本文主要是介绍spark源码之RDD(1)partition、dependence、persist,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
An Architecture for Fast and General Data Processing on Large Clusters
1 编程模型
1.1 RDD
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
RDD就是只读的数据分区集合。
RDD上的有两种Operation:transformantion和action。
Transformation
数据集中的内容会发生更改,会产生新数据集;
该操作只有在action时才会真正执行,否则只是记住该操作。
Action
数据集中的内容会被归约为一个具体的数值。
1.2 spark组件
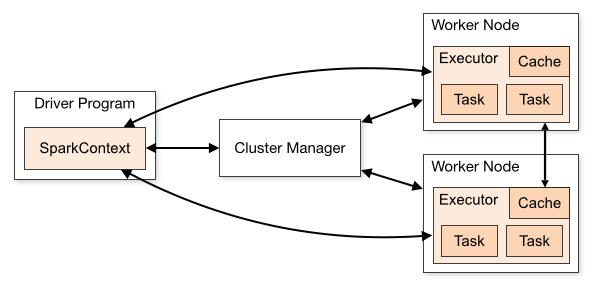
sparkContext对象是整个应用程序的入口,称之为driver program。而cluster manager则是集群资源管理器,典型的有hadoop、yarn以及meros,由他分配各种所需要的资源。worker node上对应的executor相当于独立地进程,进行分布式的计算或者数据存储功能。sparkcontext将应用程序代码分发到executor,最后将task分配给executor执行。
可以理解其中worker相当于进程,task相当于线程。
部署
当有action作用于RDD时,该action会作为一个job被提交。
在提交的过程中,DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG。
每一个job又分为多个stage,每一个stage中可以包含多个rdd及其transformation。
当stage被提交之后,由taskscheduler来根据stage来计算所需要的task,并将task提交到对应的worker。
2 RDD分析
2.1 RDD接口
partition集合,一个RDD中有多少data partition
dependencies——RDD依赖关系
compute(parition)——对于给定的数据集,需要作哪些计算
preferredLocations——对于data partition的位置偏好
partitioner——对于计算出来的数据结果如何分发(可选)
2.2 抽象类RDD
abstract class RDD[T: ClassTag](//ClassTag只包含了运行时给定的类的类别信息。而TypeTag不仅包含类的类别信息,还包含了所有静态的类信息@transient private var _sc: SparkContext,//序列化时该属性不存储@transient private var deps: Seq[Dependency[_]]) extends Serializable with Logging {//RDD必须是Serializable if (classOf[RDD[_]].isAssignableFrom(elementClassTag.runtimeClass)) {//getClass 方法得到的是 Class[A]的某个子类,而 classOf[A] 得到是正确的 Class[A]logWarning("Spark does not support nested RDDs (see SPARK-5063)")//仅仅是警告,定义了嵌套RDDs}构造RDD,该新建的RDD 对oneparent是点对点的窄依赖
def this(@transient oneParent: RDD[_]) =this(oneParent.context, List(new OneToOneDependency(oneParent)))几个纯虚函数,需要子类自己实现:
#给定partition进行计算,返回迭代器
def compute(split: Partition, context: TaskContext): Iterator[T] #该方法返回多个partition组成的数组,仅调用一次
protected def getPartitions: Array[Partition]#返回依赖关系,仅调用一次##Set是集合,不含重复元素,元素顺序不定。Seq是序列,元素有插入的先后顺序,可以有重复的元素protected def getDependencies: Seq[Dependency[_]] = deps#返回partition的首选位置,输入参数是split分片,输出结果是一组优先的节点位置,不是必须实现的
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
this.type:
这样当RDD.setName()之后仍然返回RDD。
就可以RDD.setName().xx()这样的操作了。
def setName(_name: String): this.type = {name = _namethis}同时每个RDD都有个基于sparkcontext的id
val id: Int = sc.newRddId()2.3 persist
persist最大作用还是将RDD保持在内存中,避免频繁读取,更高效
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {throw new UnsupportedOperationException("Cannot change storage level of an RDD after it was already assigned a level")}//首次persist,将会注册if (storageLevel == StorageLevel.NONE) {sc.cleaner.foreach(_.registerRDDForCleanup(this))sc.persistRDD(this)}storageLevel = newLevelthis}def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)#默认的模式是memory_only。def cache(): this.type = persist()#cache方法等价于StorageLevel.MEMORY_ONLY的persist方法#解锁姿势def unpersist(blocking: Boolean = true): this.type = {logInfo("Removing RDD " + id + " from persistence list")sc.unpersistRDD(id, blocking)storageLevel = StorageLevel.NONEthis}最终转至persistRDD:
实质就是用RDD的id作为key搞得hash表
private[spark] def persistRDD(rdd: RDD[_]) {persistentRdds(rdd.id) = rdd}
...private[spark] val persistentRdds = {val map: ConcurrentMap[Int, RDD[_]] = new MapMaker().weakValues().makeMap[Int, RDD[_]]()map.asScala}有一个疑问???如果persist的时候内存不够,怎么办??
当然是转进到磁盘咯。。。。。
最后从内存中去掉持久化也就是从hash表中根据RDD的id把他去掉
private[spark] def unpersistRDD(rddId: Int, blocking: Boolean = true) {env.blockManager.master.removeRdd(rddId, blocking)persistentRdds.remove(rddId)listenerBus.post(SparkListenerUnpersistRDD(rddId))}2.4 partitions
RDD本质是只读的分区记录集合。一个RDD是由若干个的partitions组成的。
@transient private var partitions_ : Array[Partition] = null如果已经被checkpoint过,那么就可以直接从本地缓存取出来,否则调用getPartitions在计算一次
返回的是由partitions组成的数组
final def partitions: Array[Partition] = {checkpointRDD.map(_.partitions).getOrElse {if (partitions_ == null) {partitions_ = getPartitionspartitions_.zipWithIndex.foreach { case (partition, index) =>require(partition.index == index,s"partitions($index).partition == ${partition.index}, but it should equal $index")}}partitions_}}
2.5 dependencies
dependencies_是一个保存依赖关系的序列
private var dependencies_ : Seq[Dependency[_]] = null
依赖分为两大类:窄依赖,宽依赖
窄依赖:
partitionId:子RDD中的一个分区的编号
return 子RDD的一个分区对应的父RDD的那些分区
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {//返回子RDD的partitionId依赖的所有的parent RDD的Partition(s)def getParents(partitionId: Int): Seq[Int]override def rdd: RDD[T] = _rdd
}一对一的依赖:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int) = List(partitionId)#RDD仅仅依赖于parent RDD相同ID的Partition可以看出窄依赖就是RDD的每个分区最多只能被一个子RDD的一个分区使用
宽依赖则是子RDD的每个分区依赖于所有父RDD分区。
借图解释一下:
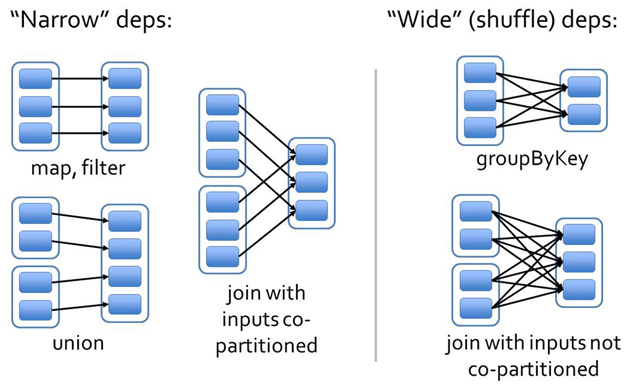
First, narrow dependencies allow for pipelined execution on one cluster
node, which can compute all the parent partitions. For example, one can apply a map followed by a filter on an element-by-element basis.
窄依赖允许流水线式对每个元素进行transformation和action。
wide dependencies require data from all parent partitions to be available and to be shuffled across the nodes using a MapReducelike operation.
宽依赖必须所有的父分区首先进行计算,再在节点之间进行shuffle。
Second, recovery after a node failure is more efficient with a narrow dependency, as only the lost parent partitions need to be recomputed, and they can be recomputed in parallel on different nodes. In contrast, in a lineage graph with wide dependencies, a single failed node might cause the loss of some partition from all the ancestors of an RDD, requiring a complete re-execution.
如果某个节点计算失败了,窄依赖只需要重新计算父分区,而且多个节点可以并行计算。
但是宽依赖中单个节点计算失败了,可能导致所有父RDD丢失某些分区,需要完完全全重新计算。这就是很蛋疼了。
举例:RDD的MAP方法
map输入一个转换函数
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))}转到MapPartitionsRDD:
传入一个映射函数得到一个新的RDD,新的RDD是对旧RDD的窄依赖
划分直接沿用旧的RDD
compute之后得到新的RDD
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](var prev: RDD[T],f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)preservesPartitioning: Boolean = false)extends RDD[U](prev) {override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else Noneoverride def getPartitions: Array[Partition] = firstParent[T].partitions//getPartitions直接沿用了父RDD的分片信息override def compute(split: Partition, context: TaskContext): Iterator[U] =f(context, split.index, firstParent[T].iterator(split, context))//terator方法会返回一个迭代器对象,迭代器内部存储的每一个元素即父RDD对应分区内的数据记录。override def clearDependencies() {super.clearDependencies()prev = null}
}RDD的每个Partition,仅仅依赖于父RDD中的一个Partition
firstParent[T]返回依赖序列中的第一个依赖:
protected[spark] def firstParent[U: ClassTag]: RDD[U] = {dependencies.head.rdd.asInstanceOf[RDD[U]]}而compute的最终实现是基于iterator的方法:
需要先检查RDD是否已经有persist操作
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {if (storageLevel != StorageLevel.NONE) {getOrCompute(split, context)} else {computeOrReadCheckpoint(split, context)}}转入getOrCompute:
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
#//通过RDD的id和分区的编号得到block的编号val blockId = RDDBlockId(id, partition.index)var readCachedBlock = true#// 该方法在executor中执行,需要SparkEnv#// 如果 Block 在 BlockManager 中存在, 就会从 BlockManager 中获取,如果不存在, 就进行计算这个Block, 然后在 BlockManager 中进行存储持久化, 方便下次使用。SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {readCachedBlock = falsecomputeOrReadCheckpoint(partition, context)}) match {case Left(blockResult) =>if (readCachedBlock) {val existingMetrics = context.taskMetrics().inputMetricsexistingMetrics.incBytesRead(blockResult.bytes)new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {override def next(): T = {existingMetrics.incRecordsRead(1)delegate.next()}}} else {new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])}case Right(iter) =>new InterruptibleIterator(context, iter.asInstanceOf[Iterator[T]])}}其中出现了sparkEnv中的一个blockManager:
BlockManager 是一个嵌入在 spark 中的 key-value型分布式存储系统,是为 spark 的关键组件,起到缓存的功能。
这篇关于spark源码之RDD(1)partition、dependence、persist的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







