本文主要是介绍爬虫----爬取网页图片(以大熊猫为例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是爬虫?
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。
爬虫流程
其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤
- 模拟请求网页。模拟浏览器,打开目标网站。
- 获取数据。打开网站之后,就可以自动化的获取我们所需要的网站数据。
- 保存数据。拿到数据之后,需要持久化到本地文件或者数据库等存储设备中。
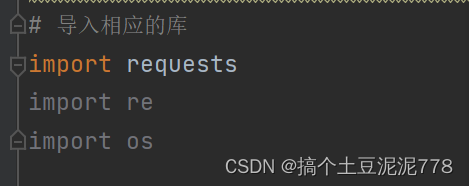
一.导入相应的库
二. 获取网站源码
我们需要创建一个函数获取源码
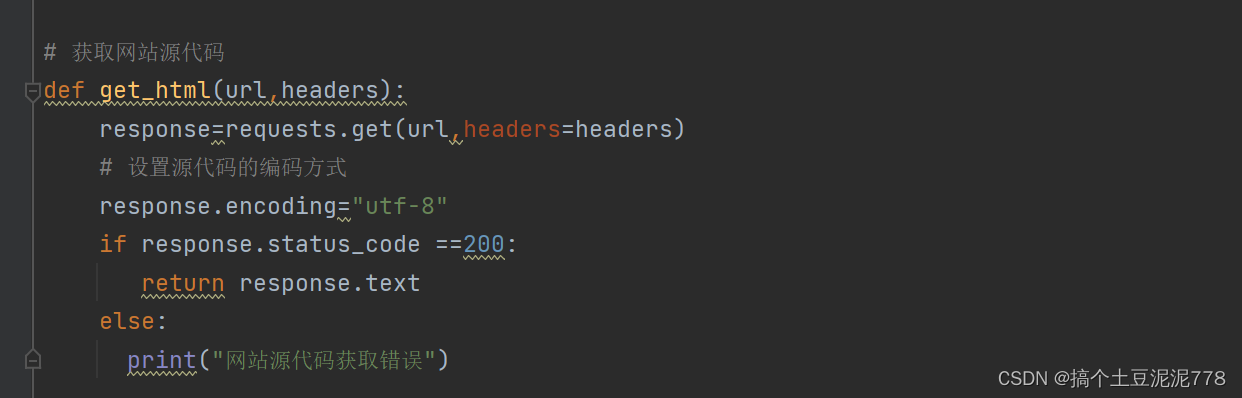
其中 utf-8为源代码的中文编码,response.status_code==200 表示网站源代码获取正确
三.提取图片的源地址
这时候需要用到正则表达式 
要重点关注这个“thumbURL”可根据这个找到图片的网址
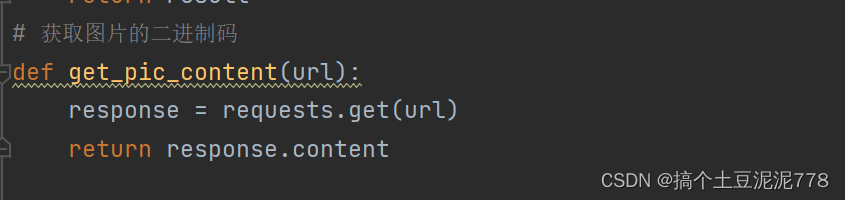
四.获取图片的二进制码
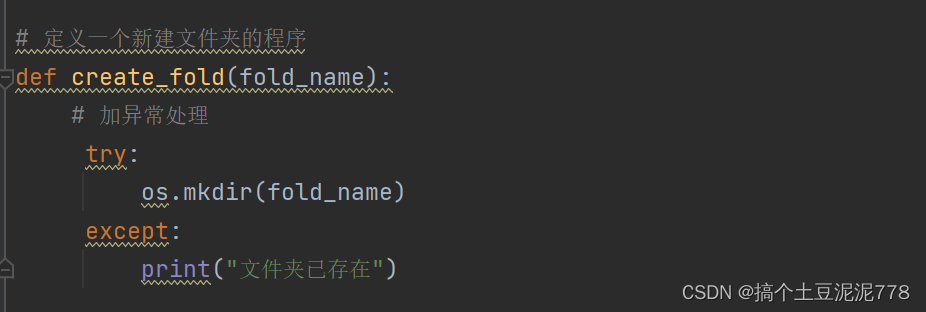
五.定义一个新建文件夹程序
创建一个文件夹目录 保存图片
六.保存图片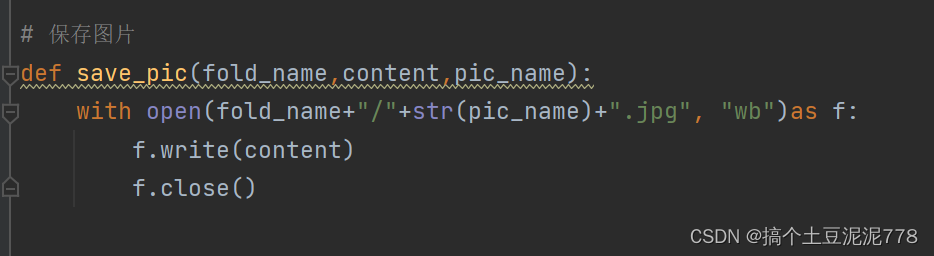
七. 定义一个main函数
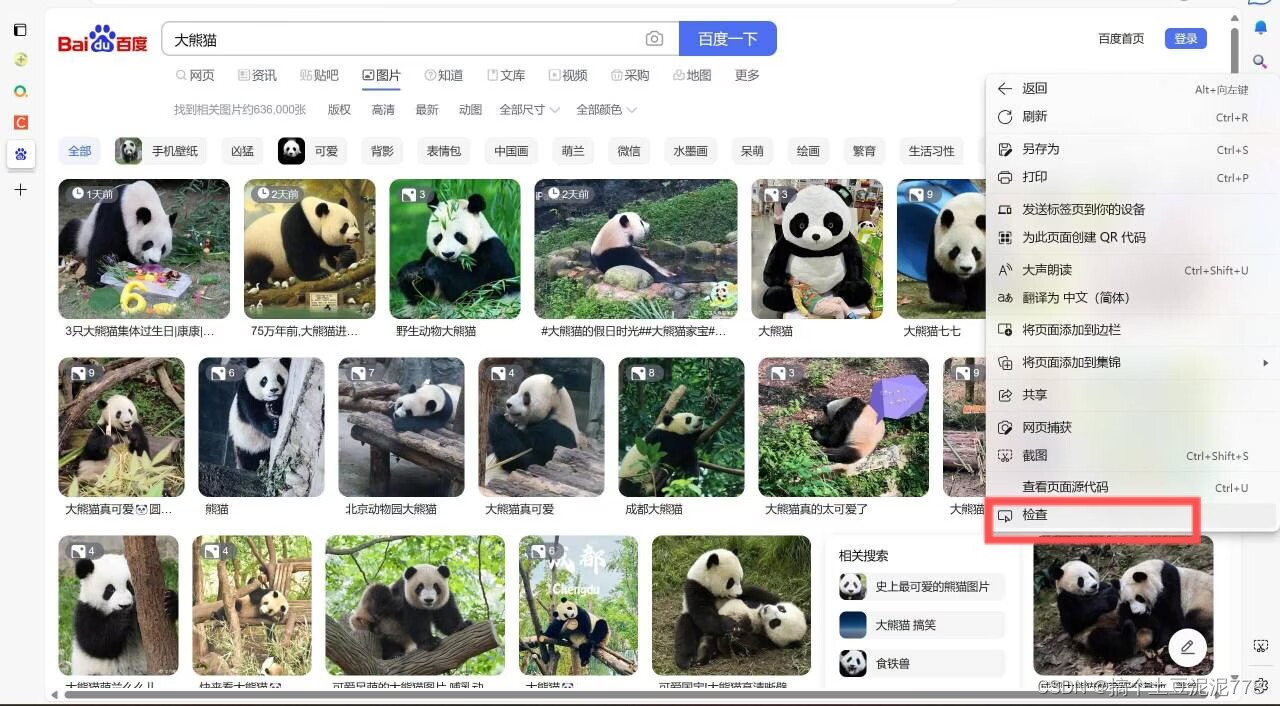
1.点击鼠标右键 找到检查
2.然后点击网络-fetch-标头-请求url--再复制其路径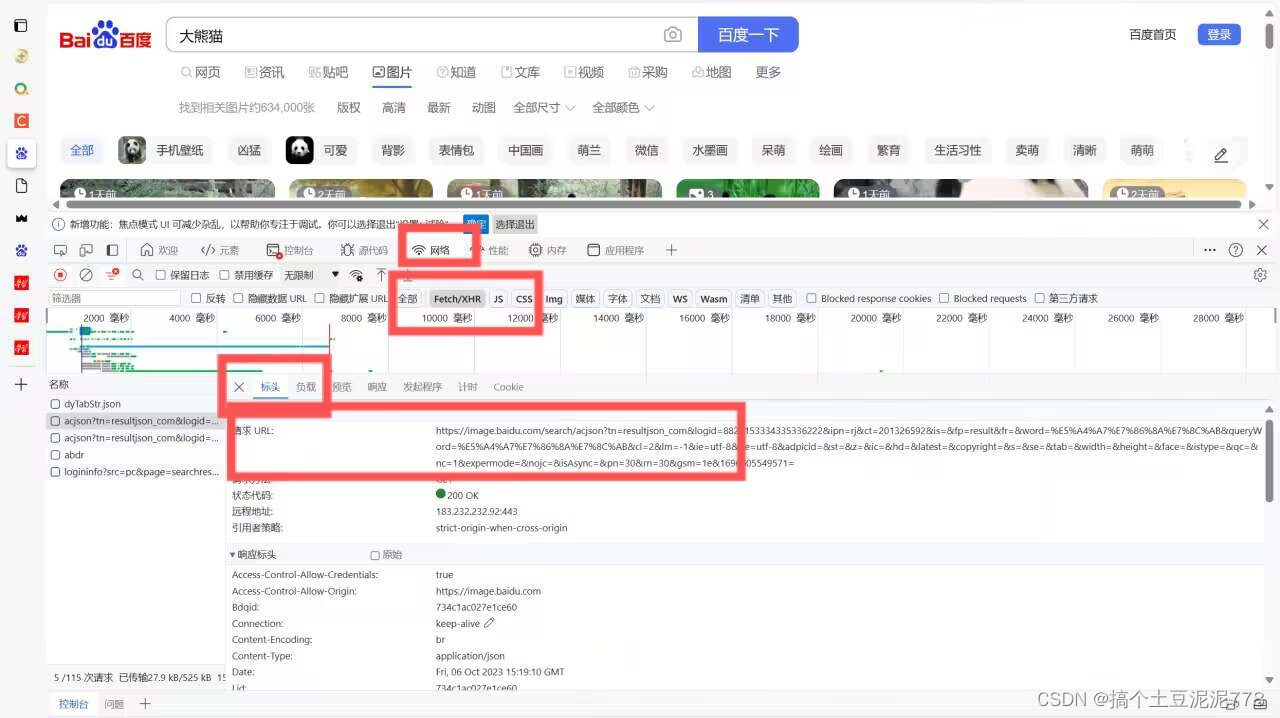
将其复制到这...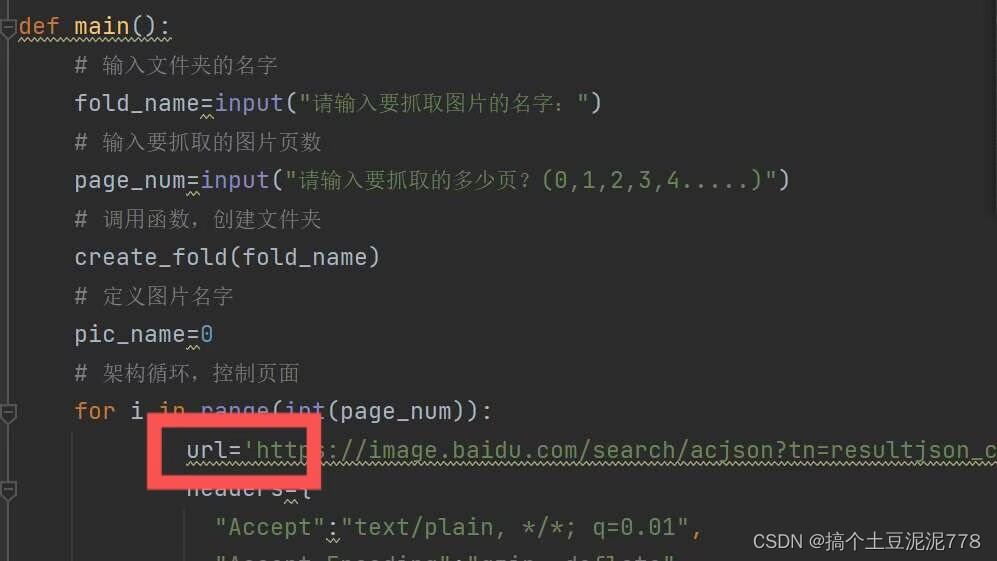
3.再将其请求标头复制下来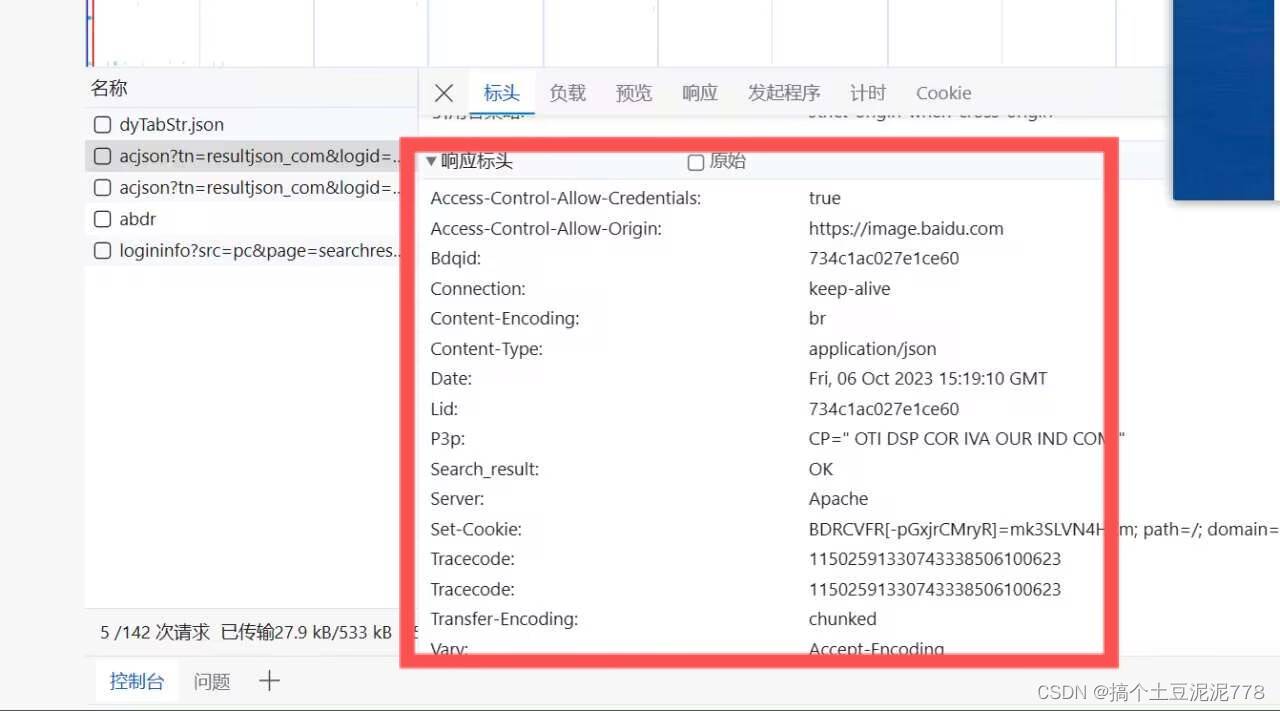 粘贴至headers处位置。
粘贴至headers处位置。
注意:复制前请加三个双引号 减少一些换行。
4.点击负载--将其下面的内容复制下来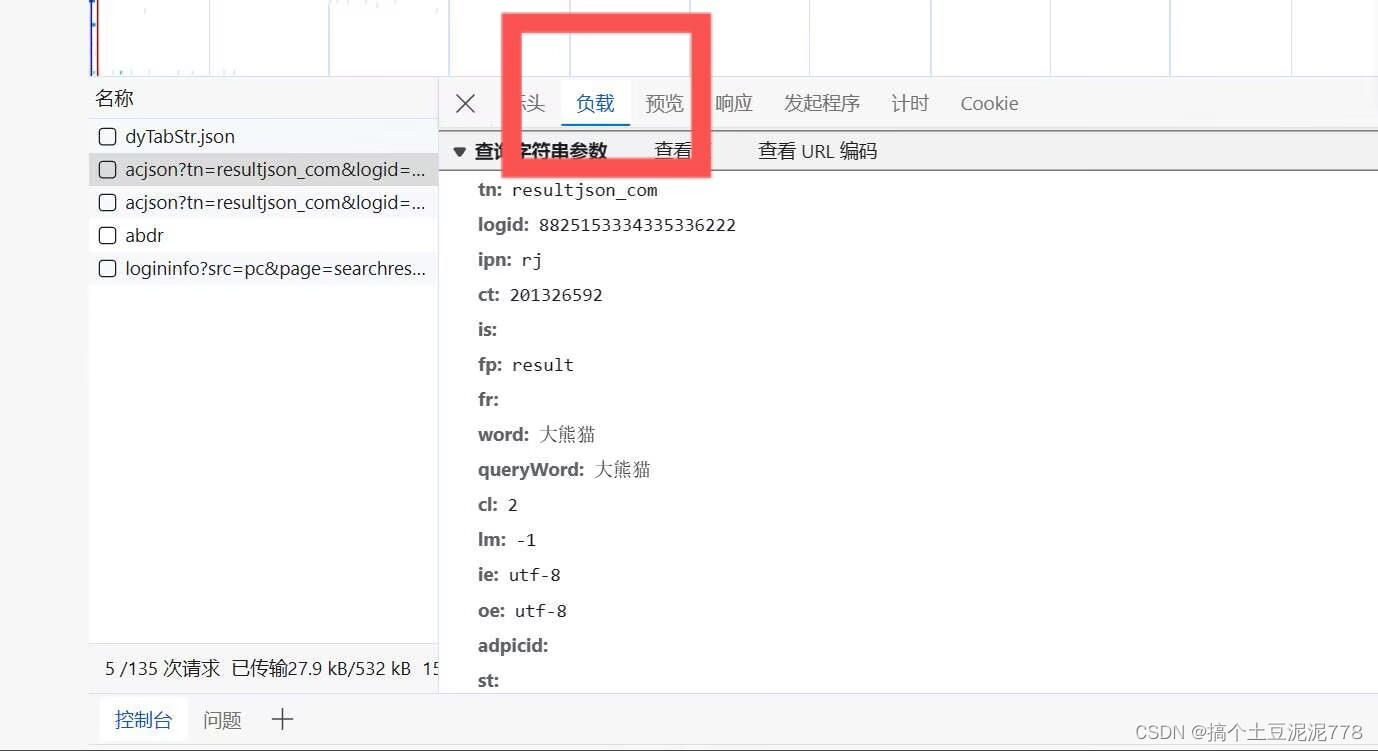
粘贴至此处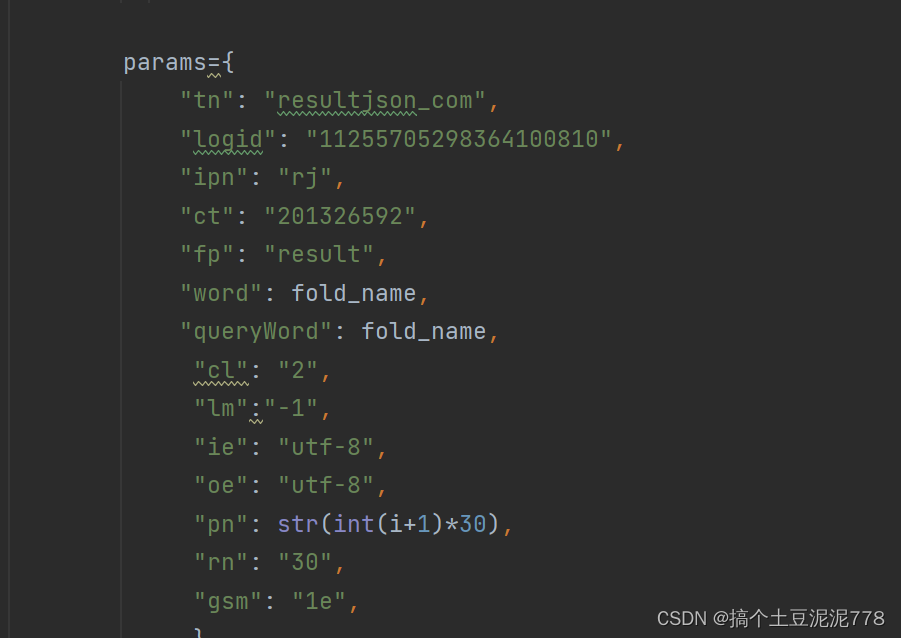 八.爬取图片
八.爬取图片
使用一个for循环遍历列表 自动爬取图片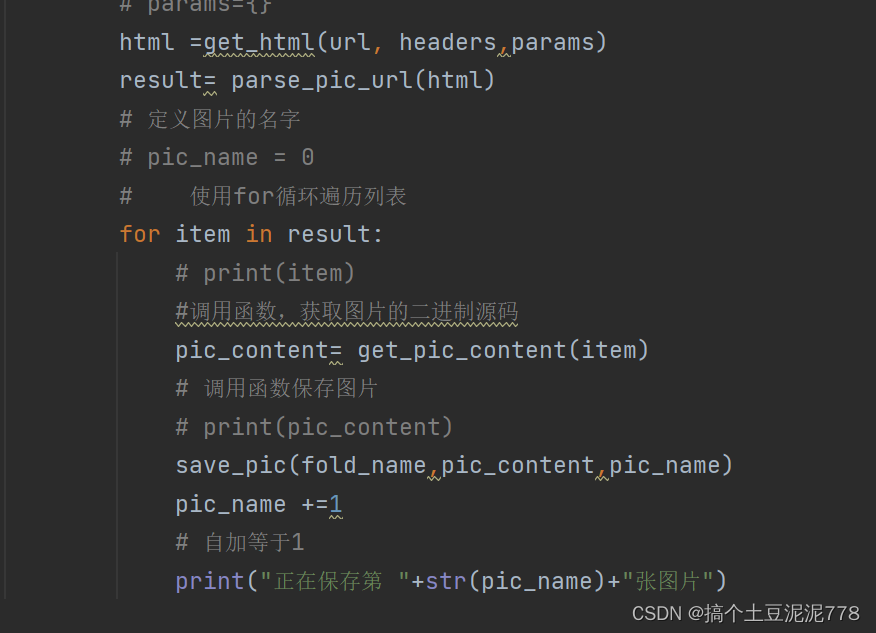 以上就是如何爬取图片的全部内容
以上就是如何爬取图片的全部内容
下面是源代码
# 获取网站源代码
def get_html(url,headers,params):response=requests.get(url,headers=headers,params=params)# 设置源代码的编码方式response.encoding="utf-8"# response.status_code ==200:return response.text# else:# print("网站源代码获取错误")# 提取图片的源地址
def parse_pic_url(html):result = re.findall('"thumbURL":"(.*?)"',html,re.S)return result
# 获取图片的二进制码
def get_pic_content(url):response = requests.get(url)return response.content# 保存图片
def save_pic(fold_name,content,pic_name):with open(fold_name+"/"+str(pic_name)+".jpg", "wb")as f:f.write(content)f.close()# 定义一个新建文件夹的程序
def create_fold(fold_name):# 加异常处理try:os.mkdir(fold_name)except:print("文件夹已存在")# 定义一个main函数调用get_html函数
# 乱码的话 把br去掉
def main():# 输入文件夹的名字fold_name=input("请输入要抓取图片的名字:")# 输入要抓取的图片页数page_num=input("请输入要抓取的多少页?(0,1,2,3,4.....)")# 调用函数,创建文件夹create_fold(fold_name)# 定义图片名字pic_name=0# 架构循环,控制页面for i in range(int(page_num)):url='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12466994017284006009&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&queryWord=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=120&rn=30&gsm=78&1695863913502='headers={"Accept":"text/plain, */*; q=0.01","Accept-Encoding":"gzip, deflate","Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection":"keep-alive","Cookie":'BDqhfp=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87%26%26NaN-1undefined%26%263876%26%264; BIDUPSID=2DDA08F2489166F8296AF37F32E27AC5; PSTM=1657273565; BDUSS=d1dzVkRzBkNDI5bzBYYXpkbFFTUThrbU9RWHZDRVFLWU5ERDlYRWNROXdhVzVqSVFBQUFBJCQAAAAAAAAAAAEAAAA7gbiQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHDcRmNw3EZjT2; BDUSS_BFESS=d1dzVkRzBkNDI5bzBYYXpkbFFTUThrbU9RWHZDRVFLWU5ERDlYRWNROXdhVzVqSVFBQUFBJCQAAAAAAAAAAAEAAAA7gbiQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHDcRmNw3EZjT2; BAIDUID=1D4F926B02D9111225B14B9D71AAF576:FG=1; indexPageSugList=%5B%22IndentationError%3A%20unindent%20does%20not%20match%20any%20outer%20indentation%20level%22%5D; BAIDUID_BFESS=1D4F926B02D9111225B14B9D71AAF576:FG=1; BA_HECTOR=a12l848g0g0g058ka580a02v1ih7p2m1p; ZFY=N9wyLiRfHuUeTr4zDV5tCQ2wwc4SwgwmeE0lKZEByLc:C; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; RT="z=1&dm=baidu.com&si=5759fd95-e463-4960-9c0b-89d93e94682f&ss=ln1gxjpu&sl=9&tt=h12&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=sgz0&ul=1ol8m&hd=1olbp"; BDRCVFR[kSyA9a8U-kc]=mk3SLVN4HKm; delPer=0; PSINO=1; BDRCVFR[WDXKkmmntP_]=bF2OOhpFAEmuvN4rjT8mvqV; H_PS_PSSID=; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=ala; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; ab_sr=1.0.1_MzY1MmM4ODNmY2M3MDgzNTExNGUzZTgxNzQwMDI4ZTIyNGMwZWJkZWY2NzBiMTc4OGE5YWY5M2FmZTVlZTRhYTljNGRkN2M5NzllNTI5ZmQwMDJjNjMyZDFjMWU3OTZhZDUxNjFkMDA2YjAyYTM1OTQ1NTNmYWE3YjE2OGVkNDE0NWJkZThkNDY4MDVkZWQ1NGY3NDQ3NTliMGE0N2U3Ng==',"Host":"image.baidu.com","Referer":"https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B4%F3%D0%DC%C3%A8%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MTEsMCw0LDMsMSw2LDUsMiw4LDcsOQ%3D%3D","Sec-Ch-Ua":'"Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"',"Sec-Ch-Ua-Mobile":"?0","Sec-Ch-Ua-Platform":'"Windows"',"Sec-Fetch-Dest":"empty","Sec-Fetch-Mode":"cors","Sec-Fetch-Site":"same-origin","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.41","X-Requested-With":"XMLHttpRequest"}params={"tn": "resultjson_com","logid": "11255705298364100810","ipn": "rj","ct": "201326592","fp": "result","word": fold_name,"queryWord": fold_name,"cl": "2","lm":"-1","ie": "utf-8","oe": "utf-8","pn": str(int(i+1)*30),"rn": "30","gsm": "1e",}# 爬取网站的时候 不粘贴header时 网站会以为是爬虫 就会乱码 再从检查那找到header 粘贴下来 先打三个双引号,再加引号和逗号 注意报错 url后不加逗号# 运行完了之后 找到thumbURL 这是爬取图片或者视频的链接# params={}html =get_html(url, headers,params)result= parse_pic_url(html)# 定义图片的名字# pic_name = 0# 使用for循环遍历列表for item in result:# print(item)#调用函数,获取图片的二进制源码pic_content= get_pic_content(item)# 调用函数保存图片# print(pic_content)save_pic(fold_name,pic_content,pic_name)pic_name +=1# 自加等于1print("正在保存第 "+str(pic_name)+"张图片")# 把所有代码放到for循环里面 按tab键
# 执行main函数if __name__ == '__main__':main()这篇关于爬虫----爬取网页图片(以大熊猫为例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





