本文主要是介绍最新科研成果:在钻石中存储多比特数据,实现25GB数据密度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,纽约城市大学(CUNY)的研究人员已经成功地利用钻石原子结构中的小型氮缺陷作为“颜色中心”来写入数据进行存储(然后是检索)。这项发表在《自然·纳米技术》上的技术允许通过将数据编码为多个光频率(即颜色)将多个字节的数据写入相同的氮缺陷中——这可以在不混淆信息内容的情况下完成。
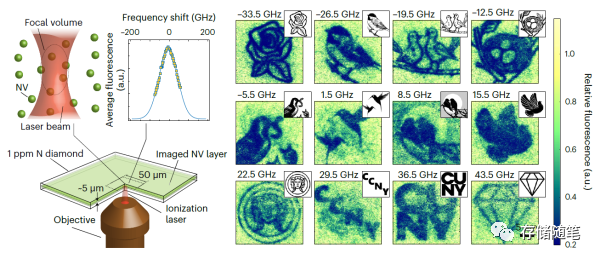
该技术可以将多个数据位存储在钻石的缺陷中,通过在不同光频率上编码实现每平方英寸25GB的数据密度。这项技术利用了钻石中的氮缺陷,这些缺陷可以作为颜色中心,通过精确控制它们的电荷来存储信息。研究人员使用窄带激光和低温条件来非常精确地控制这些颜色中心的电荷,并且可以在单个原子级别进行写入和读取。
他们展示了如何在同一氮缺陷中使用每种颜色的适当衍射限制打印多种颜色,这意味着可以根据对原子进行单独编程的颜色数量构建尽可能多的位。
这项技术的一个独特之处在于它是可逆的,可以无限次地写入、擦除和重写。此外,它还规避了衍射限制,可以通过利用距离小于衍射极限的颜色中心之间存在的轻微颜色(波长)变化来实现这一点。
这项研究对于提高光学数据存储容量具有重要的意义,尤其是在需要高容量存储的计算应用方面。虽然目前还需要低温冷却来操作这些颜色中心,但研究人员有信心他们的技术可以在室温下运行,并且有一天可能会导致在更低的能量成本下提高存储容量。
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
SSD在AI发展中的关键作用:从高速缓存到数据湖
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
SSD数据在写入NAND之前为何要随机化?
-
深度剖析:DMA对PCIe数据传输性能的影响
-
深入解析SSD Wear Leveling磨损均衡技术:如何让你的硬盘更长寿?
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
如何通过优化Read-Retry机制降低SSD读延迟?
-
关于硬盘质量大数据分析的思考
-
存储系统性能优化中IOMMU的作用是什么?
-
全景解析SSD IO QoS性能优化
-
NVMe IO数据传输如何选择PRP or SGL?
-
浅析nvme原子写的应用场景
-
多维度深入剖析QLC SSD硬件延迟的来源
-
浅析PCIe链路LTSSM状态机
-
浅析Relaxed Ordering对PCIe系统稳定性的影响
-
实战篇|浅析MPS对PCIe系统稳定性的影响
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!
这篇关于最新科研成果:在钻石中存储多比特数据,实现25GB数据密度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





