本文主要是介绍Elasticsearch的批量bulk 提交 写入的方式会有顺序问题吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Elasticsearch的分布式特性可能会导致写入操作的执行顺序与提交顺序稍有不同。在分布式环境中,Elasticsearch将数据分散到不同的节点上进行存储和处理,因此写入操作的执行顺序可能会受到网络延迟、负载均衡等因素的影响。
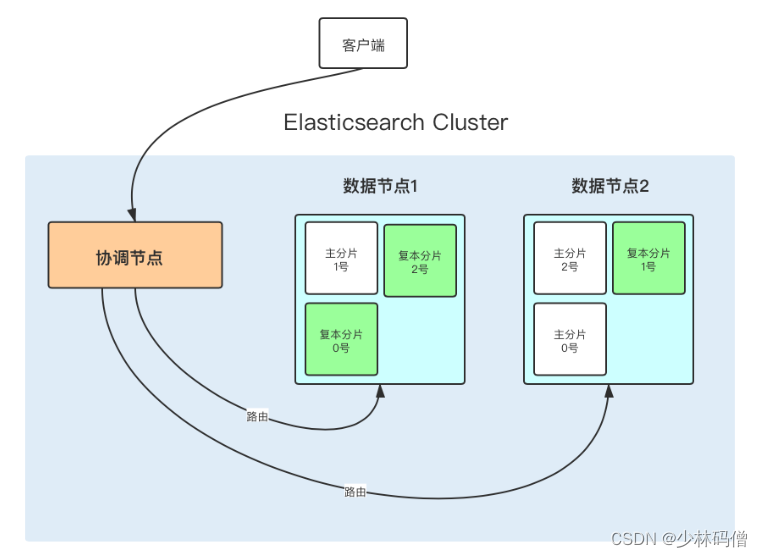
根源在于ES的分布式架构。如上图所示,客户端的命令首先是请求到coordinating node(协调节点),然后协调节点根据命令提供的的路由字段(没有的话默认使用文档id),经过路由算法,找到对应的主shard(分片)。所以真正执行的节点就是shard所在的节点,而每条命令发送到节点上到底哪个先执行是没有保障的,取决于很多因素。比如发送到节点的时间,节点本身的空闲资源情况等。
不过从上面这段解释,我们也可以得出另外一个结论,就是对于同一个文档的操作是有序的。了解这点在一些业务场景下很重要。
虽然处理的顺序不能保证,但是ES会保证响应结果和提交的顺序是一致的。
么是bulk操作
bulk是批量的意思,也就是把原来单个的操作打包好,通过批量的api提交到ES集群。下面是个示例:
单个操作:
PUT my-index/_doc/1
{
"field1": "value1"
}bulk操作:
POST _bulk
{ "index" : { "_in这篇关于Elasticsearch的批量bulk 提交 写入的方式会有顺序问题吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








