本文主要是介绍人脸关键点检测3——DCNN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
######《Deep Convolutional Network Cascade for Facial Point Detection》
2013年,通过3级卷积神经网络来估计人脸关键点(5点),属于级联回归方法。
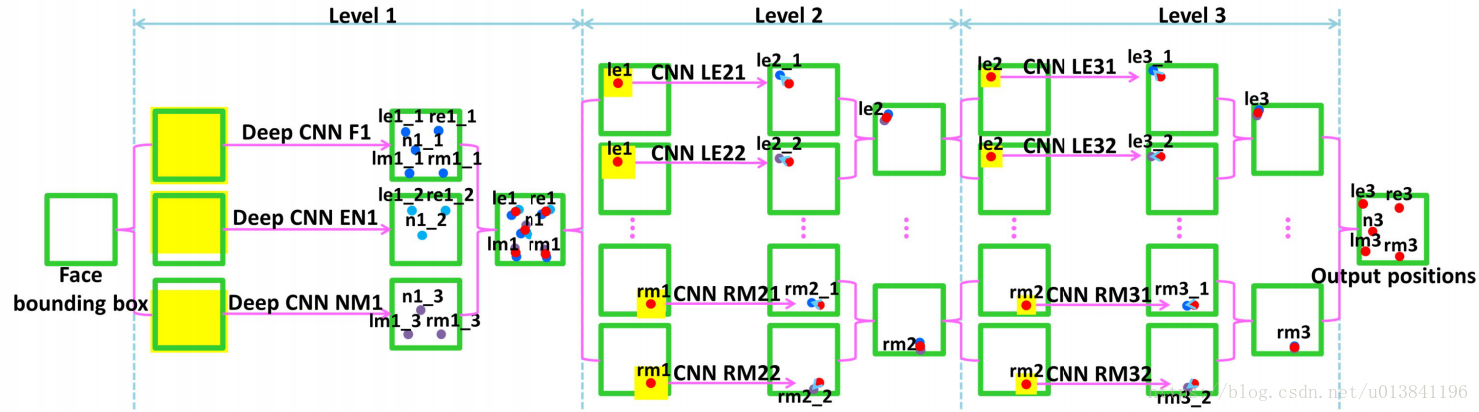
级联的卷积网络结构:
Level1,采用了3个CNN,输入区域分别为整张脸(F1),眼睛和鼻子(EN1),鼻子和嘴(EM1)。F1输入尺寸为3939,输出5个关键点的坐标;EN1输入尺寸为3139,输出是3个关键点的坐标;NM1输入尺寸为3139,输出是3个关键点。Level-1的输出是由三个CNN输出取平均得到,来较少变动。
Level-2,由10个CNN构成,输入尺寸均为1515,每两个组成一对,一对CNN对一个关键点进行预测,预测结果同样是采取平均。
Level-3与Level-2一样,由10个CNN构成,输入尺寸均为15*15,每两个组成一对。Level-2和Level-3是对Level-1得到的粗定位进行微调,得到精细的关键点定位。
Level-1之所以比Level-2和Level-3的输入要大,是因为作者认为,由于人脸检测器的原因,边界框的相对位置可能会在大范围内变化,再加上面部姿态的变化,最终导致输入图像的多样性,因此在Level-1应该需要有足够大的输入尺寸。Level-1与Level-2和Level-3还有一点不同之处在于,Level-1采用的是局部权值共享(Locally Sharing Weights),作者认为传统的全局权值共享是考虑到,某一特征可能在图像中任何位置出现,所以采用全局权值共享。然而,对于类似人脸这样具有固定空间结构的图像而言,全局权值共享就不奏效了。因为眼睛就是在上面,鼻子就是在中间,嘴巴就是在下面的。作者通过实验证明了局部权值共享给网络带来性能提升。
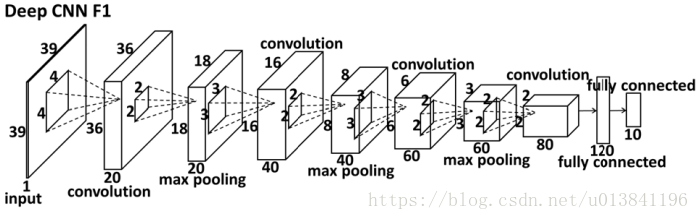
网络结构:
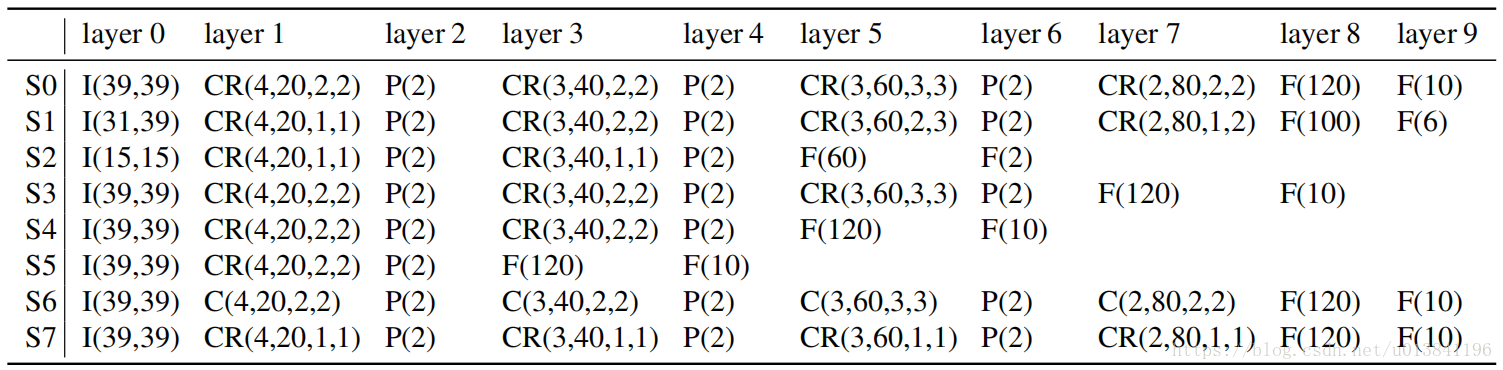
注:Level1中F1采用S0,EN1和NM1采用S2;Level2和Level3全部采用S2。
多级回归:
我们发现几种有效的方法结合多重卷积网络。第一个是多级回归。脸部bounding box是仅有的先验知识。一个面部点对bounding box的相对位置可能分部在一个很大的范围,这是由于脸部检测器的不稳定性和姿态的多样性。所以第一级的输入区域应该是足够大来覆盖所有可能的预测。但大的输入区域是主要的不准确原因,因为不相关的区域可能退化网络最后的输出。第一级的网络输出为接下来的检测提供了一个强大的先验知识。真实的脸部点伪装分布在第一级预测的一个小领域内。所以第二级的检测可以在一个小范围内完成。但没有上下文信息,局部区域的表现是不可靠的。为了避免发散,我们不能级联太多层,或者过多信任接下来的层。这些网络只能在一个小范围内调整初始预测。
为了更好的提高检测精度和可靠性,我们提出了每一级都有多个网络共同地预测每一个点。这些网络的不同在于输入区域。最后的预测可以用公式表达如下:
对n-级级联,在i级有li个预测。第一级的预测是绝对位置,接下来的级的预测是调整。
训练:
第一级,训练和边界相关的小块,通过小的变换和旋转增强数据。在接下来的级中,我们训练以ground truth 位置随机变换得到的位置为中心的小块,第二级在水平和竖直最大的shift为0.05,第三级为0.02,这个距离是以bounding box的大小为基准。参数通过随机初始化和随机梯度下降法得到。
测试:
DCNN采用级联回归的思想,从粗到精的逐步得到精确的关键点位置,不仅设计了三级级联的卷积神经网络,还引入局部权值共享机制,从而提升网络的定位性能。最终在数据集BioID和LFPW上均获得当时最优结果。速度方面,采用3.3GHz的CPU,每0.12秒检测一张图片的5个关键点。
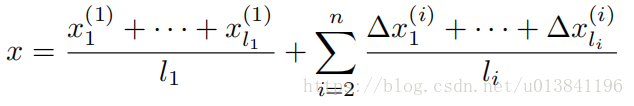

注:博众家之所长,集群英之荟萃。

这篇关于人脸关键点检测3——DCNN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)


