本文主要是介绍知乎周源微信_每周源代码35-Zip压缩ASP.NET会话和缓存状态,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

知乎周源微信
Recently while talking to Jeff Atwood and his development team about StackOverflow he mentioned that he compresses the Cache or Session data in ASP.NET which enables him to store about 5-10x more data. They do it with some helper methods but I thought it'd be interesting to try it myself.
最近,在与Jeff Atwood及其开发团队讨论StackOverflow时,他提到他在ASP.NET中压缩了Cache或Session数据,这使他可以存储大约5-10倍的数据。 他们使用一些辅助方法来完成此操作,但我认为自己尝试一下会很有趣。
There's a lot of options and thoughts and quasi-requirements on how to pull this off:
关于如何实现这一目标,有很多选择,想法和准要求:
- I could create my own SessionStateModule, basically replacing the default Session state mechanism completely. 我可以创建自己的SessionStateModule,基本上完全替换默认的Session状态机制。
- I could create a number of extension methods to HttpSessionState. 我可以为HttpSessionState创建许多扩展方法。
I could just use helper methods, but that means I have to remember to use them on the in and the out and it doesn't feel like the way I'd use it day to day. However, the benefit to this approach is that it's very VERY simple and I can zip up whatever I want, whenever, and put it wherever.
我可以只使用辅助方法,但是这意味着我必须记住在和外出使用他们在和它不觉得喜欢的方式我会用它每一天。 但是,这种方法的好处是非常简单,我可以随时随地压缩任何内容,然后放在任何地方。
- I didn't want to accidentally put something in zipped and take it out unzipped. I want to avoid collisions. 我不想意外地将某些东西放进拉链,然后将其解压缩。 我想避免碰撞。
- I'm primarily concerned about storing strings (read: angle brackets), rather than binary serialization and compression of objects. 我主要关心的是存储字符串(阅读:尖括号),而不是二进制序列化和对象压缩。
I want to be able to put zipped stuff in the Session, Application and Cache. I realized that this was the primary requirement. I didn't realize it until I started writing code from the outside. Basically, TDD, using the non-existent library in real websites.
我希望能够将压缩后的内容放入会话,应用程序和缓存中。 我意识到这是主要要求。 直到我开始从外部编写代码时,我才意识到这一点。 基本上,TDD使用实际网站中不存在的库。
我的错误开始 (My False Start)
I initially thought I wanted it to look and work like this:
我最初以为我希望它看起来像这样工作:
Session.ZippedItems["foo"] = someLargeThing;
someLargeThing = Session.ZippedItems["foo"]; //string is impliedBut you can't do extension properties (rather than extension methods) or operator overloading.
但是您不能执行扩展属性(而不是扩展方法)或运算符重载。
Then I though I'd do it like this:
然后,尽管我会这样做:
public static class ZipSessionExtension
{
public static object GetZipItem(this HttpSessionState s, string key)
{
//go go go
}
}And have GetThis and SetThat all over...but that didn't feel right either.
到处都有GetThis和SetThat ...但是感觉也不对。
它应该如何工作 (How It Should Work)
So I ended up with this once I re-though the requirements. I realized I'd want it to work like this:
因此,一旦我重新考虑了要求,我就结束了。 我意识到我希望它像这样工作:
Session["foo"] = "Session: this is a test of the emergency broadcast system.";
Zip.Session["foo"] = "ZipSession this is a test of the emergency broadcast system.";
string zipsession = Zip.Session["foo"];
Cache["foo"] = "Cache: this is a test of the emergency broadcast system.";
Zip.Cache["foo"] = "ZipCache: this is a test of the emergency broadcast system.";
string zipfoo = Zip.Cache["foo"];Once I realized how it SHOULD work, I wrote it. There's a few interesting things I used and re-learned.
一旦我意识到它应该如何工作,我就写了它。 我使用并重新学习了一些有趣的东西。
I initially wanted the properties to be indexed properties and I wanted to be able to type "Zip." and get intellisense. I named the class Zip and made it static. There's two static properties name Session and Cache respectively. They each have an indexer, which makes Zip.Session[""] and Zip.Cache[""] work. I prepended the word "zip" to the front of the key in order to avoid collisions with uncompressed content, and to create the illusion there were two different places.
我最初希望该属性成为索引属性,并且希望能够键入“ Zip”。 并获得智慧。 我将类命名为Zip并使其变为静态。 有两个静态属性,分别为Session和Cache。 它们每个都有一个索引器,使Zip.Session [“”]和Zip.Cache [“”]工作。 为了避免与未压缩的内容发生冲突,我在键的前面加上了“ zip”一词,为了营造一种错觉,这里有两个不同的地方。
using System.IO;
using System.IO.Compression;
using System.Diagnostics;
using System.Web;
namespace HanselZip
{
public static class Zip
{
public static readonly ZipSessionInternal Session = new ZipSessionInternal();
public static readonly ZipCacheInternal Cache = new ZipCacheInternal();
public class ZipSessionInternal
{
public string this[string index]
{
get
{
return GZipHelpers.DeCompress(HttpContext.Current.Session["zip" + index] as byte[]);
}
set
{
HttpContext.Current.Session["zip" + index] = GZipHelpers.Compress(value);
}
}
}
public class ZipCacheInternal
{
public string this[string index]
{
get
{
return GZipHelpers.DeCompress(HttpContext.Current.Cache["zip" + index] as byte[]);
}
set
{
HttpContext.Current.Cache["zip" + index] = GZipHelpers.Compress(value);
}
}
}
public static class GZipHelpers
{
public static string DeCompress(byte[] unsquishMe)
{
using (MemoryStream mem = new MemoryStream(unsquishMe))
{
using (GZipStream gz = new GZipStream(mem, CompressionMode.Decompress))
{
var sr = new StreamReader(gz);
return sr.ReadToEnd();
}
}
}
public static byte[] Compress(string squishMe)
{
Trace.WriteLine("GZipHelper: Size In: " + squishMe.Length);
byte[] compressedBuffer = null;
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream zip = new GZipStream(stream, CompressionMode.Compress))
{
using (StreamWriter sw = new StreamWriter(zip))
{
sw.Write(squishMe);
}
//Dont get the MemoryStream data before the GZipStream is closed since it doesn’t yet contain complete compressed data.
//GZipStream writes additional data including footer information when its been disposed
}
compressedBuffer = stream.ToArray();
Trace.WriteLine("GZipHelper: Size Out:" + compressedBuffer.Length);
}
return compressedBuffer;
}
}
}
}Note that if the strings you put in are shorter than about 300 bytes, they will probably get LARGER. So, you'll probably only want to use these if have strings of more than a half K. More likely you'll use these if you have a few K or more. I figure these would be used for caching large chunks of HTML.
请注意,如果您输入的字符串短于大约300个字节,则它们可能会变得更大。 因此,如果字符串的长度大于K的一半,您可能只想使用它们。如果K的数量大于或等于K,则更有可能使用它们。 我认为这些将用于缓存大量HTML。
As an aside, I used Trace.WriteLine to show the size in and the size out. Then, in the web.config I added this trace listener to make sure my Trace output from my external assembly showed up in the ASP.NET Tracing:
顺便说一句,我使用了Trace.WriteLine来显示大小和大小。 然后,在web.config中,我添加了此跟踪侦听器,以确保来自外部程序集的跟踪输出显示在ASP.NET跟踪中:
<system.diagnostics>
<trace>
<listeners>
<add name="WebPageTraceListener"
type="System.Web.WebPageTraceListener, System.Web,
Version=2.0.3600.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a"/>
</listeners>
</trace>
</system.diagnostics>
<system.web>
<trace pageOutput="true" writeToDiagnosticsTrace="true" enabled="true"/>
...The resulting trace output is:
结果跟踪输出为:
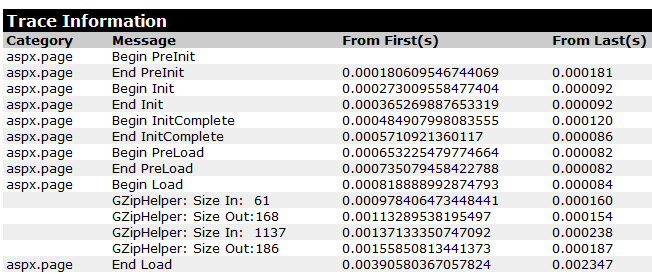
何时压缩 (When To Compress)
See how the first zipped string got bigger? I shouldn't have put it in there, it was initially too small. The second one went from 1137 bytes to 186, so that was reasonably useful. Again, IMHO, this probably won't matter unless you were storing thousands of strings in cache that were grater than 1k, but as you get towards 10k or more, I suspect you'd get some more value.
看看第一个压缩的弦如何变大? 我不应该把它放在那里,它最初太小了。 第二个从1137字节增加到186个字节,因此相当有用。 同样,恕我直言,除非您在缓存中存储数千个大于1k的字符串,否则这可能无关紧要,但是当您达到10k或更多时,我怀疑您会获得更多价值。
For example, if I put 17k of basic HTML in the cache, it squishes it 3756 bytes, a 78% savings. It all depends on how repetitive the markup is and how many visitors you have. If you had a thousand visitors on a machine simultaneously, and you were caching, say, 20 chunks of 100k each, times 1000 users, you'd use about 244 megs for your cache. When I was working in banking, we might have tens of thousands of users online at a time, and we'd be caching historical checking or savings data, and that data might get to 500k or more of XML. Four savings accounts * 70,000 users * 500k of XML history might be 16gigs of RAM (across many servers, so maybe a gig or half-gig per server.) Squishing that 500k to 70k would reduce the hit to 2gigs total. It all depends on how much you're storing, how much it'll compress (how repetitive it is) and how often it's accessed.
例如,如果我将17k基本HTML放入缓存中,它将压缩3756字节,节省了78%。 这完全取决于标记的重复性以及您拥有多少访问者。 如果您同时在一台机器上有一千个访问者,并且您要缓存20个块(每个100k,乘以1000个用户),则将使用约244兆作为缓存。 当我在银行工作时,我们一次可能有成千上万的用户在线,并且我们将缓存历史检查或储蓄数据,并且该数据可能达到500k或更多的XML。 四个储蓄帐户* 70,000个用户* 500,000个XML历史记录可能是16 gig的RAM(在许多服务器上,因此每个服务器可能是一个gig或半gig。)将500k减少到70k会将命中总数减少到2 gig。 这完全取决于您要存储多少,压缩多少(重复性如何)以及访问频率。
Memcached 2 includes a setCompressThreshold that lets you adjust the minimum savings you want before it'll compress. I suspect Velocity will have some similar setting.
Memcached 2包含一个setCompressThreshold,可让您调整压缩前所需的最低节省量。 我怀疑Velocity会有类似的设置。
Ultimately, however, this all means nothing unless you measure. For example, all this memory savings might be useless if the data is being read and written constantly. You'd be trading any savings from squishing for other potential problems like the memory you need hold the decompressed values as well as memory fragmentation. Point is, DON'T just turn this stuff on without measuring.
但是,最终,除非您进行测量,否则所有这些都没有任何意义。 例如,如果不断地读取和写入数据,那么所有这些内存节省都可能是无用的。 压缩其他潜在问题(例如需要保留解压缩后的值的内存以及内存碎片)可节省任何节省。 重点是,不要随便测量这些东西。
Nate Davis had a great comment on the StackOverflow show I wanted to share here:
Nate Davis对我想在这里分享的StackOverflow节目发表了很好的评论:
If they are caching final page output in this way and they are already sending HTTP responses across the wire as gzip,
then gzipping the output cache would make great sense. But only if they are NOT first unzipping when taking the page out of cache and then re-zipping it up again before sending the response.
If they check the 'Accept-Encoding' header to make sure gzip is supported, then they can just send the gzipped output cache directly into the response stream and set the Encoding header with 'gzip'. If Accept-Encoding doesn't include gzip, then the cache would have to be unzipped, but this is a very small percentage of browsers.如果他们以这种方式缓存最终页面输出,并且已经以gzip的形式通过网络发送了HTTP响应, 那么gziping输出缓存将非常有意义。 但是,只有在将页面从缓存中移出时,他们没有首先解压缩,然后在发送响应之前再次将其重新压缩时,才行。 如果他们检查“ Accept-Encoding”标头以确保支持gzip,则他们可以将gzip压缩的输出缓存直接发送到响应流中,并用“ gzip”设置Encoding标头。 如果Accept-Encoding不包含gzip,则必须解压缩缓存,但这只是很小一部分的浏览器。
Nate is pointing out that one should think about HOW this data will be used. Are you caching and entire page or iFrame? If so, you might be able to send it right back out, still compressed to the browser.
Nate指出,应该考虑如何使用这些数据。 您要缓存整个页面还是iFrame? 如果是这样,您可以直接将其发送回,但仍压缩到浏览器中。
However, if you've got IIS7 and you want to cache a whole page rather than just a per user fragment, consider using IIS7's Dynamic Compression. You've already got this feature, and along with ASP.NET's OutputCaching, the system already knows about gzip compression. It'll store the gzipp'ed version and serve it directly.
但是,如果您拥有IIS7,并且想要缓存整个页面而不是每个用户片段,请考虑使用IIS7的Dynamic Compression 。 您已经具有此功能,并且与ASP.NET的OutputCaching一起,系统已经了解gzip压缩。 它将存储gzipp版本并直接提供。
我的结论? (My Conclusion?)
- I might use something like this if I was storing large string fragments in a memory constrained situation. 如果我在内存受限的情况下存储大型字符串片段,则可能会使用类似的内容。
- I always turn compression on at the Web Server level. It's solving a different problem, but there's really NO reason for your web server to be serving uncompressed content. It's wasteful not to turn it on. 我总是在Web服务器级别打开压缩功能。 它正在解决一个不同的问题,但实际上没有理由让您的Web服务器提供未压缩的内容。 不打开它很浪费。
Thoughts? What is this missing? Useful? Not useful?
有什么想法吗? 这缺少什么? 有用? 没用?
翻译自: https://www.hanselman.com/blog/the-weekly-source-code-35-zip-compressing-aspnet-session-and-cache-state
知乎周源微信
这篇关于知乎周源微信_每周源代码35-Zip压缩ASP.NET会话和缓存状态的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



