本文主要是介绍爬虫学习(01):了解爬虫超文本传输协议的理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 一、爬虫入门
- 二、web请求过程(百度为例)
- 2.1 页面渲染
- 1. 服务器渲染 -> 数据直接在页面源代码里能搜到
- 2. 前端JS渲染 -> 数据在页面源代码里搜不到
- 三、浏览器工具的使用(重点)
- 1. Elements
- 2. Console
- 3. Source
- 4. Network
- 四、超文本传输协议
- 请求:
- 响应:
- https协议
- 加密方法(三种)
- 1. 对称密钥加密
- 2. 非对称密钥加密
- 3. 证书密钥加密
- 五、总结
一、爬虫入门
- 什么是爬虫?
-
就是我们总是希望能够保存互联网上的一些重要的数据信息
为己所用.
比如:- 在浏览到一些优秀的让人血脉喷张的图片时. 总想保存起来留为日后做桌面上的壁纸
- 在浏览到一些重要的数据时(各行各业), 希望保留下来日后为自己进行各种销售行为增光添彩
- 在浏览到一些奇奇怪怪的劲爆视频时, 希望保存在硬盘里供日后慢慢品鉴
- 在浏览到一些十分优秀的歌声曲目时, 希望保存下来供我们在烦闷的生活中增添一份精彩
需要注意的是:爬取的一定是
能看见的东西,公开的一些东西. 爬虫的矛与盾 -
反爬机制:- 门户网站,可以通过制定相应的
策略或者技术手段(加密),防止爬虫程序进行网站数据的爬取。
- 门户网站,可以通过制定相应的
-
反反爬策略(JS逆向):- 爬虫程序可以通过制定相关的
策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
robots.txt协议:百度蜘蛛 - 爬虫程序可以通过制定相关的
-
俗称
君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。只要在每个网站后缀加robots.txt就好了
这是淘宝网站的君子协议
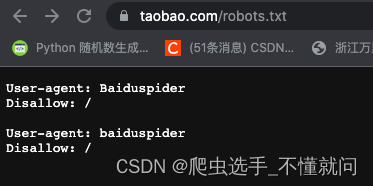
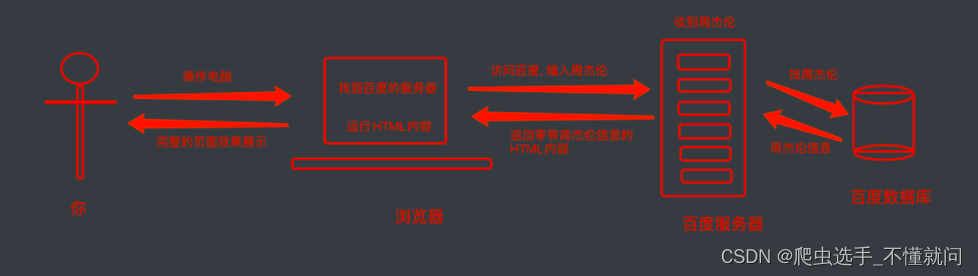
二、web请求过程(百度为例)
在访问百度的时候, 浏览器会把这一次请求发送到百度的服务器(百度的一台电脑), 由服务器接收到这个请求, 然后加载一些数据. 返回给浏览器, 再由浏览器进行显示. 需要注意的是, 百度的服务器返回给浏览器的不直接是页面, 而是页面源代码(由html, css, js组成). 由浏览器把页面源代码进行执行, 然后把执行之后的结果展示给用户. 所以我们能看到百度的源代码(就是那堆看不懂的鬼东西). 具体过程如图.
2.1 页面渲染
这里需要注意的是,不是所有的数据都是在页面源代码上的,有些是通过js等工具动态加载进来的,这就是页面渲染数据的过程, 我们常见的页面渲染过程有两种,一种叫做服务器渲染,另外一种叫做前端JS渲染
1. 服务器渲染 -> 数据直接在页面源代码里能搜到
我们在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容.
由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的.
这种网页一般都相对比较容易就能抓取到页面内容
2. 前端JS渲染 -> 数据在页面源代码里搜不到
这种就稍显麻烦了. 这种机制一般是第一次请求服务器返回一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载. 就像这样:
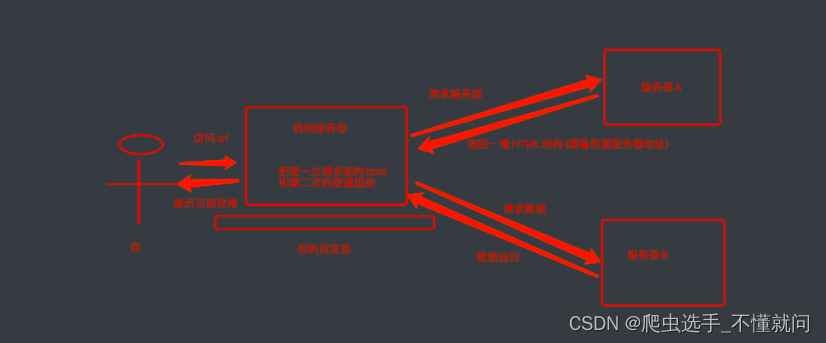
那数据是何时加载进来的呢? 其实就是在我们进行页面向下滚动的时候, jd就在偷偷的加载数据了, 此时想要看到这个页面的加载全过程, 我们就需要借助浏览器的调试工具了(F12)
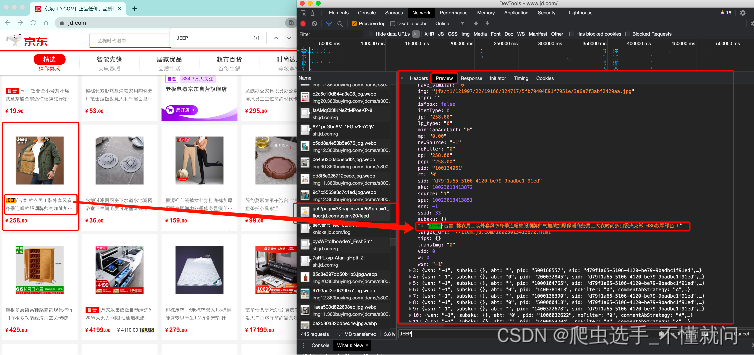
所以当你在页面源代码中找不到页面显示出来的数据的时候,可以在调试工具(F12)中寻找左侧相关的数据包,数据就藏在数据包里(记得先打开F12调试工具,再刷新页面,不然数据已经加载完毕,则数据包中没有内容)
三、浏览器工具的使用(重点)
浏览器是最能直观的看到网页情况以及网页加载内容的地方. 我们可以按下F12来查看一些普通用户很少能使用到的工具.
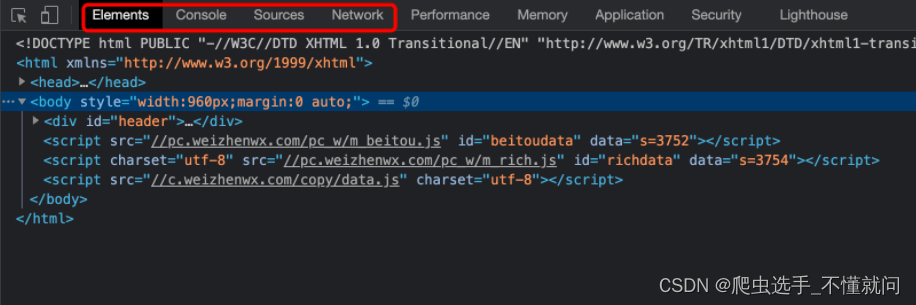
其中, 最重要的Elements, Console, Sources, Network前四个
1. Elements
Elements是我们实时的网页内容情况,有时候并不是页面源代码,前端JS渲染的内容也会在这上面呈现。所以这个是实时的网页内容情况
注意,
页面源代码是执行js脚本以及用户操作之前的服务器返回给我们最原始的内容Elements中看到的内容是js脚本以及用户操作之后的当时的页面显示效果.
你可以理解为, 一个是老师批改之前的卷子,一个是老师批改之后的卷子. 虽然都是卷子. 但是内容是不一样的. 而我们目前能够拿到的都是页面源代码. 也就是老师批改之前的样子. 这一点要格外注意.
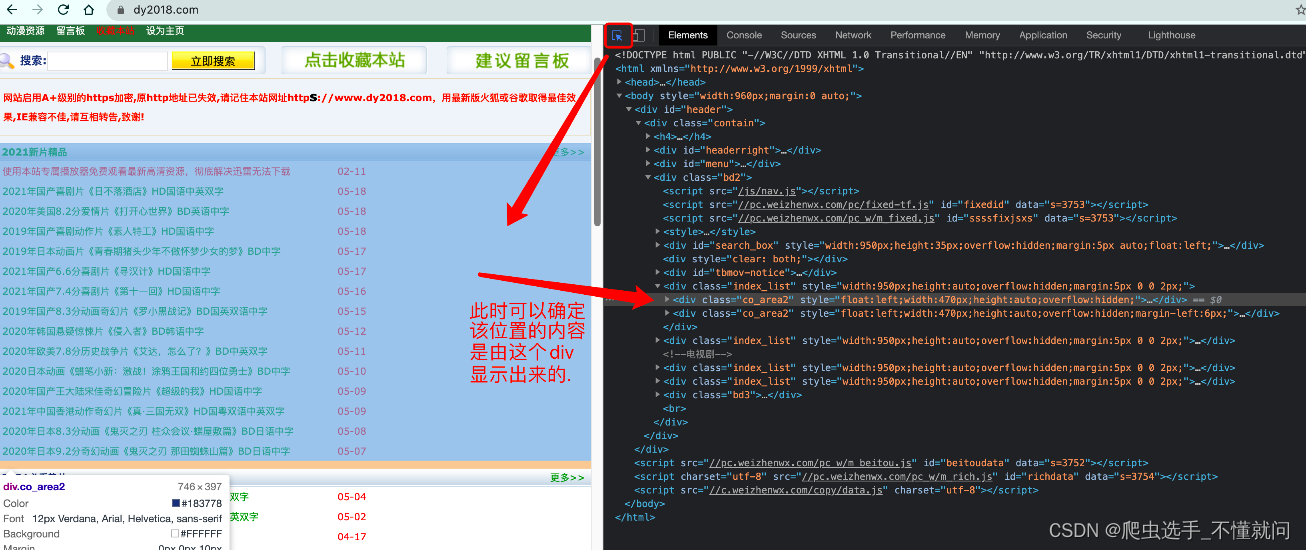
在Elements中我们可以使用左上角的小箭头.可以直观的看到浏览器中每一块位置对应的当前html状况. 还是很贴心的.
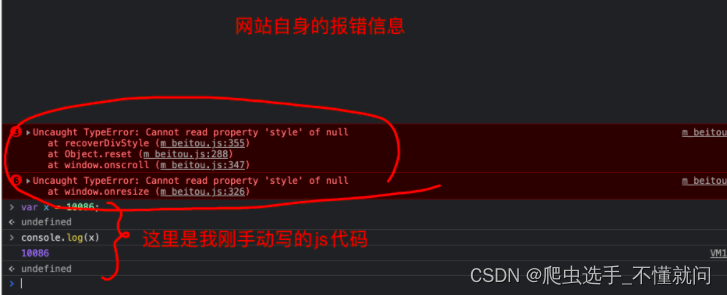
2. Console
第二个窗口, Console是用来查看程序员留下的一些打印内容, 以及日志内容的. 我们可以在这里输入一些js代码自动执行.
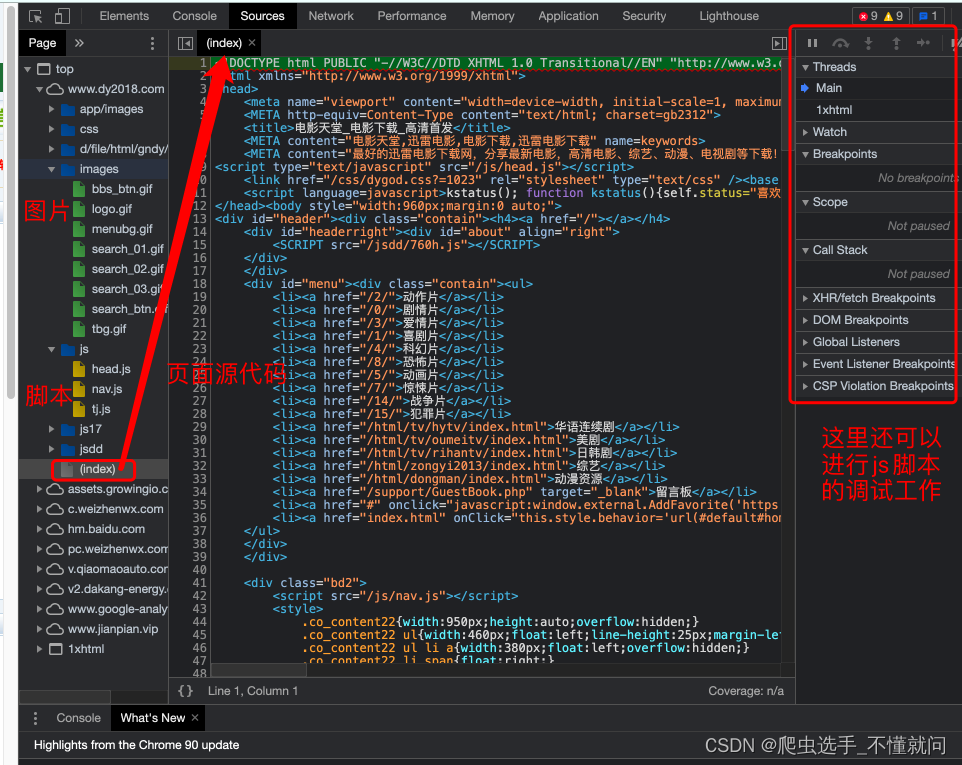
3. Source
第三个窗口, Source, 这里能看到该网页打开时加载的所有内容. 包括页面源代码. 脚本. 样式, 图片等等全部内容.
4. Network
第四个窗口, Network, 我们一般习惯称呼它为抓包工具. 就是刚才讲的前端JS渲染就是在这里看到的, 我们能看到当前网页加载的所有网络请求, 以及请求的详细内容. 这一点对我们爬虫来说至关重要.
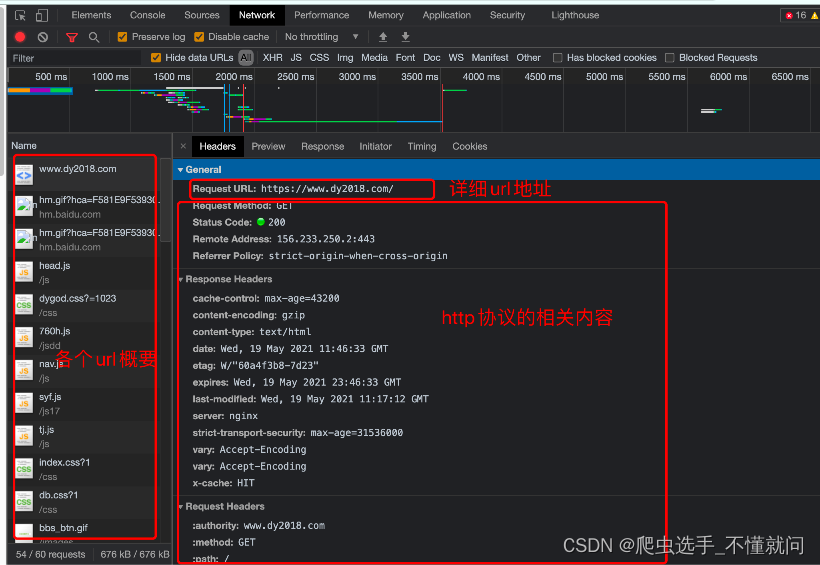
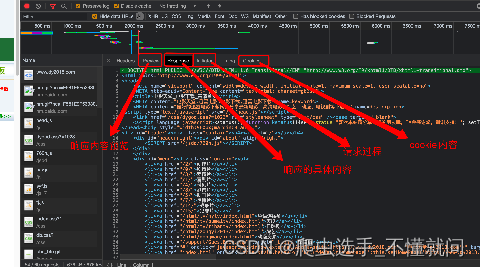
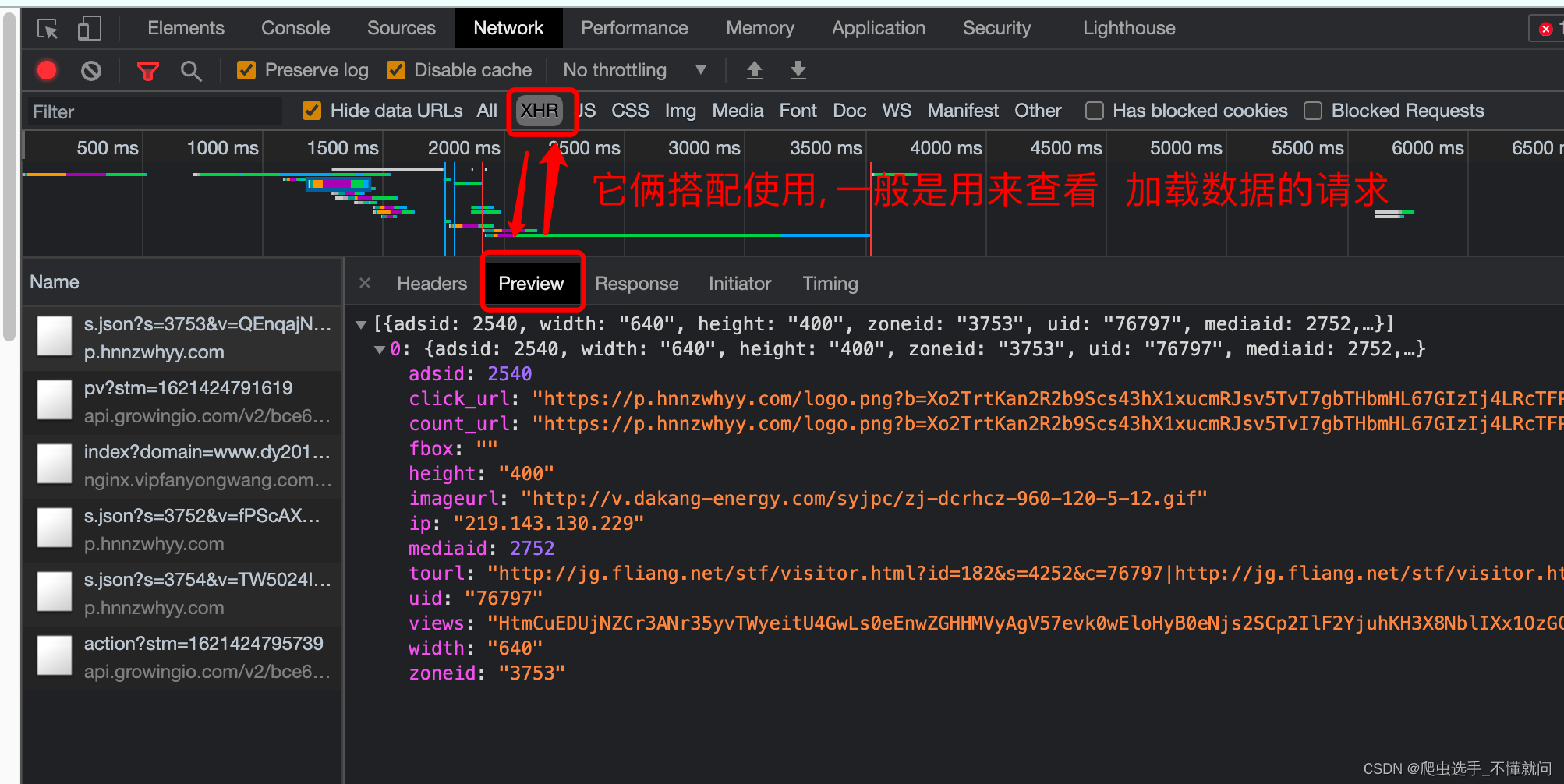
四、超文本传输协议
协议: 就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定. 常见的协议有TCP/IP. SOAP协议, HTTP协议, SMTP协议等等…
不同的协议. 传输的数据格式不一样.
HTTP协议, Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议. 直白点儿, 就是浏览器和服务器之间的数据交互遵守的就是HTTP协议.
HTTP协议用的最多的是加载网页.
HTTP协议把一条消息分为三大块内容. 无论是请求还是响应都是三块内容
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息(cookie验证,token,各式各样的反扒信息)请求体 -> 一般放一些请求参数
响应:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的一些附加信息(cookie验证,token,各式各样的反扒信息)响应体 -> 服务器返回的真正客户端要用的内容(HTML,json)等 页面代码
在写爬虫的时候要格外注意请求头和响应头. 这两个地方一般都隐含着一些比较重要的内容
注意, 浏览器实际上把 HTTP的请求和响应的内容进行重组了. 显示成我们更容易阅读的效果.
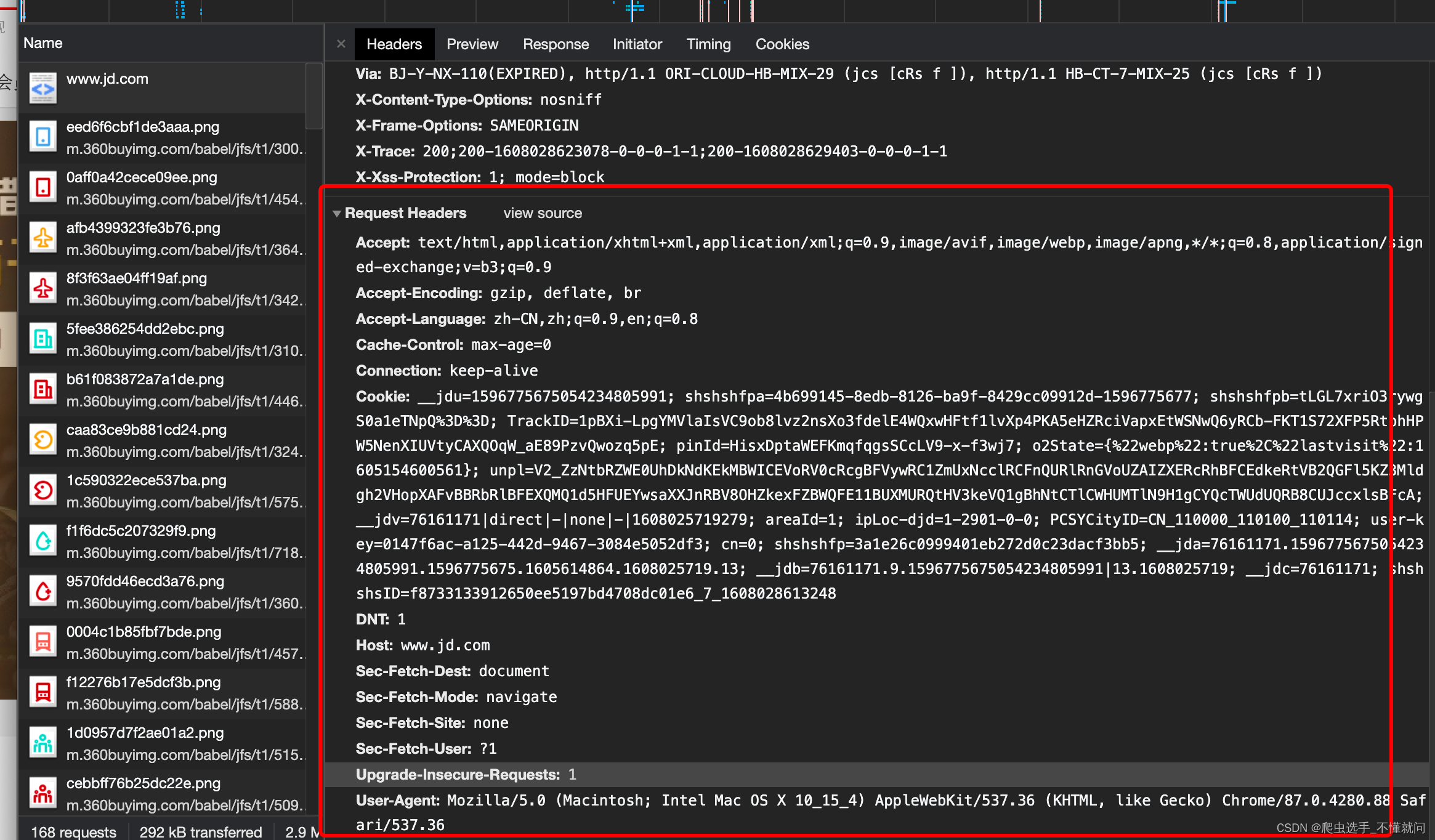
请求头中最常见的一些重要内容(爬虫需要):
User-Agent: 请求载体的身份标识(用啥发送的请求)Referer:防盗链(这次请求是从哪个页面来的? 反爬会用到)cookie: 本地字符串数据信息(用户登录信息, 反爬的token)Content-Type:服务器响应回客户端的数据类型(str,json等类型)
响应头中一些重要的内容:
- cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
- 各种神奇的
莫名其妙的字符串(这个需要经验了, 一般都是token字样, 防止各种攻击和反爬)
https协议
与http协议几乎相同,s表示安全,表示安全的超文本传输协议。(数据加密)
加密方法(三种)
1. 对称密钥加密
指客户端会先将即将发送给服务器端的数据进行数据加密,加密的方式是由客户端自己指定的,加密完毕之后,将密文包括解密的方式(密钥)一块发送给服务器端,服务器端接收到了密钥和加密的密文数据之后,会使用密钥将密文数据进行解密,最后服务器端会获得原文数据。
- 弊端
-
- 在进行密钥和密文
数据传输的过程中,很有可能会被第三方机构拦截到,可能存在数据暴露的风险。
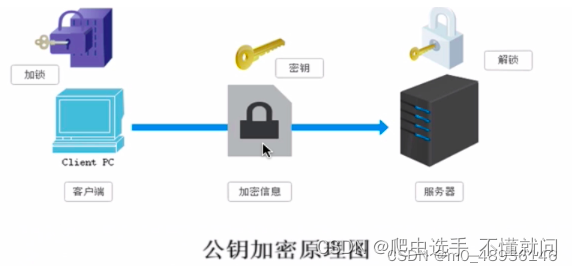
- 在进行密钥和密文
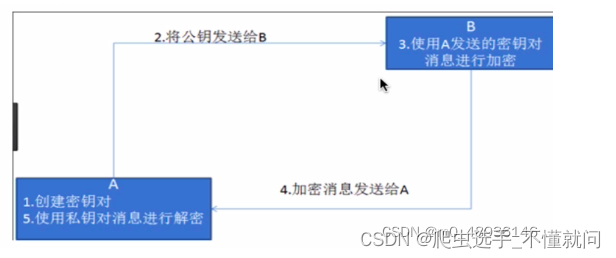
2. 非对称密钥加密
针对对称加密的安全隐患,进行改良的加密方法,在使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接收到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举能做到的事。
- 缺点:
-
- 1.
效率比较低,处理起来更加复杂,通信过程中使用就有一定的效率问题而影响通信速度。 - 2.只要是发送密钥,就有可能有被挟持的风险,如果中间机构将
公钥篡改,再发送给客户端,这样就不能保证客户端拿到的公钥一定是由服务器所创建的。
- 1.
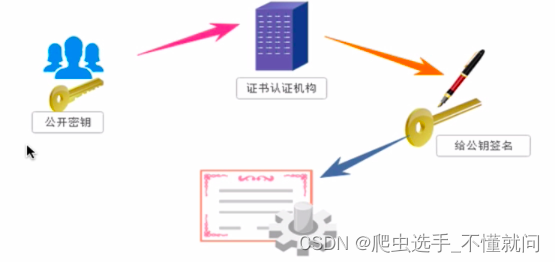
3. 证书密钥加密
针对非对称密钥加密的缺陷,我们没法保证客户端所拿到的公钥一定是由服务器端所创建的,引入证书密钥加密。
服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已经签名的公开密钥,并将密钥放在证书里面,绑定在一起。
服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
五、总结
- 你要的东西在页面源代码. 直接拿
源代码提取数据即可 - 你要的东西,不在页面源代码, 需要想办法找到真正的加载数据的那个请求. 然后提取数据
- 注意遵守
君子协定 - 请求头中常见的内容:
User-Agent,referer,cookie,Content-Type
这篇关于爬虫学习(01):了解爬虫超文本传输协议的理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





