本文主要是介绍python弹幕拼脸_完全小白篇-用python爬取B站弹幕(非彩色弹幕以及尝试生成词云图)...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标
爬取B站弹幕(今天是2020/8/31,最近的时间点以下方法肯定行得通)
分析网页
关于B站的弹幕,其实一个系列视频的所有弹幕是可以在其中任何一集视频就能得到的,所以这篇文章的目的并不完全算是python教程,而只是告诉大家怎么找弹幕在哪以及生成词云图。
以“小甲鱼”的python教程系列为例,我们选择打开网页源代码:
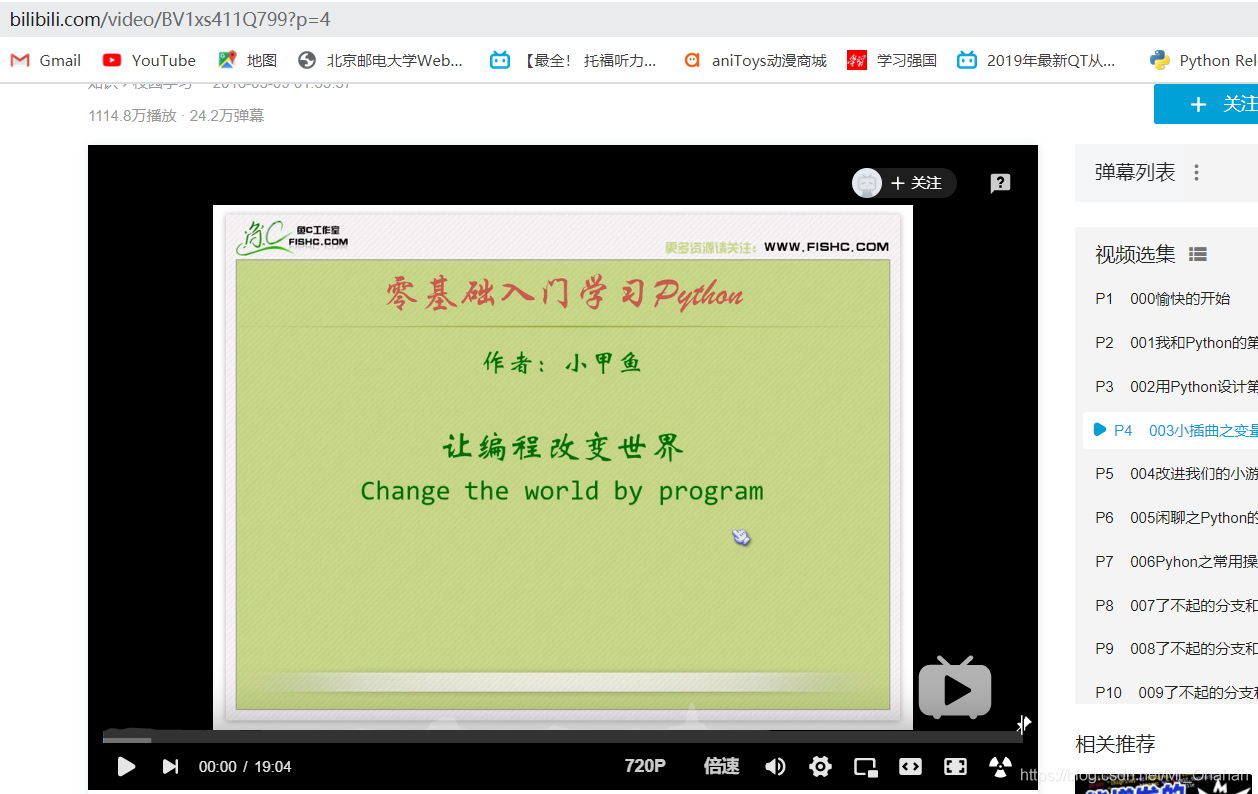
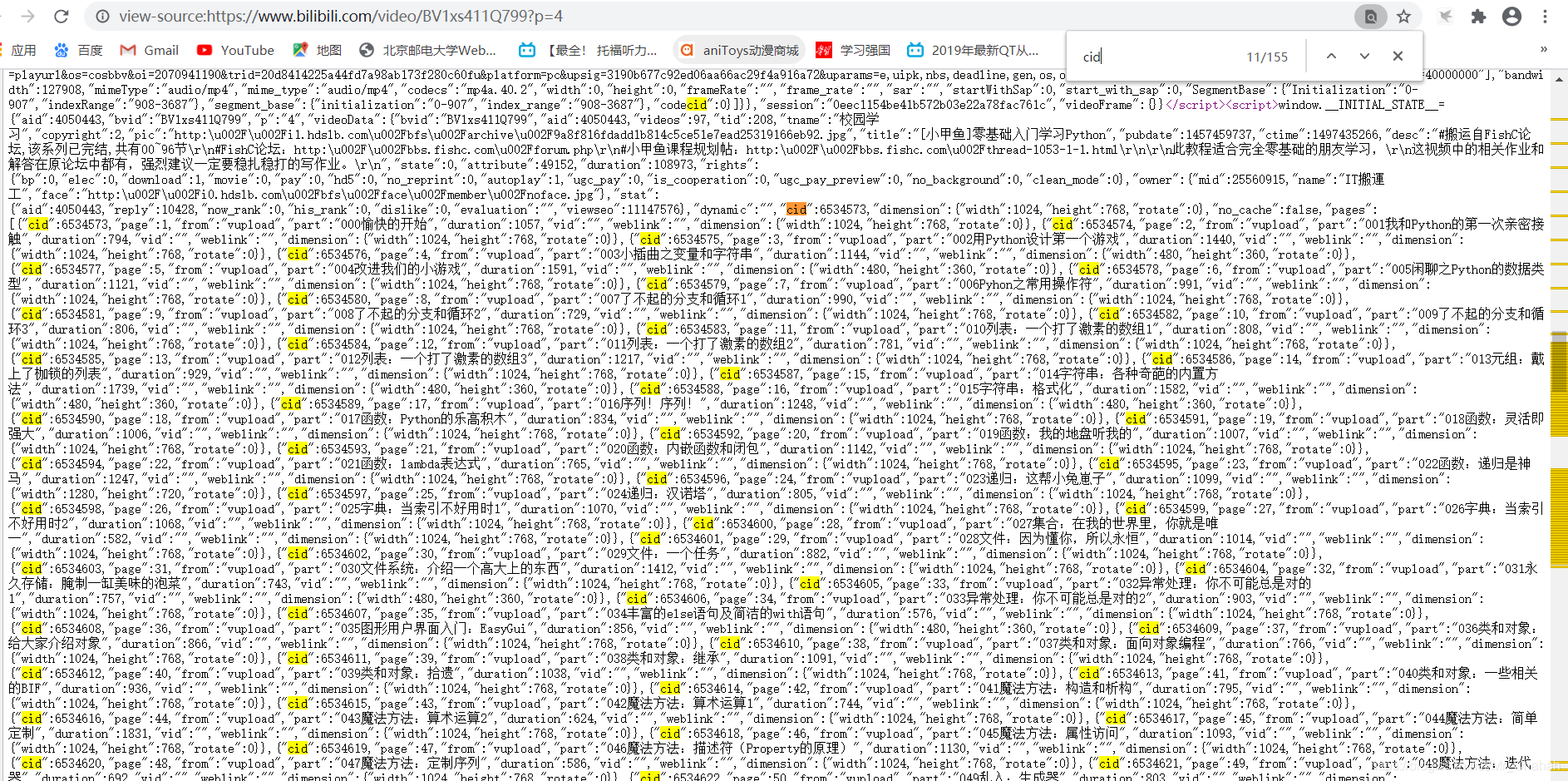
我们再根据cid号打开https://api.bilibili.com/x/v1/dm/list.so?oid=6534573(这是随便挑的一个cid对应的号,验证一下弹幕到底在不在那)
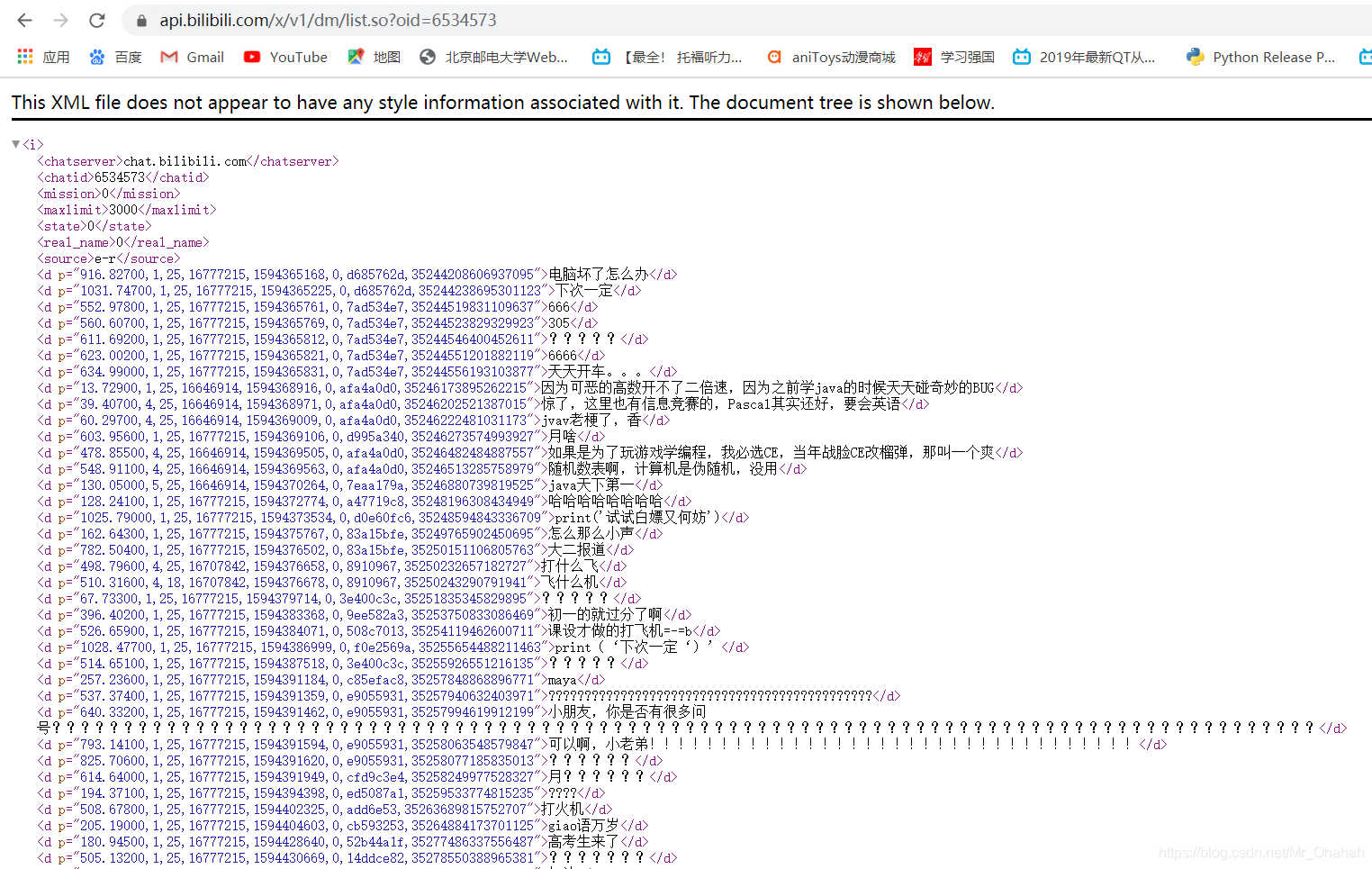
事实上,所有弹幕都是从b站后台另一个网页加载到当前集数的视频中的。我们看这些cid号,每个cid后都有对应的一个编号。上图是p=4第四集的网页源代码,可以发现cid这一块根本不会随着p号改变而改变,所以只需要把这一部分所有有效cid获取到就可以了。
import requests
from bs4 import BeautifulSoup
import re
import json
import os
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.56 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.56"
}
try:
response = requests.get(url = baseurl, headers = head)
if response.status_code==200:
return response.content.decode("utf-8")
except:
print("请求失败")
def main():
print("这是bv号弹幕获取软件")
bv = input("请输入bv号: ")
p = int(input("请输入p号: "))
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
# 获取网页的源代码
req=getHtml(baseurl)
# cid所在的位置是window.__INITIAL_STATE__={}里面,所以要在这里找各个cid号
pattern = r'\'
# result结果得是string
result = re.findall(pattern, req)[0]
match_rule = r'{"cid":(.*?),'
cid = re.findall(match_rule, result)
# 打开弹幕资源位置
baseurl = "https://api.bilibili.com/x/v1/dm/list.so?oid="+str(cid[p-1])
req = getHtml(baseurl)
soup = BeautifulSoup(req,'html.parser')
match_rule = r'(.*?)'
cid = ""
for item in soup.find_all('d'):
item = str(item)
danmu = re.findall(match_rule, item)[0]
cid = cid + danmu + " "
print(cid)
os.system("pause")
if __name__ == "__main__":
main()
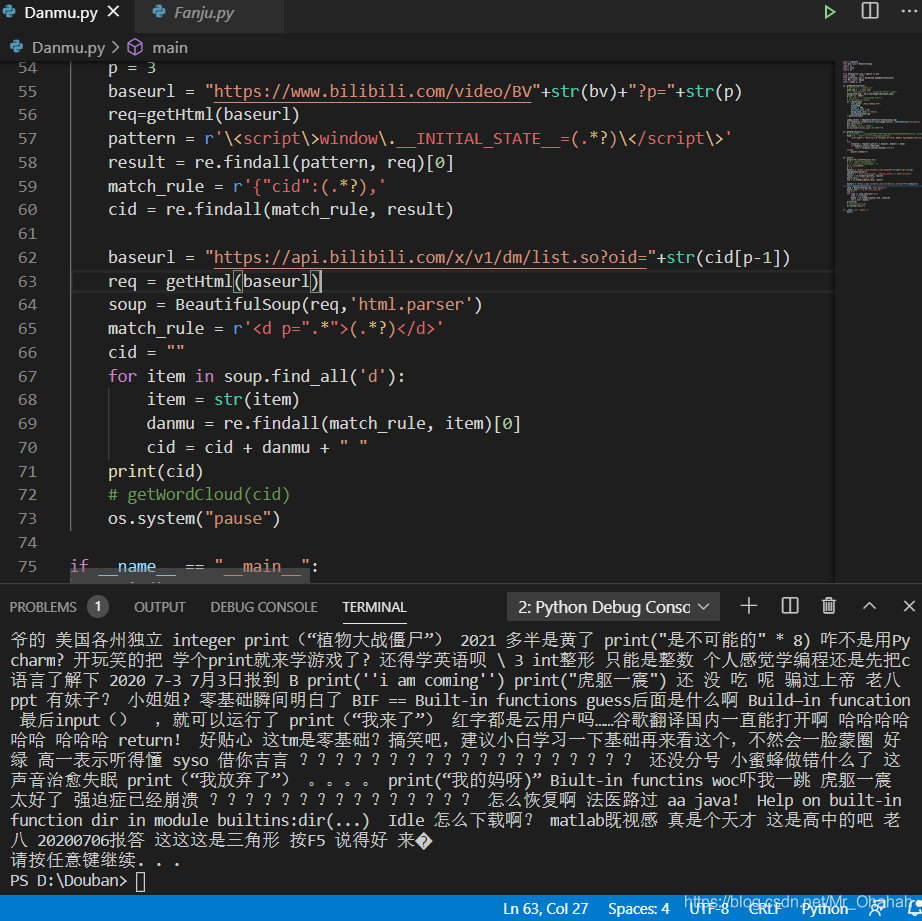
那么,本集视频的所有弹幕的内容就如上啦~
顶部、底部彩色弹幕的获取目前还不是很懂,但是一般采集数据的话都是采集浮动无色弹幕吧,希望对大家有帮助。
另外嘞,如果不想通过网页源代码里找cid的话,也可以通过特殊的request直接获取这些cid。网页视频开始播放的时候,B站的方法是发一个叫pagelist的数据包,如下图:
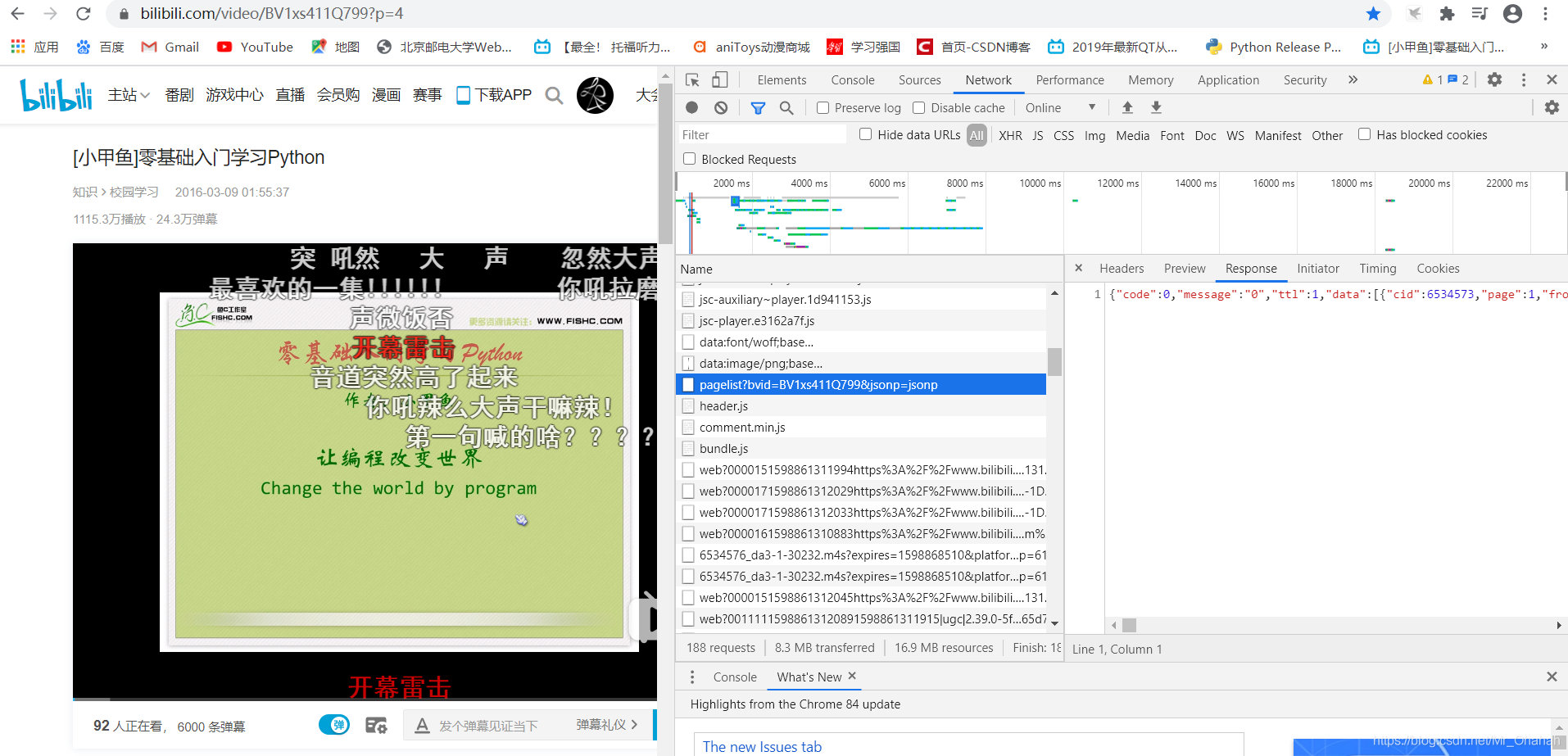 我们可以看到response就是这些cid,所以模仿浏览器写一个和它一模一样的header就可以访问它啦!这一点就不多赘述了
我们可以看到response就是这些cid,所以模仿浏览器写一个和它一模一样的header就可以访问它啦!这一点就不多赘述了
词云图
词云图的生成方法简直不要太多,python的扩展性确实是十分丰富!
为了生成词云图,
from matplotlib import pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
from PIL import Image
import numpy as np
def getWordCloud(text):
# 打开图片文件的路径,并利用机器学习
# numpy分析的话是对一张图片每一块像素的[R,G,B]值进行记录的,到时候生成词云的颜色就由它的分析结果完成
path_img = "./ciyun.jpg"
background_img = np.array(Image.open(path_img))
print("打开成功")
wc = WordCloud(
# 设置词云的字体
font_path="./FZZJ-YZDKJW.TTF",
width=800,
height = 900,
min_font_size = 10,
background_color = "white",
mask=background_img
).generate(text)
image_colors = ImageColorGenerator(background_img)
# 有这几句话的话可以在exe直接打开预览查看
plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
plt.show()
# 保存成图片
wc.to_file("shuchu.jpg")
这里用到的库有matplotlib、wordcloud、PIL以及numpy。所有句子的具体含义见上:
运行结果:
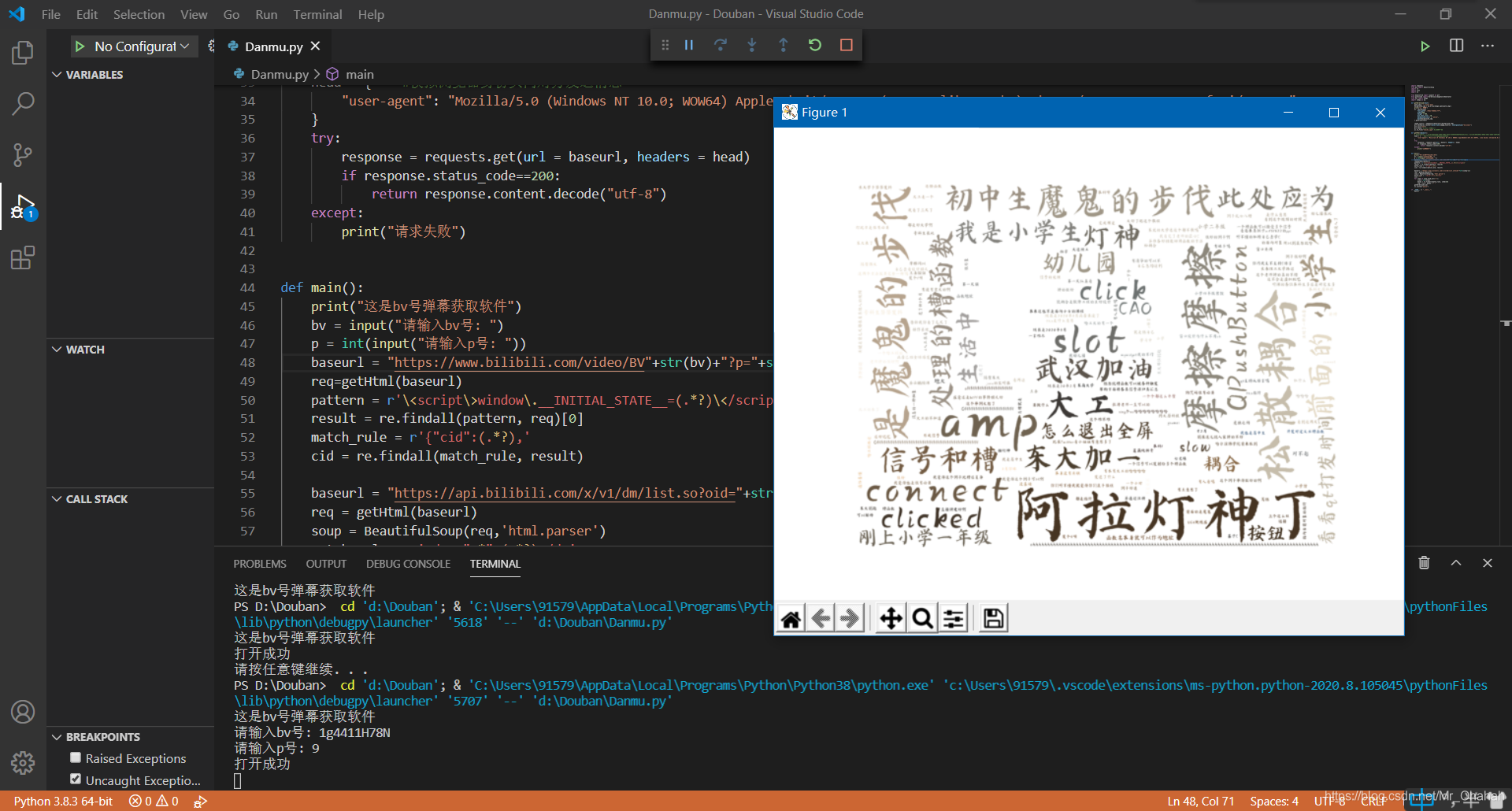
其他的词云库网上有,这里不全介绍了。一般都是用jieba库进行分词的,不过试了试jieba,发现它其实还是针对文件里没有空格间隔的信息比较好用(但是分词结果还是美到不忍直视)。对于获取的弹幕数据我们其实完全也可以存储到sqlite之类的数据库进行记录。总之,词云也好,数据库、柱状图也好,python记录和展示数据的方式多种多样!
其他类视频弹幕的获取
bv号算是普通视频。其实就算是番剧、电影,也是一样的道理,只要有网页源代码就一切ok。大会员特权的番剧当然要大会员的身份,获取特权视频的网页源代码的方式可见完全小白篇-用Python爬取B站大会员番剧集
希望以上对大家有帮助。
本文同步分享在 博客“怡宝的代言人连高波”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
这篇关于python弹幕拼脸_完全小白篇-用python爬取B站弹幕(非彩色弹幕以及尝试生成词云图)...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




