本文主要是介绍Autosar DEM DTC的Debounce策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 简介
- Debounce策略
- 1、基于计数器的 Debounce 策略
- 2、基于时间的Debounce策略
简介
故障事件防抖,与按键防抖(软件需要延时确认按键不是误触发)的作用类似,目的是为了防止事件误触发采取的策略。
因为DTC并不是一达到触发位就会被报出来的,而是要对故障进行Debounce(消抖),防止故障误报。
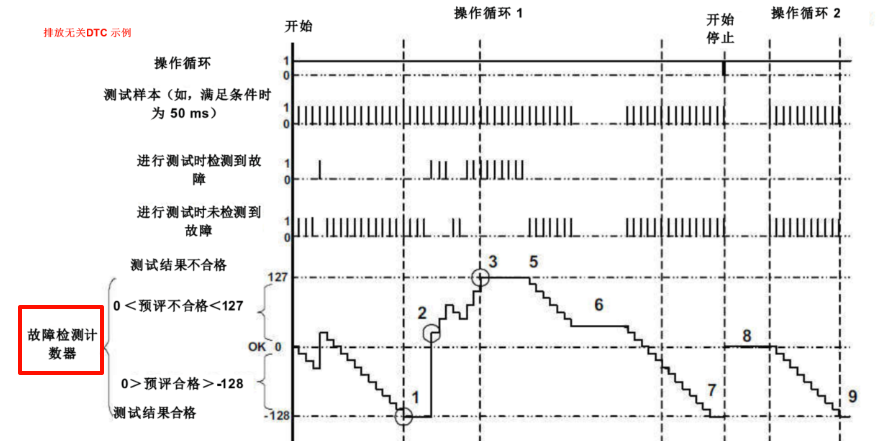
Debounce策略
故障诊断是由Dem模块和SWC共同完成的,SWC中的Monitor Function对故障条件进行实时监控,并实时将故障条件的判定结果反馈至Dem模块判断是否发生故障
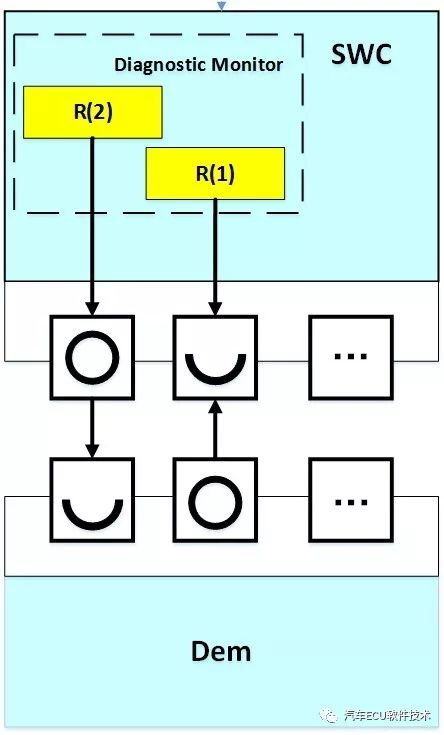
故障诊断由SWC与Dem模块共同完成的,故故障的debounce策略即可在SWC中实现,也可在Dem模块中实现。
如果在SWC中,Dem_SetEventStatus()函数传给Dem的状态为 passed 或 failed ,如果在Dem,Dem_SetEventStatus()函数传给Dem的状态为 prepassed 或 prefailed。
Dem中提供了两种debounce策略,分别为基于计数器的debounce策略和基于时间的debounce策略。
1、基于计数器的 Debounce 策略
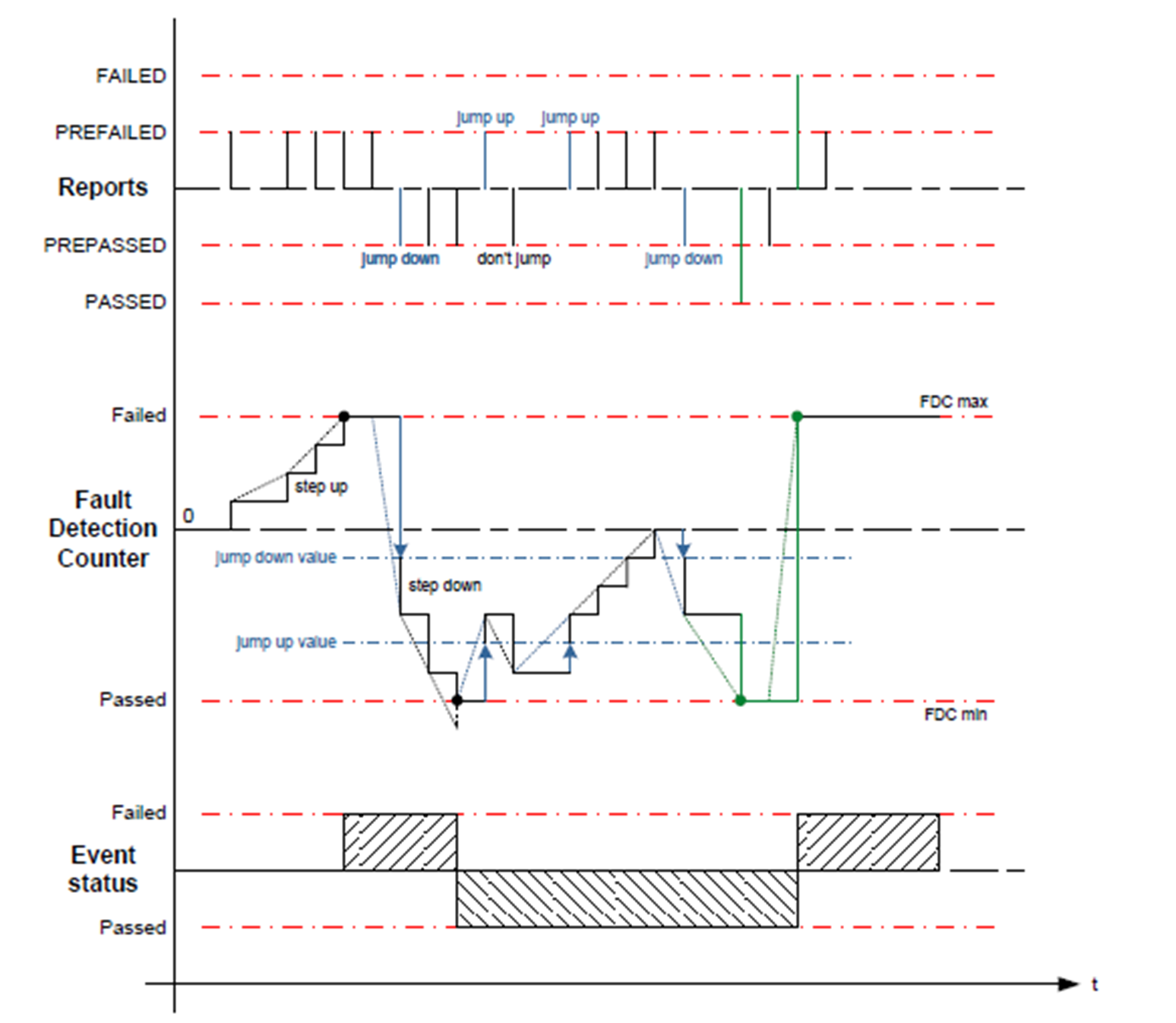
在这种策略下,Dem会提供一个计数器(fault detection counter)用来记录判断的结果,当Diagnostic Monitor上报至dem的状态为prefailed,计数器会按步长增加,当达到设定的限值时,故障状态变成failed。当上报状态为prepassed,计数器按步长减少,当达到设定的限值时,故障状态变成passed。
以下对改策略涉及的重要参数进行解释:
-
1、FDC(fault detection counter):错误计数器,其范围为-128~127;
-
2、DemDebounceCounterFailedThreshold:故障从prefailed状态跳转至failed的限值;
-
3、DemDebounceCounterPassedThreshold:故障从prepassed状态跳转至passed状态的限值;
-
4、DemDebounceCounterIncrementStepSize:当DiagnosticMonitor上报Prefailed,错误计数器的增加量;
-
5、DemDebounceCounterDecrementStepSize:当DiagnosticMonitor上报Prepassed,错误计数器减少量;
-
6、DemDebounceCounterJumpDown:是否使能JumpDown功能。JumpDown功能是指当上一次Diagnostic Monitor上报的状态是prefailed,而当前上报的是prepassed,且当前计数器的值大于DemDebounceCounterJumpDownValue,错误计数器的值会重置为DemDebounceCounterJumpDownValue,然后再按步长减少。如果JumpDown功能禁止,计数器按步长减少;
-
7、DemDebounceCounterJumpDownValue:当JumpDown功能使能,该变量定义了计数器的重置值;
-
8、DemDebounceCounterJumpUp:是否使能JumpUp功能。JumpUp功能是指当上一次Diagnostic Monitor上报的状态是prepassed,而这次上报的是prefailed,且当前计数器的值小于DemDebounceCounterJumpUpValue,错误计数器的值会重置为DemDebounceCounterJumpUpValue,然后再按步长增加。如果JumpUp功能禁止,计数器按步长增加;
-
9、DemDebounceCounterJumpUpValue:当JumpUp功能使能,该变量定义了计数器的重置值;
-
1、5表示JumpDown功能;
-
2表示当前计数器小于DemDebounceCounterJumpDownValue ,所JumpDown功能没有激活;
-
3、4表示JumpUp功能;
-
6表示DemDebounceCounterJumpDownValue ;
-
7表示DemDebounceCounterJumpUpValue;
-
8表示DemDebounceCounterFailedThreshold ;
-
9表示DemDebounceCounterPassedThreshold ;
-
10、12表示故障确认,由于计数器的值达到了fail的限值;
-
11故障恢复,由于计数器的值达到pass的限值;
-
13表示Dem接收的状态为failed,所以故障直接置位;
-
14表示Dem接到的状态为passed,所以故障恢复;
-
15表示DemDebounceCounterIncrementStepSize;
-
16表示DemDebounceCounterDecrementStepSize;
2、基于时间的Debounce策略
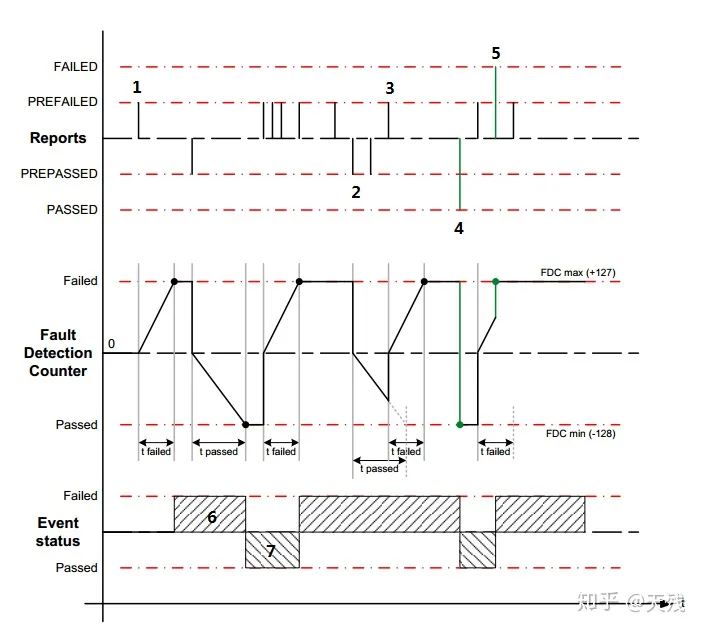
在这种策略下,计数器的初始值为0,其范围为-128~127,当Dem接收到Diagnostic Monitor发送的状态值开始计数,计数器的增长方向由接收到的状态决定,当计数器的值在一定时间达到阈值,完成此次判断,如果在未达到阈值时,Dem接收的状态发生变化,计数器会重新开始计数,并且计数方向也发生转变。
对于基于时间debounce的策略主要配置以下几个参数:
-
1、DebounceTimeBasedTaskTime:该变量定义基本的检测周期;
-
2、DemDebounceTimeFailedThreshold:定义故障状态从prefailed跳转至failed需要多少个DebounceTimeBasedTaskTime周期;
-
3、DemDebounceTimeFailedThreshold:定义故障状态从prepassed跳转至passed需要多少个DebounceTimeBasedTaskTime周期;
-
t failed:表示故障failed需要的时间,该值等于DebounceTimeBasedTaskTime乘以DemDebounceTimeFailedThreshold;
-
t passed:表示故障passed需要的时间,该值等于DebounceTimeBasedTaskTime乘以DemDebounceTimePassedThreshold;
-
1、表示Diagnostic Monitor传至Dem的状态为prefailed;并经过t failed时间故障状态编程failed;
-
2、表示Diagnostic Monitor传至Dem的状态为prepassed;此时计数器重新开始计数;
-
3、由于2时刻开始计数未达到阈值时,Dem接收的状态发生变化,此时计数器开始重新计数,并计数方向发生变化,经过t failed时间后,故障状态编程failed。
-
4、Dem接收的状态为failed,所以故障直接置位了;
-
5、Dem接收的状态为passed,所以故障直接恢复了;
-
6、表示故障已发生;
-
7、表示故障未发生;
本文链接:https://zhuanlan.zhihu.com/p/70216826
这篇关于Autosar DEM DTC的Debounce策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




