rouge专题

自动评测(ROUGE)及及踩过的坑
最近测试了一个自动摘要的想法,人工看上去还不错。但是没有做评估的话还是心里没底。后来得知,自动摘要用的是一个叫ROUGE的评测体系,包括ROUGE-1、ROUGE-2…ROUGE-N等系列评测方法。 于是去ROUGE官网申请,得到一个下载rouge的网址,但是Google一下发现这个评测远不是那么简单。首先,需要安装,于是接下来就开始了我的踩坑之路 安装是按照该方法来的:http://www.

pyrouge(ROUGE-1.5.5)的安装步骤和使用说明(适用于Linux 系统)
摘要:本文讲解了如何配置和使用文本摘要的评价指标ROUGE(linux 系统)。 ✅ NLP 研 1 选手的学习笔记 简介:小王,NPU,2023级,计算机技术 研究方向:摘要生成、大语言模型生成 文章目录 一、为啥要写这篇博客?二、安装过程:step1:检查 `perl` 版本step2:安装 `XML::Parser`step3: 安装 `XML::RegExp`

【名词解释】ImageCaption任务中的CIDEr、n-gram、TF-IDF、BLEU、METEOR、ROUGE 分别是什么?它们是怎样计算的?
CIDEr CIDEr(Consensus-based Image Description Evaluation)是一种用于自动评估图像描述(image captioning)任务性能的指标。它主要通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量。CIDEr的独特之处在于它考虑了人类对图像描述的共识,尝试捕捉描述的自然性和信息量。 CIDEr的计算过程 CIDEr的计算可以分
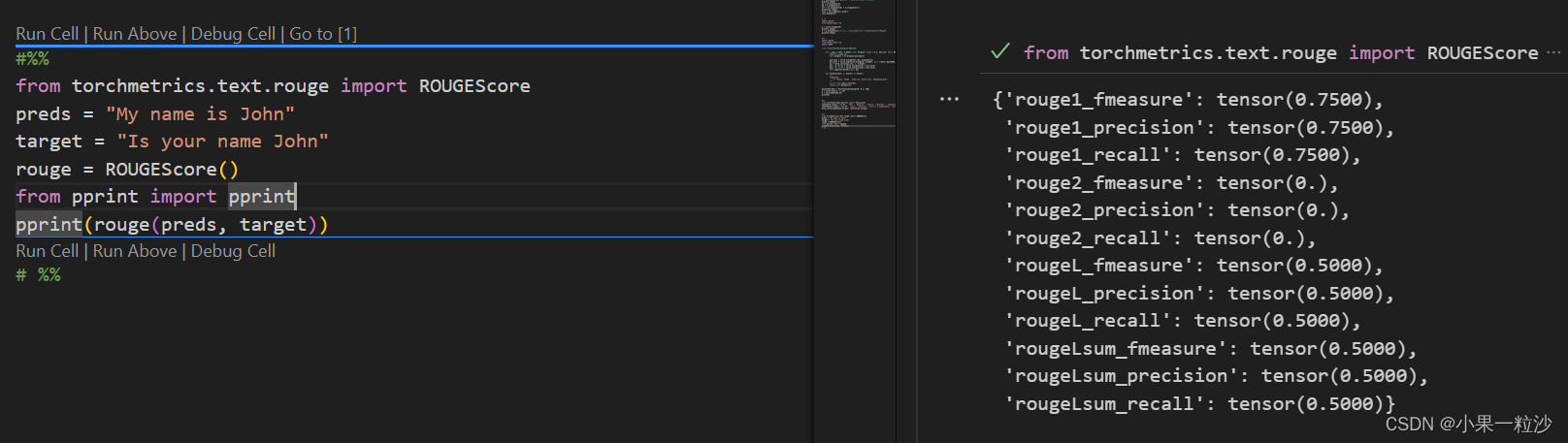
文本生成评估指标简单介绍BLEU+ROUGE+Perplexity+Meteor 代码实现
以下指标主要针对两种:机器翻译和文本生成(文章生成),这里的文本生成并非是总结摘要那类文本生成,仅仅是针对生成句子/词的评价。 首先介绍BLEU,ROUGE, 以及BLEU的改进版本METEOR;后半部分介绍PPL(简单介绍,主要是关于交叉熵的幂,至于这里的为什么要求平均,是因为我们想要计算在一个n-gram的n中,平均每个单词出现需要尝试的次数。 机器翻译(Machine Translatio
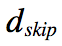
学习笔记———《自动文档摘要评价方法---Edmundson和ROUGE》
本人最近在做一个自动文档摘要相关的项目,研究了一下目前业界的一些评价方法,阅读了Chin-Yew Lin的《ROUGE: A Package for Automatic Evaluation of Summaries》的paper,也对应看了其他朋友整理的笔记,特整理此笔记供大家参考! 自动文档摘要评价方法大致分为两类: (1)内部评价方法(Intrinsic Methods)
自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S 评测指标
目录 前言 关于Rouge Rouge-1、Rouge-2、Rouge-N Rouge-L Rouge-L的改进版 — Rouge-W Rouge-S 多参考摘要的情况 前言 最近在看自动文摘的论文,之前对Rouge评测略有了解,为了更好的理解Rouge评测原理,查了些资料,并简单总结。 关于Rouge Rouge(Recall-Oriented Understud

【深度学习】序列生成模型(六):评价方法计算实例:计算ROUGE-N得分【理论到程序】
文章目录 一、BLEU-N得分(Bilingual Evaluation Understudy)二、ROUGE-N得分(Recall-Oriented Understudy for Gisting Evaluation)1. 定义2. 计算N=1N=2 3. 程序 给定一个生成序列“The cat sat on the mat”和两个参考序列“The cat is on t
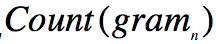
ROUGE评价算法学习
ROUGE( Recall-Oriented Understudy for Gisting Evaluation) ,在2004年 由 ISI 的Chin-Yew Lin 提出的一种自动摘要评价方法,现被广泛应用于 DUC( Document Understanding Conference )的摘要评测任务中。 ROUGE 基于摘要中 n 元词( n-

文本摘要评价指标 - ROUGE 附代码实现
ROUGE用于评判摘要质量 1. ROUGE-N 这里的N指的是N-gram, 即 将 机器生成的句子 与 标准句子 均进行N-gram拆分, 然后计算两者的共现(相同)的个数。 可从precision、recall两个角度进行评估: 2. ROUGE-L、ROUGE-W ROUGE-L 计算最长公共子序列的重合情况,适合用于短摘要文本评估; ROUGE-W 在L的基础上,考虑了连续
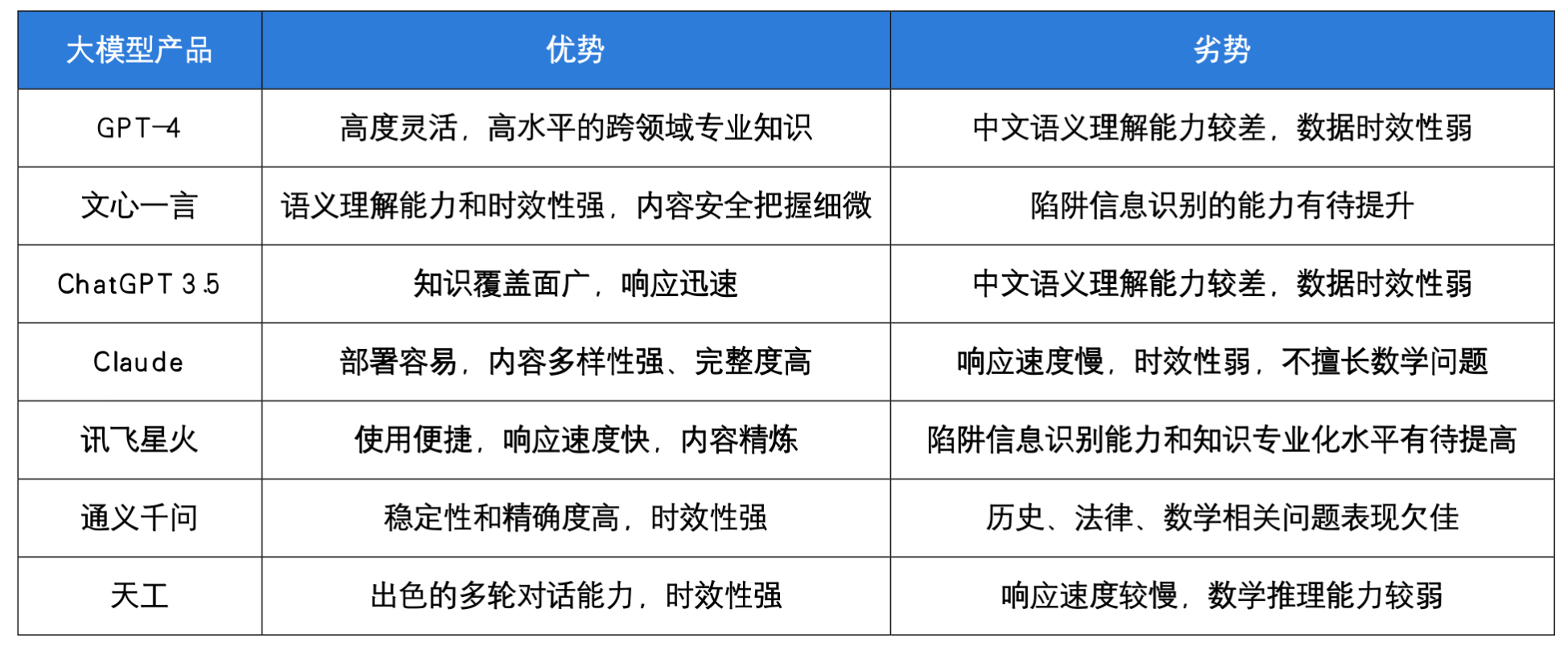
【LLM评估篇】Ceval | rouge | MMLU benchmarks
note 一些大模型的评估基准benchmark:多轮:MTBench关注评估:agent bench长文本评估:longbench,longeval工具调用评估:toolbench安全评估:cvalue,safetyprompt等 文章目录 note常见评测benchmarkMMLUSuperCLUE:中文通用大模型综合性评测基准知识评估:C-EvalC-EvalGSM8KBBH 工具