本文主要是介绍sklearn中多种编码方式——category_encoders(one-hot多种用法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 Ordinal Encoding 序数编码
- 2 One-hot Encoding 独热编码
- 3 Target Encoding 目标编码
- 4 BinaryEncoder 编码
- 5 CatBoostEncoder编码
- 6 WOEEncoder编码
- 9 效果对比与使用心得
- 额外:10 用pandas的get_dummies进行one-hot
- 额外:11 文本one_hot的方式
离散型编码的Python库,里面封装了十几种(包括文中的所有方法)对于离散型特征的编码方法,接口接近于Sklearn通用接口,非常实用
可以使用多种不同的编码技术把类别变量转换为数值型变量,并且符合sklearn模式的转换。
- 官方github:https://github.com/scikit-learn-contrib/category_encoders
- 官方文档:http://contrib.scikit-learn.org/category_encoders/#
这个库的作者将类别编码分为两类,无监督和有监督(指用target)
Unsupervised:
Backward Difference Contrast
BaseN
Binary
Count
Hashing
Helmert Contrast
Ordinal
One-Hot
Polynomial Contrast
Sum Contrast
Supervised:
CatBoost
James-Stein Estimator
LeaveOneOut
M-estimator
Target Encoding
Weight of Evidence
无监督中有很大一部分是线性模型/回归模型用的对比编码,有监督主要是目标编码和WOE(Weight of Evidence)
利用标签进行特征编码是存在特征穿越的风险的,只不过很多时候影响并不大,不会出现极端的情况,利用标签进行特征编码例如target encoding、woe encoding或者是catboost encoding本质上都是利用类别和标签之间的某种统计特征来代替原始的类别,从而使得无法直接处理类别的模型可以在编码后的结果上正常运行。
woe编码的穿越问题
文章目录
- 1 Ordinal Encoding 序数编码
- 2 One-hot Encoding 独热编码
- 3 Target Encoding 目标编码
- 4 BinaryEncoder 编码
- 5 CatBoostEncoder编码
- 6 WOEEncoder编码
- 9 效果对比与使用心得
- 额外:10 用pandas的get_dummies进行one-hot
- 额外:11 文本one_hot的方式
1 Ordinal Encoding 序数编码
专栏 | 基于 Jupyter 的特征工程手册:数据预处理(二)
feature-engineering-handbook/中文版/
这个编码方式非常容易理解,就是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在[0, n-1]之间的整数。
这个编码的缺点在于它随机的给特征排序了,会给这个特征增加不存在的顺序关系,也就是增加了噪声。假设预测的目标是购买力,那么真实Label的排序显然是 女 > 狗狗 > 男,与我们编码后特征的顺序不存在相关性。
import numpy as np
import pandas as pd
from category_encoders import OrdinalEncoder
# category_encoders 直接支持dataframe# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10], ['female',20],['female',15]]),columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15], ['male',20],['female',40], ['male', 25]]),columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nanencoder = OrdinalEncoder(cols = ['Sex', 'Type'], handle_unknown = 'value', handle_missing = 'value').fit(train_set,train_y) # 在训练集上训练
# 将 handle_unknown设为‘value’,即测试集中的未知特征值将被标记为-1
# 将 handle_missing设为‘value’,即测试集中的缺失值将被标记为-2
# 其他的选择为:‘error’:即报错;‘return_nan’:即未知值/缺失之被标记为nan
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集# 以测试集结果为例
encoded_test# 在序数编码中:# 变量Sex中: 'male' => 1.0, 'female' => 2.0, 未知 => -1.0, 缺失值 => -2.0
# (事实上,测试集中完全有可能出现未知与缺失情况)
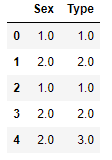
# 在我们的例子中, Sex这一变量中的'other' 类别从未在训练集中出现过# 变量 Type 中: 10 => 1.0, 20 => 2.0, 15 => 3.0, 未知 => -1.0, 缺失值 => -2.0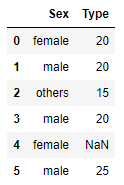
变成序列化:
2 One-hot Encoding 独热编码
专栏 | 基于 Jupyter 的特征工程手册:数据预处理(二)
feature-engineering-handbook/中文版/
大家熟知的OneHot方法就避免了对特征排序的缺点。对于一列有N种取值的特征,Onehot方法会创建出对应的N列特征,其中每列代表该样本是否为该特征的某一种取值。因为生成的每一列有值的都是1,所以这个方法起名为Onehot特征。Dummy特征也是一样,只是少了一列,因为第N列可以看做是前N-1列的线性组合。但是在离散特征的特征值过多的时候不宜使用,因为会导致生成特征的数量太多且过于稀疏。
Scikit-learn中也提供来独热编码函数,其可以将具有n_categories个可能值的一个分类特征转换为n_categories个二进制特征,其中一个为1,所有其他为0在category_encoders中,它包含了附加功能,即指示缺失或未知的值。在这里,我们继续使用category_encoders
import numpy as np
import pandas as pd
from category_encoders import OneHotEncoder
# category_encoders 直接支持dataframe# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10], ['female',20],['female',15]]),columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15], ['male',20],['female',40], ['male', 25]]),columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nanencoder = OneHotEncoder(cols=['Sex', 'Type'], handle_unknown='indicator', handle_missing='indicator', use_cat_names=True).fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# 将 handle_unknown设为‘indicator’,即会新增一列指示未知特征值
# 将 handle_missing设为‘indicator’,即会新增一列指示缺失值
# 其他的handle_unknown/handle_missing 的选择为:
# ‘error’:即报错; ‘return_nan’:即未知值/缺失之被标记为nan; ‘value’:即未知值/缺失之被标记为0# 以测试集结果为例
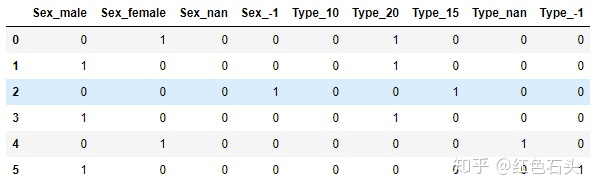
encoded_test# 在独热编码中:# 变量 Sex => 变为了4个新变量: 'male' => [1 ,0 ,0, 0];
# 'female' => [0 ,1 ,0, 0];
# 未知 => [0 ,0 ,0, 1];
# 缺失 => [0, 0, 1, 0];# 变量 Type => 变为了5个新变量: 10 => [1, 0, 0, 0, 0];
# 20 => [0, 1, 0, 0, 0];,
# 15 => [0, 0, 1, 0, 0];
# 未知 => [0, 0, 0, 0, 1];
# 缺失 => [0, 0, 0, 1, 0];
变成了:
3 Target Encoding 目标编码
专栏 | 基于 Jupyter 的特征工程手册:数据预处理(二)
feature-engineering-handbook/中文版/
目标编码是一种不仅基于特征值本身,还基于相应因变量的类别变量编码方法。对于分类问题:将类别特征替换为给定某一特定类别值的因变量后验概率与所有训练数据上因变量的先验概率的组合。对于连续目标:将类别特征替换为给定某一特定类别值的因变量目标期望值与所有训练数据上因变量的目标期望值的组合。该方法严重依赖于因变量的分布,但这大大减少了生成编码后特征的数量。
公式:
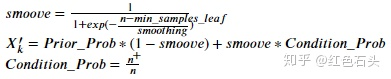
其中min_samples_leaf和smoothing是用户定义的参数;
min_samples_leaf:计算类别平均值时的最小样本数(即若该类别出现次数少,则将被忽略),用以控制过拟合;
smoothing:平衡分类平均值与先验平均值的平滑系数。其值越高,则正则化越强;
′ 是类别特征X中类别为k的编码值;
Prior Prob:目标变量的先验概率/期望;
n:类别特征X中,类别为k的样本数;
+:不仅在类别特征X中具有类别k,而且具有正结果的样本数(分类问题);
参考文献: Micci-Barreca, D. (2001). A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. ACM SIGKDD Explorations Newsletter, 3(1), 27-32.
import numpy as np
import pandas as pd
from category_encoders.target_encoder import TargetEncoder
# category_encoders 直接支持dataframe# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10], ['female',20],['female',15]]),columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15], ['male',20],['female',40], ['male', 25]]),columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nanencoder = TargetEncoder(cols=['Sex','Type'], handle_unknown='value', handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
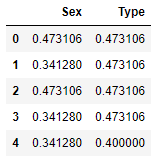
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值encoded_test # 编码后的变量数与原类别变量数一致

到了:
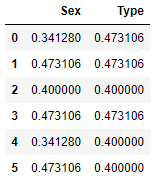
# 验证一下计算的结果,在测试集中,‘male’类别的编码值为 0.473106
prior = train_y.mean() # 先验概率
min_samples_leaf = 1.0 # 默认为1.0
smoothing = 1.0 # 默认为1.0
n = 2 # 训练集中,两个样本包含‘male’这个标签
n_positive = 1 # 在训练集中,这两个包含‘male’标签的样本中仅有一个有正的因变量标签= 1 / (1 + np.exp(-(n - min_samples_leaf) / smoothing))
male_encode = prior * (1- ) + * n_positive/n
male_encode # return 0.4731058578630005,与要验证的值吻合
0.4731058578630005
4 BinaryEncoder 编码
# 相关模块加载
import pandas as pd
import category_encoders as ce# 准备数据
df = pd.DataFrame({'ID':[1,2,3,4,5,6],'RATING':['G','B','G','B','B','G']})# 使用binary编码的方式来编码类别变量
encoder = ce.BinaryEncoder(cols=['RATING']).fit(df)# 转换数据
numeric_dataset = encoder.transform(df)df # 转换前的数据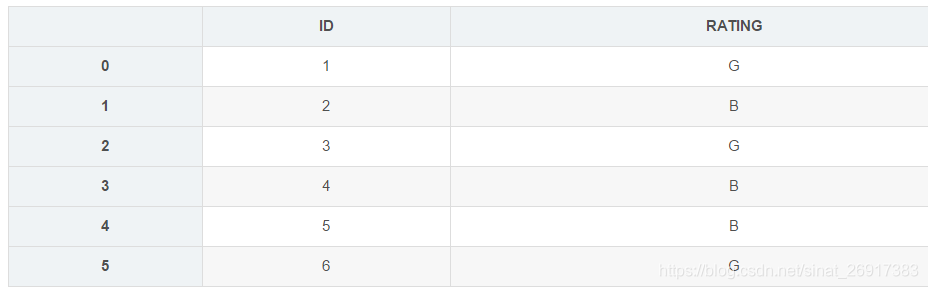
到:
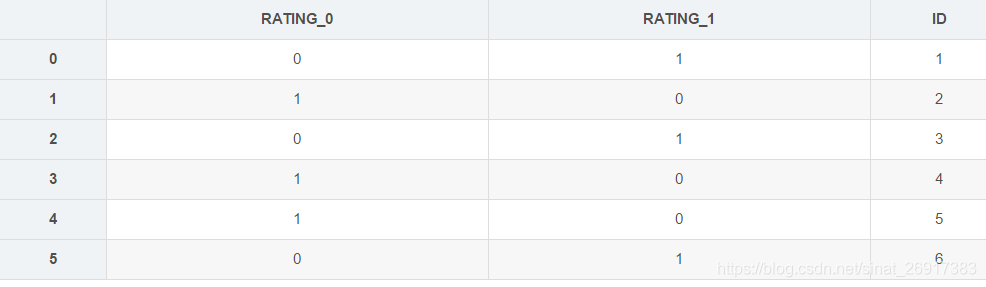
5 CatBoostEncoder编码
这个跟CatBoost一致,是Catboost中的encode方法,这个方法据说效果非常好,而且可以避免过拟合,可能有些复杂
import pandas as pd
import numpy as np
#from unittest import TestCase # or `from unittest import ...` if on Python 3.4+import category_encoders as encodersX = pd.DataFrame({'col1': ['A', 'B', 'B', 'C', 'A']})
y = pd.Series([1, 0, 1, 0, 1])
enc = encoders.CatBoostEncoder()
obtained = enc.fit_transform(X, y)
obtained# For testing set, use statistics calculated on all the training data.
# See: CatBoost: unbiased boosting with categorical features, page 4.
X_t = pd.DataFrame({'col1': ['B', 'B', 'A']})
obtained = enc.transform(X_t)
obtained
本来:
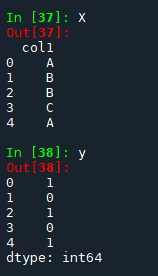
现在:
col1
0 0.6
1 0.6
2 0.3
3 0.6
4 0.8
其他案例(github):
X = pd.DataFrame({'col1': ['fuzzy', 'soft', 'smooth', 'fuzzy', 'smooth', 'soft', 'smooth', 'smooth']})
y = pd.Series([4, 1, 4, 3, 6, 0, 7, 5])
enc = encoders.CatBoostEncoder()
obtained = enc.fit_transform(X, y)
prior = 30./8
6 WOEEncoder编码
【数据建模 WOE编码】WOE(weight of evidence, 证据权重)
一种有监督的编码方式,将预测类别的集中度的属性作为编码的数值
- 优势
将特征的值规范到相近的尺度上。
(经验上讲,WOE的绝对值波动范围在0.1~3之间)。
具有业务含义。 - 缺点
需要每箱中同时包含好、坏两个类别。
当然也会出现标签穿越的问题:woe编码的穿越问题
X = ['a', 'a', 'b', 'b']
y = [1, 0, 0, 0]
enc = encoders.WOEEncoder()result = enc.fit_transform(X, y)
从:
(['a', 'a', 'b', 'b'], [1, 0, 0, 0])变成:0
0 0.510826
1 0.510826
2 -0.587787
3 -0.587787
案例二:
cols = ['unique_str', 'underscore', 'extra', 'none', 'invariant', 321, 'categorical', 'na_categorical', 'categorical_int']# balanced label with balanced features
X_balanced = pd.DataFrame(data=['1', '1', '1', '2', '2', '2'], columns=['col1'])
y_balanced = [True, False, True, False, True, False]
enc = encoders.WOEEncoder()
enc.fit(X_balanced, y_balanced)
X1 = enc.transform(X_balanced)
9 效果对比与使用心得
11种离散型变量编码方式及效果对比
语雀文档
数据集使用了八个存在离散型变量的数据集,最后的结果加权如下:
不使用交叉验证的情况:
HelmertEncoder 0.9517
SumEncoder 0.9434
FrequencyEncoder 0.9176
CatBoostEncoder 0.5728
TargetEncoder 0.5174
JamesSteinEncoder 0.5162
OrdinalEncoder 0.4964
WOEEncoder 0.4905
MEstimateEncoder 0.4501
BackwardDifferenceEncode0.4128
LeaveOneOutEncoder 0.0697
使用交叉验证的情况:
CatBoostEncoder 0.9726
OrdinalEncoder 0.9694
HelmertEncoder 0.9558
SumEncoder 0.9434
WOEEncoder 0.9326
FrequencyEncoder 0.9315
BackwardDifferenceEncode0.9108
TargetEncoder 0.8915
JamesSteinEncoder 0.8555
MEstimateEncoder 0.8189
LeaveOneOutEncoder 0.0729
下面是Kaggle上大佬们给出的一些建议,具体原因尚未分析,希望有大神在评论区可以给出解释。
对于无序的离散特征,实战中使用 OneHot, Hashing, LeaveOneOut, and Target encoding 方法效果较好,但是使用OneHot时要避免高基类别的特征以及基于决策树的模型,理由如下图所示。

但是在实战中,我发现使用Xgboost处理高维稀疏的问题效果并不会很差。例如在IJCAI-18商铺中用户定位比赛中,一个很好的baseline就是把高维稀疏的wifi信号向量直接当做特征放到Xgboost里面,也可以获得很好的预测结果。不知道是不是因为Xgboost对于稀疏特征的优化导致。
- 对于有序离散特征,尝试 Ordinal (Integer), Binary, OneHot, LeaveOneOut, and Target. Helmert, Sum, BackwardDifference and Polynomial 基本没啥用,但是当你有确切的原因或者对于业务的理解的话,可以进行尝试。
- 对于回归问题而言,Target 与 LeaveOneOut 方法可能不会有比较好的效果。
LeaveOneOut、 WeightOfEvidence、 James-Stein、M-estimator 适合用来处理高基数特征。Helmert、 Sum、 Backward Difference、 Polynomial 在机器学习问题里的效果往往不是很好(过拟合的原因)
额外:10 用pandas的get_dummies进行one-hot
参考:pandas.get_dummies 的用法
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
import pandas as pd
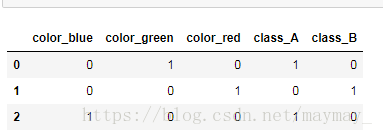
df = pd.DataFrame([ ['green' , 'A'], ['red' , 'B'], ['blue' , 'A']]) df.columns = ['color', 'class']
pd.get_dummies(df)
get_dummies 前:

get_dummies 后:
上述执行完以后再打印df 出来的还是get_dummies 前的图,因为你没有写
df = pd.get_dummies(df)
可以对指定列进行get_dummies
pd.get_dummies(df.color)
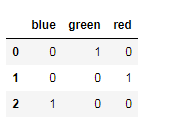
额外:11 文本one_hot的方式
from sklearn.feature_extraction.text import CountVectorizer
#from sklearn.feature_extraction.text import TfidfTransformer
import pandas as pddef text_one_hot(tag_list,prefix = ''):'''Parameters----------tag_list : TYPE常规分词,以空格隔开.[['格式','不一定'],['空格','隔开','常规']]prefix : TYPE, optional前缀. The default is ''.Returns-------data : TYPEdataframe,完整的TF的频次.'''vectorizer = CountVectorizer() #将文本中的词语转换为词频矩阵 X = vectorizer.fit_transform(tag_list) #计算个词语出现的次数data = pd.DataFrame(X.toarray(),columns = [prefix +'_'+ si for si in sorted(vectorizer.vocabulary_)])return datatag_list = ['青年 吃货', '少年 游戏 叛逆', '少年 吃货 足球'] data = text_one_hot(tag_list)返回的结果是:
_叛逆 _吃货 _少年 _游戏 _足球 _青年
0 0 1 0 0 0 1
1 1 0 1 1 0 0
2 0 1 1 0 1 0
这篇关于sklearn中多种编码方式——category_encoders(one-hot多种用法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





