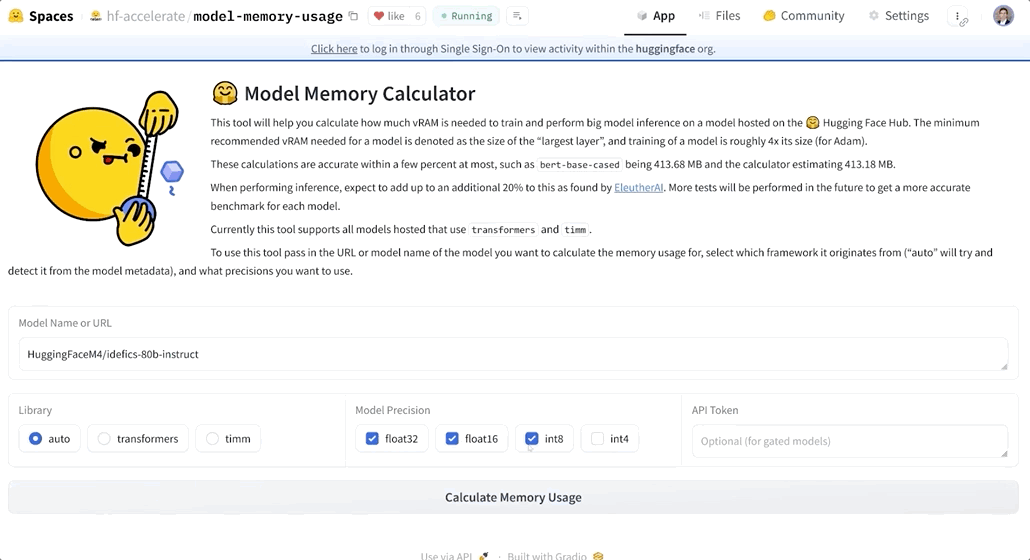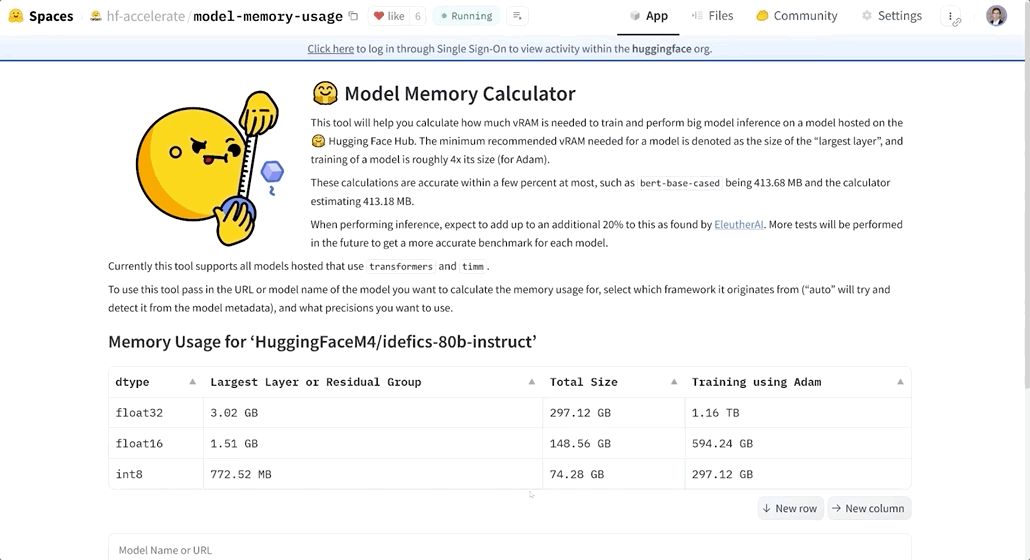
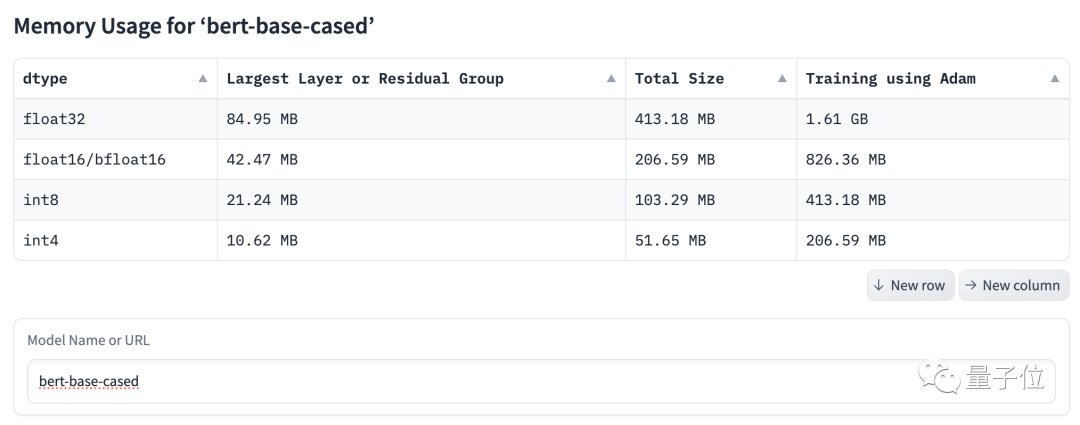
比如模型bert-base-case Int8估计占用413.18 MB内存,实际占用为413.68MB,相差0.5MB,误差仅有0.1%。

操作也很简单,输入模型名称,选择数据类型即可。
这就是HuggingFace Space上的最新火起来工具——Model Memory Calculator,模型内存测量器,在网页端人人可体验。
要知道,跑大模型最头疼的问题莫过于:GPU内存够吗?
现在能先预估一波、误差很小,让不少人大呼“Great”!

实际推理内存建议多加20%
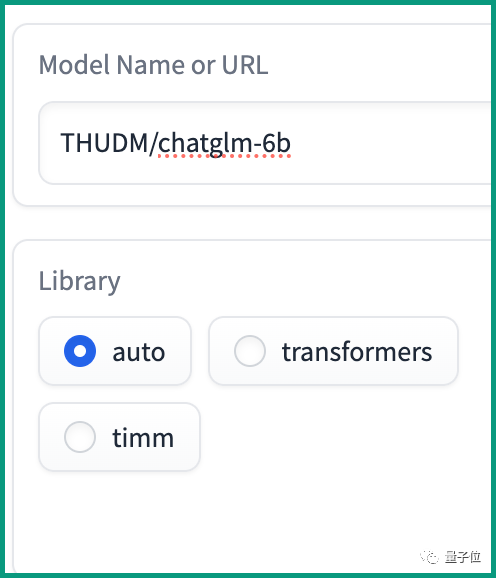
使用第一步,需要输入模型的名称。
目前支持搜索在HuggingFace Transformers库和TIMM库中的模型。
比如想要看GLM-6B的情况,可以输入“THUDM/chatglm-6b”。
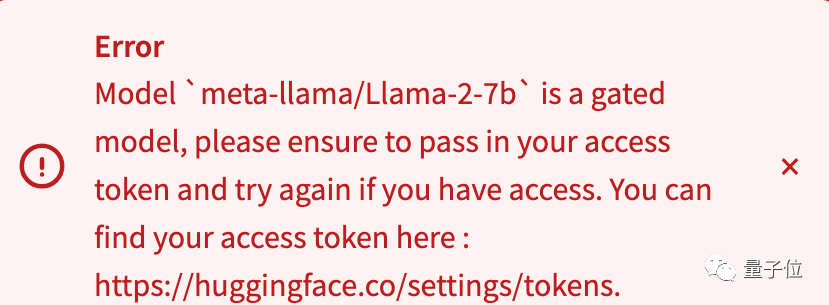
不过有一些模型会存在限制,需要获取API token后才能开始计算,比如Llama-2-7b。
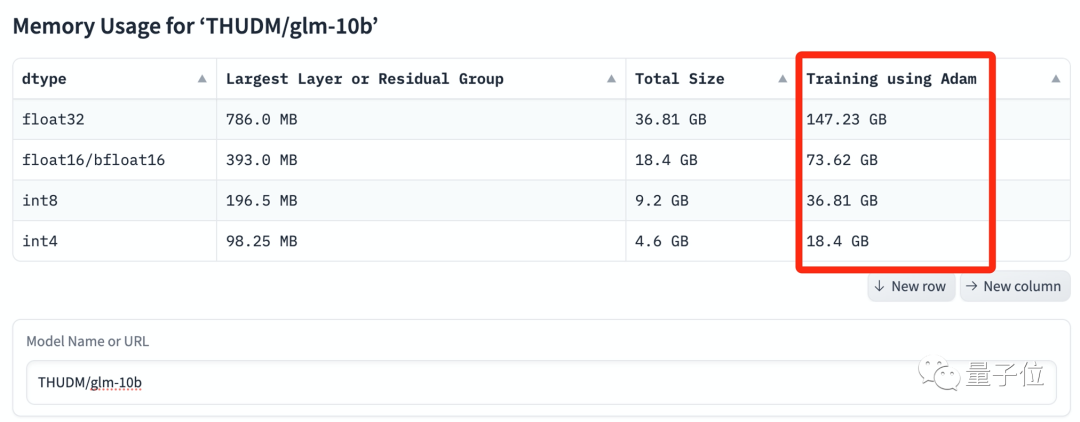
我们找了几个大模型实测,可以看到当模型规模达到百亿参数后,内存要求被直线拉高。
基础版的BERT还是对GPU相当友好滴 。
。
而在实际推理过程,EleutherAI发现需要在预测数据基础上,预留20%的内存。具体举例如下:

作者小哥热衷开源项目
最后来介绍一下带来这个项目的小哥Zach Mueller。
他本科毕业于西佛罗里达大学,主修软件设计与开发,热衷开源,在GitHub有1k粉丝。之前做过很多和Fast.ai框架有关的开源项目。

传送门:
https://huggingface.co/spaces/hf-accelerate/model-memory-usage
— 完 —
「AIGC+垂直领域社群」
招募中!
欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC!
请备注您想加入的垂直领域「教育」或「广告营销」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。

点这里👇关注我,记得标星哦~
这篇关于大模型要占你多少内存?这个神器一键测量,误差低至0.5MB,免费可用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








