本文主要是介绍爬虫模拟古诗文网登录(识别验证码、模拟登录)2023/1/12可用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全部代码如下,注释交代了具体步骤
import requests
from lxml import etree
import ddddocr# 1、获取验证码
session = requests.Session()
login_url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
login_page_text = session.get(url=login_url, headers=headers).text
tree = etree.HTML(login_page_text)
code_img_src = "https://so.gushiwen.cn" + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 2、将验证码图片保存到本地
img_data = session.get(url=code_img_src, headers=headers).content
with open('./codeImg.jpg', 'wb') as fp:fp.write(img_data)
# 3、利用ddddocr库进行识别验证码
ocr = ddddocr.DdddOcr()
with open('./codeImg.jpg', 'rb') as fp:img_bytes = fp.read()
res = ocr.classification(img_bytes)
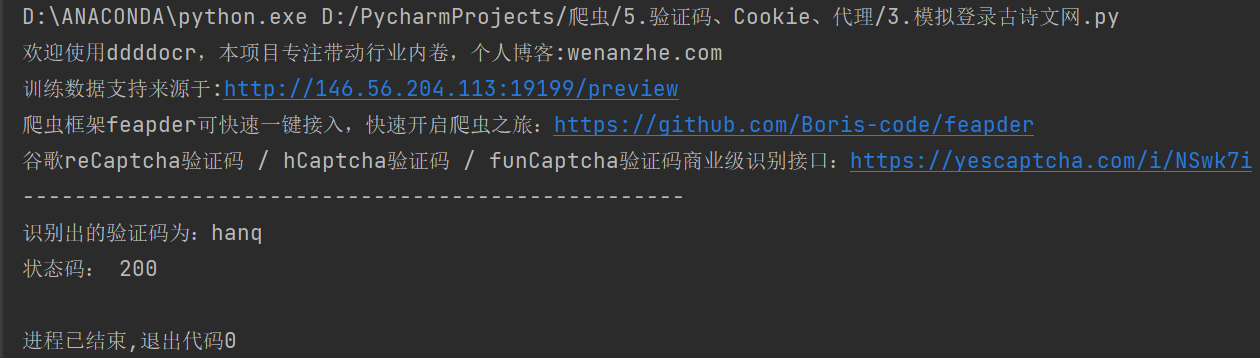
print("---------------------------------------------------")
print('识别出的验证码为:' + res)
# 4、进行模拟登录
viewstate = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0] # 这个参数是动态的,全局搜索在源码中找到
data = {'__VIEWSTATE': viewstate,'__VIEWSTATEGENERATOR': ' C93BE1AE','from': 'http://so.gushiwen.cn/user/collect.aspx','email': '************', # 你的古诗文网账号'pwd': '*********', # 你的古诗文网密码'code': res,'denglu': '登录',
}
response = session.post(url=login_url, data=data, headers=headers)
print("状态码:", response.status_code)
# 5、保存成功登录后的个人信息界面的源码
response_text = response.text
with open('./古诗文网模拟登录.html', 'w', encoding='utf-8') as fp:fp.write(response_text)我的运行结果:
这篇关于爬虫模拟古诗文网登录(识别验证码、模拟登录)2023/1/12可用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








