本文主要是介绍redis:一、面试题常见分类+缓存穿透的定义、解决方案、布隆过滤器的原理和误判现象、面试回答模板,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
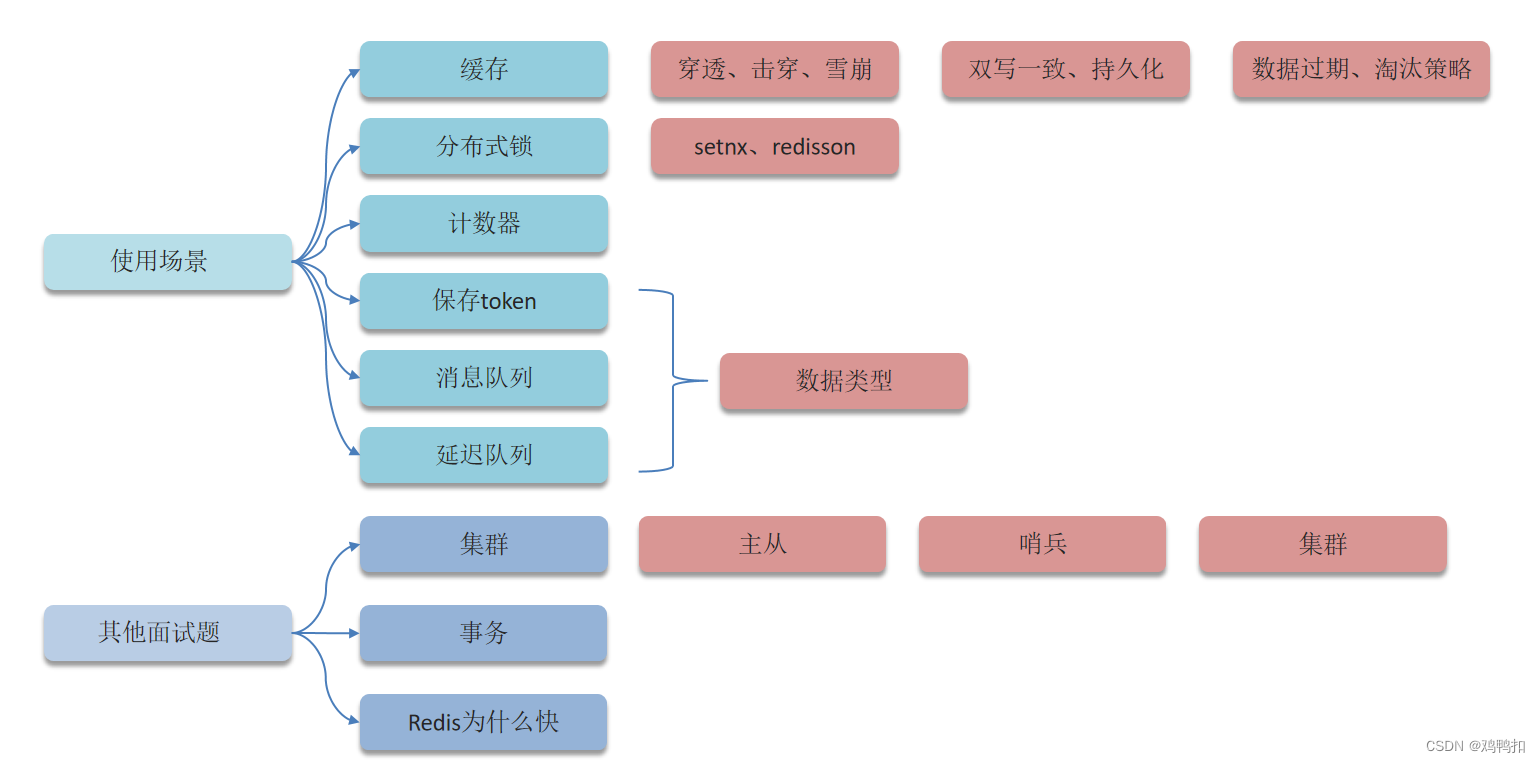
redis面试题常见分类
缓存穿透
定义
缓存穿透是一种现象,引发这种现象的原因大概率是遭到了恶意攻击。具体就是查询一个一定不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致这个数据的每次请求都需要查DB,数据库压力很大,从而挂掉。

解决方案一:缓存空数据
我们缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存。
优点:简单
缺点:消耗内存,可能会发生缓存和数据库不一致的问题。
为什么可能发生缓存和数据库不一致的问题。因为一开始数据库中没有该数据,redis就会缓存空结果。但是后来我们在数据库中插入该数据时,缓存中依旧是空结果,那么就不一致了。
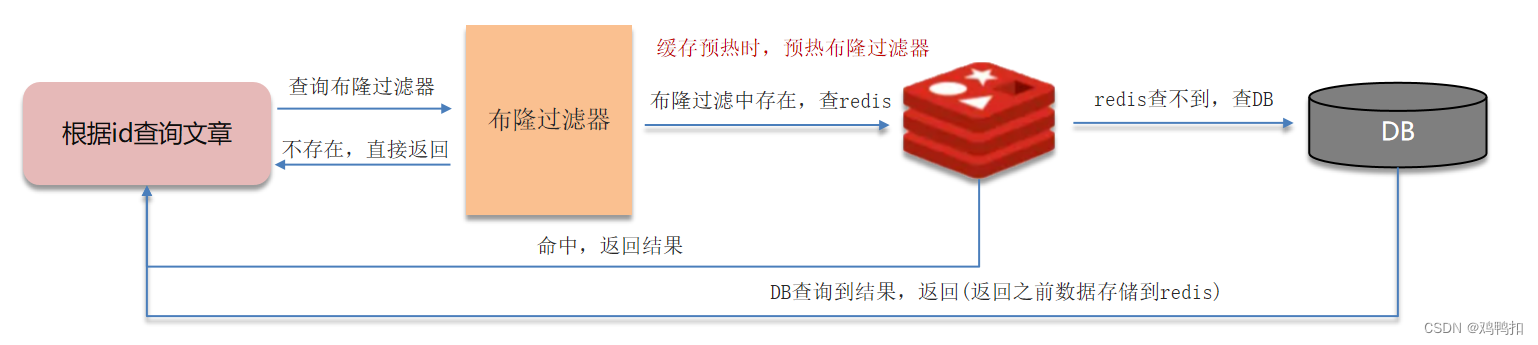
解决方案二:布隆过滤器
我们可以在缓存预热时,创建一个布隆过滤器,它的作用就是判断一个数据是否存在。每次查询前先查询布隆过滤器,来判断这个数据是否一定存在,如果存在,则查询redis以及之后的DB层。如果不存在则直接返回。
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判
布隆过滤器定义、存储/查找数据
布隆过滤器实际上就是一个bitmap(位图),相当于是一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1,初始化全为0。
存储数据就是将数据的值经过x个哈希函数后获取x个哈希值,然后将数组对应位置改为1.
查询数据就是用相同的x个哈希函数获取x个哈希值,然后判断数组对应位置是否都为1.

布隆过滤器误判
通过布隆过滤器的原理,我们可以发现,如果一个数在过滤器中找不到,那么它一定不存在。但是如果一个数能在过滤器中找到,也不意味着它一定存在。因为过滤器存在误判现象。
譬如下图,id1和id2在数组上的下标覆盖了id3在数组上的下标。存储了id1和id2,就会让id3查询所对应的数组下标位置也变为1。实际上id3是不存在的,但是会被误判为存在。
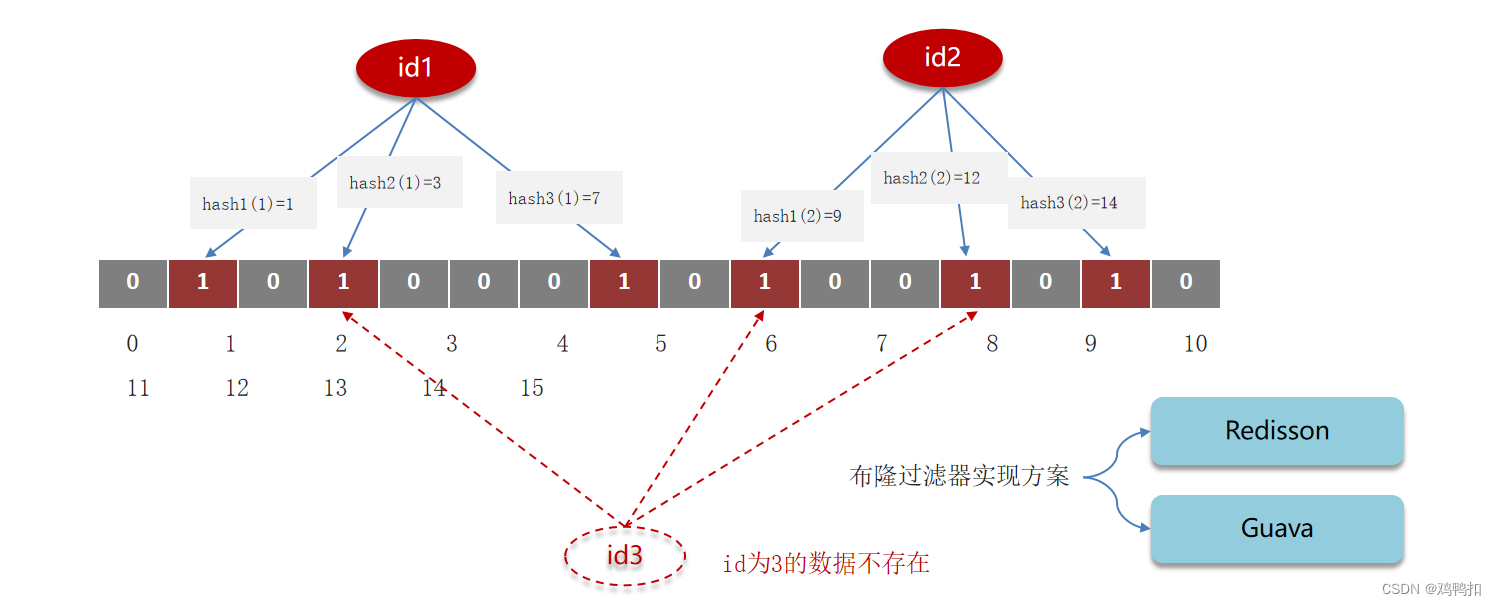
误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗。
一般我们将误判率设置在5%,比较合理地兼顾内存和误判率。
测试误判率和初始化布隆过滤器代码(不用看,仅供个人存档用)
/*测试误判率*/private static int getData(RBloomFilter<String> bloomFilter, int size){int count=0;for(int x=size; x<size*2;x++){if(bloomFilter.contains("add"+x)){count++;}}return count;
}/*初始化数据*/private static void initData(RBloomFilter<String> bloomFilter, int size{bloomFilter.tryInit(size, 0.05);for(int x=0;x<size;x++){bloomFilter.add("add"+x);}System.out.println("初始化完成……");}
面试回答模板
什么是缓存穿透 ,怎么解决 ?
背熟以下回答,大概用时1分半。
缓存穿透是一种现象,引发这种现象的原因大概率是遭到了恶意攻击。具体就是查询一个一定不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致这个数据的每次请求都需要查DB,如果同时并发多个请求的话。数据库压力就会很大,从而挂掉。
解决方案的话一般有两种,第一种是直接缓存空数据。这种方案实现简单,但是可能比较消耗内存,而且有可能发生缓存和数据库数据不一致的问题。我们通常选择第二种解决方案,就是布隆过滤器。布隆过滤器实际上就是一个bitmap(位图),相当于是一个以(bit)位为单位的数组,数组中只能存储0或1,初始时全为0。存储数据就是将数据的值经过x个哈希函数后获取x个哈希值,然后将数组对应位置改为1.查询数据也一样。我们可以在缓存预热时,创建一个布隆过滤器,它的作用就是判断一个数据是否存在。每次查询前先查询布隆过滤器,来判断这个数据是否一定存在,如果存在,则查询redis以及之后的DB层。如果不存在则直接返回。
本篇所有图片来自于黑马程序员。
这篇关于redis:一、面试题常见分类+缓存穿透的定义、解决方案、布隆过滤器的原理和误判现象、面试回答模板的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




