本文主要是介绍ROUGE评价算法学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ROUGE( Recall-Oriented Understudy for Gisting Evaluation) ,在2004年 由 ISI 的Chin-Yew Lin 提出的一种自动摘要评价方法,现被广泛应用于 DUC( Document Understanding Conference )的摘要评测任务中。 ROUGE 基于摘要中 n 元词( n-gram )的共现信息来评价摘要,是一种面向 n 元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标注之一。 ROUGE 准则由一系列的评价方法组成,包括 ROUGE-N(N=1、2、3、4,分别代表基于1元词到4元词的模型) , ROUGE-L,ROUGE-S, ROUGE-W, ROUGE-SU 等。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的 ROUGE 方法。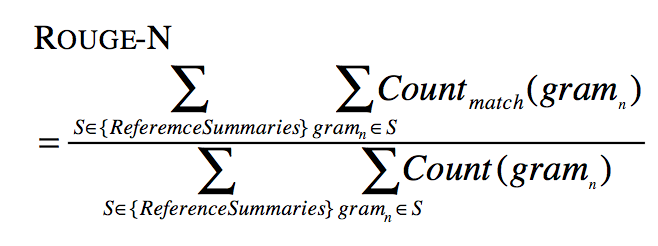
其中,n表示n-gram的长度,{Reference Summaries}表示参考摘要,即事先获得的标准摘要,表示候选摘要和参考摘要中同时出现n-gram的个数,
则表示参考摘要中出现的n-gram个数。不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram
这篇关于ROUGE评价算法学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









