本文主要是介绍DCC2023:基于梯度线性模型的帧内色度预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本来自DCC2023文章《Gradient Linear Model for Chroma Intra Prediction》

在VVC中引入了CCLM工具,CCLM用于帧内预测,它根据一个线性模型通过亮度像素重建值获得色度像素的预测值。对于YUV420格式的视频,需要先将亮度分量使用低通滤波器下采样到和色度分量同样的分辨率,然后使用线性模型计算色度的预测值。然而下采样过程会丢失空域信息(例如边界、梯度),为了解决这个问题,文章提出了梯度线性模型(Gradient Linear Model, GLM),GLM使用高通梯度滤波器来对亮度进行下采样。文章提出了两个GLM模型:两参数模式、三参数模型。GLM已经被集成到ECM-6.0和ECM-7.0参考软件中。
CCLM
CCLM使用线性模型通过亮度重建像素预测色度,
alpha和beta是模型参数,使用上方和左侧重建像素计算。
对于YUV420和YUV422视频,需要使用低通滤波器对亮度重建像素下采样,下面是420格式下采样使用的滤波器,
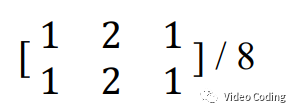
图1是420格式亮度和色度像素对应的位置,
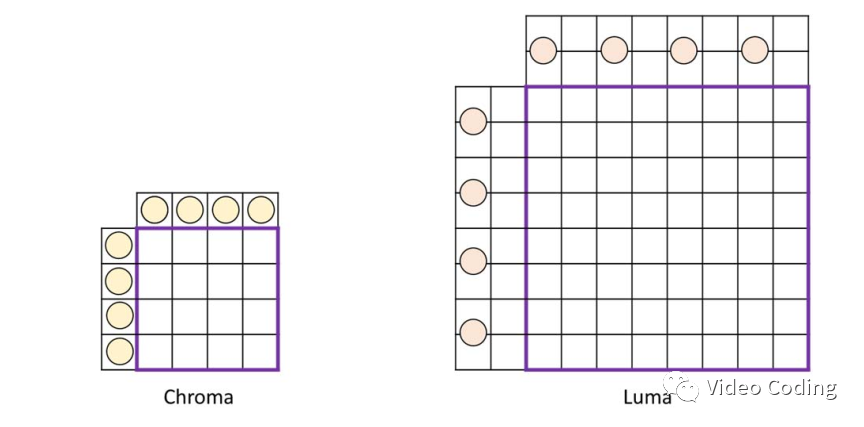
图1
GLM
Two-parameter GLM
2参数GLM和CCLM的结构一样,唯一的区别是使用的下采样滤波器不同。
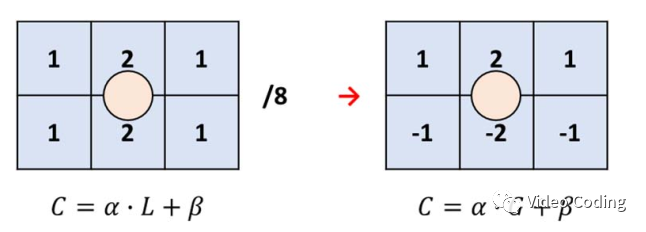
图2 使用垂直梯度滤波器取代低通滤波器
图2是垂直滤波器的一个例子,然后使用下面的线性模型预测色度值。可以看见它和CCLM过程一样,只不过输入由下采样的亮度值L变为亮度的梯度值G。
GLM共有16个不同方向的梯度滤波器,如图3,编码器可以自适应选择。

图3 2-parmeter GLM的16个滤波器
Three-parameter GLM
3-parmeter GLM将CCLM和2-parmeter GLM相结合,如下式,
CCLM计算模型参数使用1行/列重建像素,为了增加模型的鲁棒性,3-parmeter GLM在计算模型参数时使用6行/列重建像素。
实验结果
实验平台ECM-5.0,实验配置All Intra和Random Access,
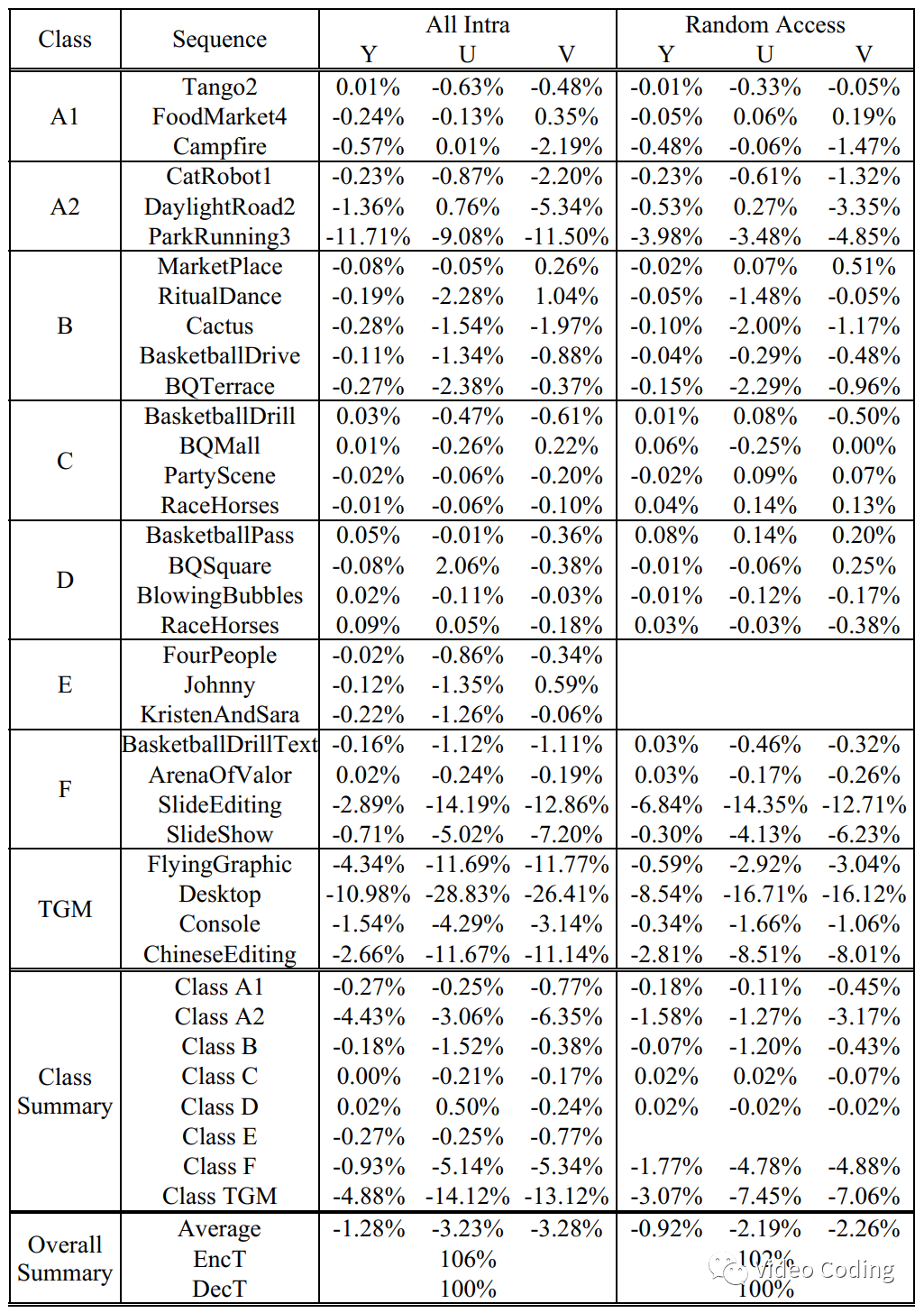
表1是2-parmeter GLM的实验结果,表2是3-parmeter GLM的实验结果,对比表1和表2可以发现3-parmeter GLM在屏幕内容上表现更好。
表1 2-parmeter GLM在ECM5.0的结果

表2 3-parmeter GLM在ECM5.0的结果
感兴趣的请关注微信公众号Video Coding
这篇关于DCC2023:基于梯度线性模型的帧内色度预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







