本文主要是介绍第P7周:咖啡豆识别(VGG-16复现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客**
>- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**一、前期工作
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2. 导入数据
import os,PIL,random,pathlibdata_dir = './7-data/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
classeNames
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸# transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transform = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder("./7-data/",transform=train_transforms)
total_data
3. 划分数据集
二、手动搭建VGG-16模型
VGG-16结构说明:
●13个卷积层(Convolutional Layer),分别用blockX_convX表示
●3个全连接层(Fully connected Layer),分别用fcX与predictions表示
●5个池化层(Pool layer),分别用blockX_pool表示
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
这里,我制作了一个视频来展示VGG-16的传播过程

0:00/0:22
倍速



VGG-16网络动画展示
FC7
FE8
FC6
7*7*512
1*1*512
1*1*1000
1*1*512
CONV5
CONV4
14*14*512
CONV3
28*28*512
CONV2
56*56*256
112*112*128
CONVOLUTION+RELU
K同学啊制作
MAX POOLING
CONVI
百度/谷歌/微信搜索:K同学啊
224*224*64
FULLY CONNECTED+RELU

1. 搭建模型
2. 查看模型详情
三、 训练模型
1. 编写训练函数
2. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
3. 正式训练
model.train()、model.eval()训练营往期文章中有详细的介绍。
📌如果将优化器换成 SGD 会发生什么呢?请自行探索接下来发生的诡异事件的原因。
四、 结果可视化
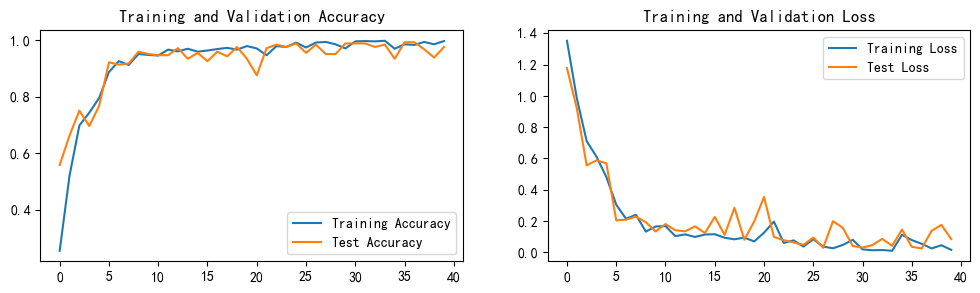
1. Loss与Accuracy图
TRAINING AND VALIDATION ACCURACY
TRAINING AND
VALIDATION LOSS
1.4
1.0
TRAINING LOSS
1.2
TEST LOSS
1.0
0.8
0.8
0.6
0.6
0.4
0.4
0.2
TRAINING ACCURACY
TEST ACCURACY
0.0
75
35
15
35
25
20
40
30
40
30
2. 指定图片进行预测
Python复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_,pred = torch.max(output,1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
Python复制代码
1
2
3
4
5
# 预测训练集中的某张照片
predict_one_image(image_path='./7-data/Dark/dark (1).png',
model=model,
transform=train_transforms,
classes=classes)
Plain Text复制代码
1
预测结果是:Dark
25
50
75
100
125
150
175
200
50
100
150
200

3. 模型评估
Python复制代码
1
2
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
Python复制代码
1
epoch_test_acc, epoch_test_loss
Plain Text复制代码
1
(0.9916666666666667, 0.035762640996836126)
Python复制代码
1
2
# 查看是否与我们记录的最高准确率一致
epoch_test_acc
Plain Text复制代码
1
0.9916666666666667
这篇关于第P7周:咖啡豆识别(VGG-16复现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!