本文主要是介绍【halcon深度学习之那些封装好的库函数】preprocess_dl_dataset,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
函数分析
preprocess_dl_dataset 是一个用于预处理深度学习数据集的程序。以下是该程序的详细介绍:
参数:
-
DLDataset (输入): 要进行预处理的 DLDataset 字典。
-
DataDirectory (输入): 存储数据的路径。默认值是 ‘dl_dataset’。
-
DLPreprocessParam (输入): 包含预处理参数的字典。
-
GenParam (输入): 具有通用参数的字典。默认值为空字典。
-
DLDatasetFileName (输出): 写入的 DLDataset 字典的文件路径。
详细描述:
该程序根据包含在字典 DLPreprocessParam 中的参数对字典 DLDataset 中的样本进行预处理。预处理的结果包括修改后的 DLDataset 字典以及每个样本的预处理后字典 DLSample。这些字典将被写入到指定的 DataDirectory 中,同时该目录的名称和路径将被返回到字符串 DLDatasetFileName 中。
此程序接受字典 GenParam 中的以下通用参数:
-
‘overwrite_files’: 确定是否覆盖可能存在的目录。
- ‘true’: 在写入文件之前删除可能存在的目录
DataDirectory。 - ‘false’(默认): 如果目录存在,则抛出错误。
- ‘auto’: 只有在有必要时才进行预处理。为了重用可能存在的目录
DataDirectory,它必须包含与输入的DLDataset和DLPreprocessParam对应的完全预处理的数据集。
- ‘true’: 在写入文件之前删除可能存在的目录
-
‘show_progress’: 如果设置为 true,则在窗口中显示预处理的进度。默认为 true。
-
‘class_weights’: 为
DLDataset中的每个类别设置权重。- 如果设置为 [],则使用
calculate_dl_segmentation_class_weights计算类别权重。仅适用于 ‘type’ 为 ‘segmentation’ 的模型。 - 默认值是 []。
- 如果设置为 [],则使用
-
‘max_weight’: 设置
calculate_dl_segmentation_class_weights的 ‘max_weight’ 参数。详细信息请参阅相应的文档。仅适用于 ‘type’ 为 ‘segmentation’(分割) 的模型。- 默认值是 []。
步骤:
该程序执行以下步骤:
- 使用
gen_dl_samples为每个样本生成一个DLSample字典。 - 使用
preprocess_dl_samples进行标准预处理。 - 使用
write_dict将DLSample字典写入文件,并将文件的路径存储在DLDataset字典的 ‘dlsample_file_name’ 条目中。 - 将包括生成和预处理的
DLSample字典的路径的DLDataset字典写入DLDatasetFileName文件。
对于 ‘type’ 为 ‘segmentation’ 的模型,还会执行以下额外的步骤:
- 使用
calculate_dl_segmentation_class_weights计算类别权重。 - 为每个
DLSample生成一个权重图像,并保存更新后的DLSamples。
注意:
请注意,在预处理之后,请勿更改此文件夹的内容。
使用分析
首先通过 create_dl_preprocess_param_from_model 这个函数把模型里设置的参数,提取出来。所以 preprocess_dl_dataset 一是需要即将被处理的数据集字典,而是需要模型已经配置好的参数。此函数会根据模型里的参数对数据集进行预处理!
那为啥需要预处理呢?
首先,我从使用的过程观察,当参数 show_progress 被设置为 true的时候,此时会产生一个弹框,显示预处理的过程,这个过程大概从几十秒到几分钟不等:
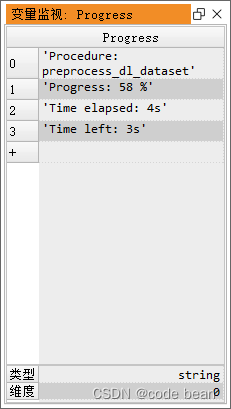
过程完成之后,你会发现在第二个参数指定的文件夹下,会多长一个文件和一个文件夹:
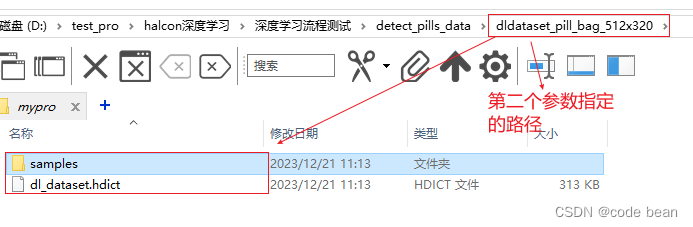
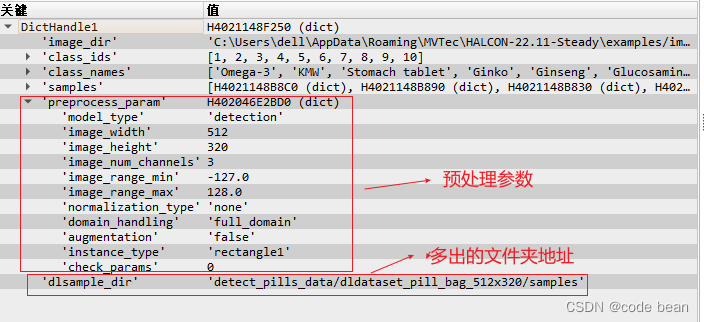
如果使用 read_dict (DLDatasetFilename, [], [], DictHandle1) 读取整个字典你将看到如下内容。
这些其实就是之前的读取到的数据集啊!不过多了一些东西!
每个samples里也多出了一个字段
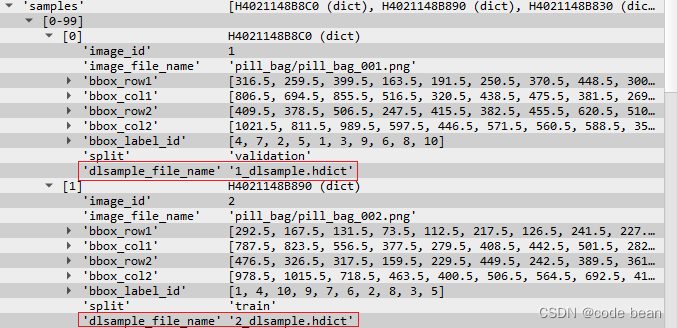
在看看多出的整个samples文件夹:
发现有很多的字典,其实每个字典里面都会包含一个图片,之前的图片是以文件的形式存在的
而现在以halcon的图片对象,保存再halcon的字典类型里面了!
读取其中的一个字典:
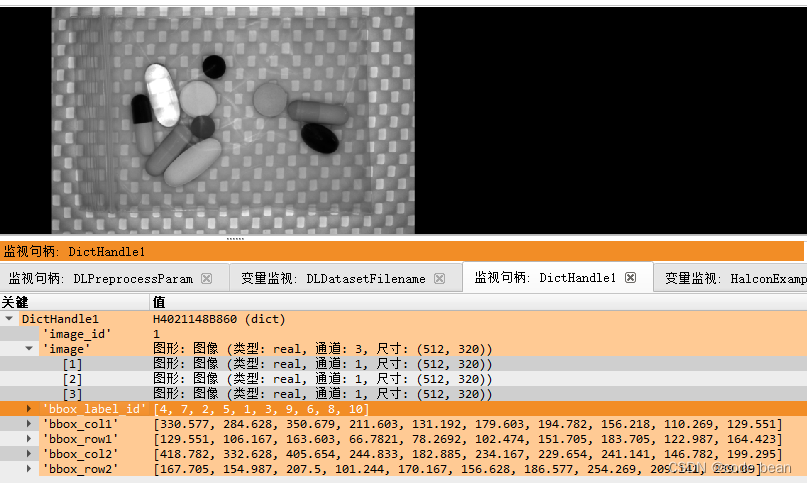
很明显,其中包含了图片,和该图片对于的标注信息,以及所有的类别信息。
有人可能会问,这些不是在数据集都有吗?为啥这里再整合一次呢?
我决定,原因可能有两个:
1: 基于halcon的训练网络,需要这中格式的文件。
2: 这样整合可以提高后续训练以及推理的速度。
小结
‘preprocess_dl_dataset’ 将单个的数据集字典,重新整合成,(一个字典 + 一群字典) 的形式。
输出只是一个目录,目录下是:一个字典 + 一群字典。
这篇关于【halcon深度学习之那些封装好的库函数】preprocess_dl_dataset的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





